For me, that's the really neat thing about these new Keras features: because they're all based on the same abstractions, they all work smoothly together. What you've learned on one problem can be easily reinvested in the next problem.
@fchollet
-
Using Pretrained BERT Embeddings with Structured Data Features
By
–
So if you have a set of structured data features that you want to process, and it includes a text paragraph, you just need 2 additional lines to say "I want to embed this paragraph with a pretrained Bert and concatenate the embeddings to the rest of my encoded features"
-
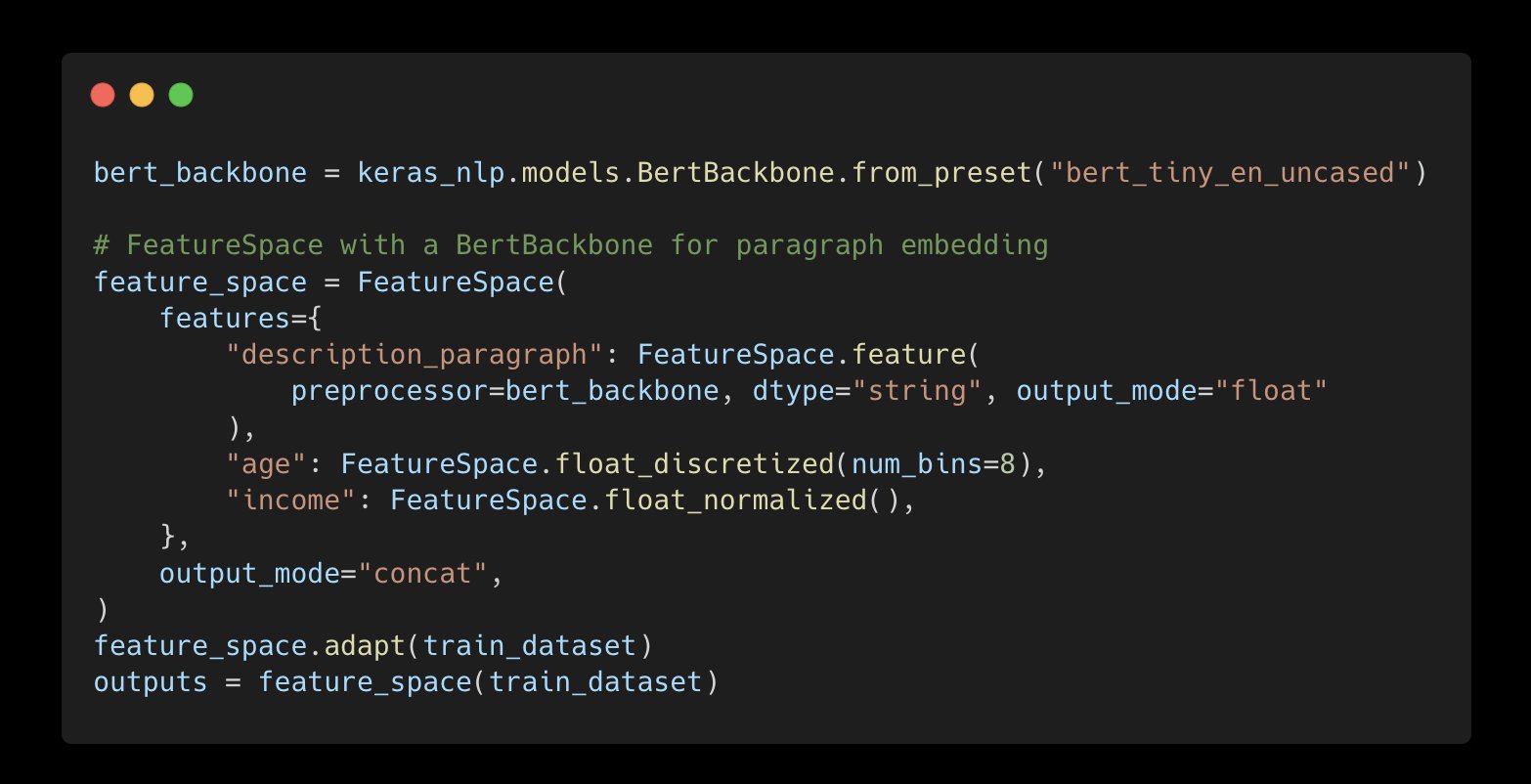
BertBackbone and FeatureSpace Integration for Text and Structured Data
By
–
Take the new BertBackone in KerasNLP. You can use it to embed a text paragraph in 2 lines of code. And take the new FeatureSpace utility for structured data processing… You can use them together — if your data includes a text paragraph, you can use BertBackone *in* the FS
-

Keras Downloads Reach Record Highs After Eight Years
By
–
Keras downloads — making new highs regularly for nearly 8 years
-
TensorFlow Usage Exceeds PyTorch by 1.5x According to Metrics
By
–
Every metric (downloads, StackOverflow, GCP usage, etc.) + large-scale user surveys (the SO survey, the Kaggle survey) shows TF/Keras usage is >1.5x that of PT. Just saying. LeCun loves to send press releases to journalists saying "TF is dead!" but that doesn't make it true.
-
Keras reaches record single-day download count of 447,000
By
–
On Thursday, Keras had its highest single-day download count so far (447,000 downloads in a day).
-
Keras Reaches 2.5 Million Users After 8 Years of Growth
By
–
Kind of insane that I've been working on Keras for nearly 8 years and it's still growing at ~30% per year. Never thought it would ever get to 1M users, much less the ~2.5M users we have currently (and growing)
-
AI Progress Hype: Gap Between Expectations and Actual Capabilities
By
–
Recall that circa 2015-2016 AI was about to replace half of all jobs, including all drivers, most doctors, etc. People's perception of AI progress is rarely grounded in actual capabilities — people are always projecting their hopes on the latest hype trend (e.g. deep RL)
-
Deep Learning’s Economic Impact Falls Short of Expectations
By
–
There's a parallel to deep learning itself — the economic impact of the tech has been ~10% of what folks expected ~8 years ago, and being a provider of deep learning APIs / models has been a rather lousy business. Although individual engineers have done very well for themselves
-
Deep Learning Models as Knowledge Retrievers and Action Routers
By
–
Yes, once DL models are used not as raw knowledge stores (which doesn't make a lot of sense) but as knowledge retrievers and action routers, they will be as up-to-date as the underlying database. https://
t.co/yHN13PyJeA