If your benchmark relies on a static dataset or sampling from a static distribution densely known at training time, then it is fundamentally measuring memorization/retrieval. Which might be fine if you're looking for a retrieval benchmark! But don't confuse it with intelligence.
@fchollet
-
Agentic coding requires explicit API contracts and docstrings
By
–
Agentic coding forces you to design clean interfaces and document them well. An agent cannot read the implicit mental model shared by your engineering team, it can only read your API contracts and docstrings.
-
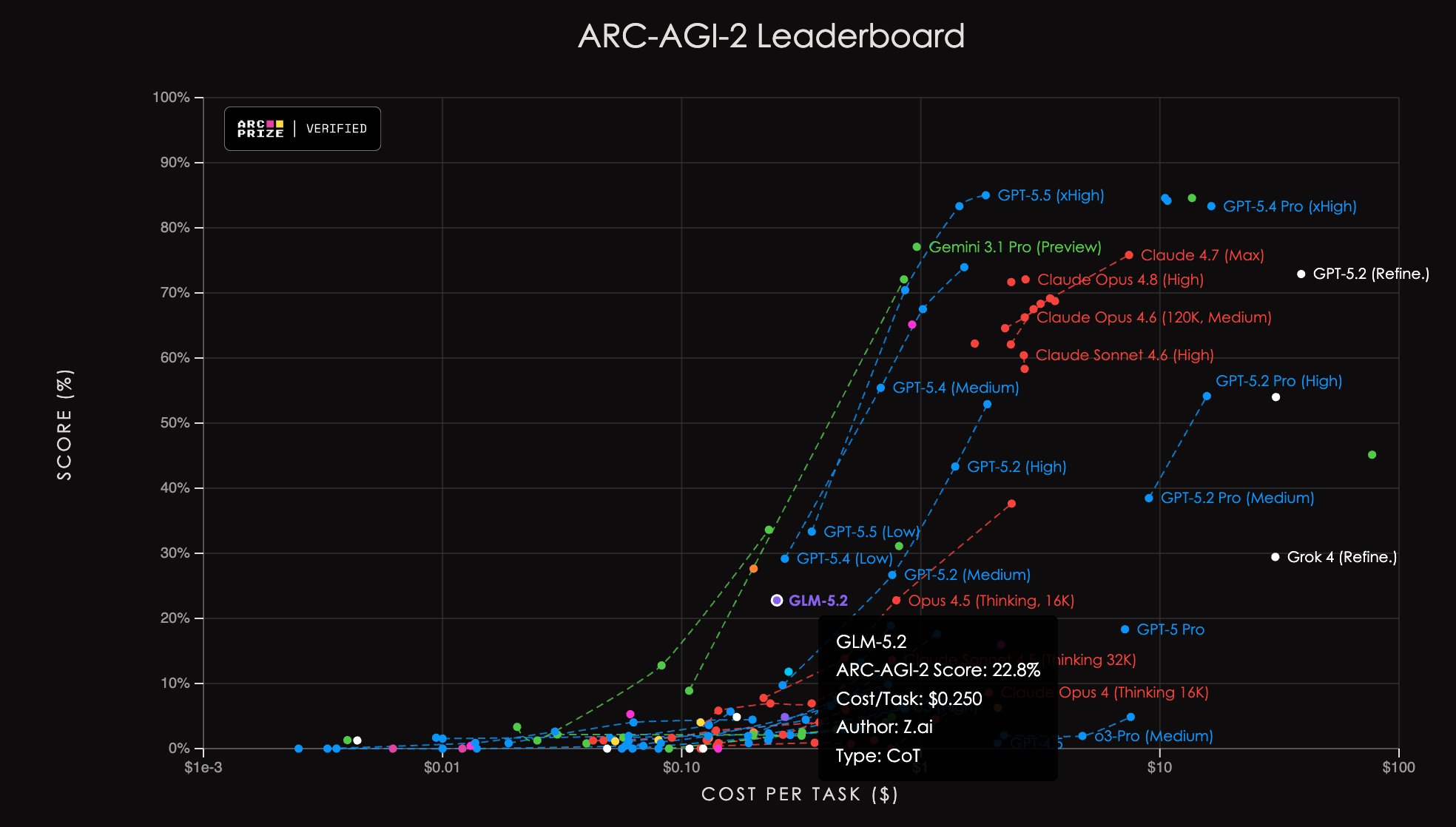
Best ARC-AGI-2 performance achieved by open-source model
By
–
This is the best ARC-AGI-2 performance to date achieved by an open-source model.
-
The mechanical accumulation of useless code in agentic coding
By
–
With agentic coding, complexity accumulates mechanically: useless code ends up in the codebase, migrates to the context window, degrades the model's reasoning capabilities, and leads to even more useless code (often to
-
AI in 2040: Nearly Optimal Stack, Massive Current Inefficiency
By
–
AI in 2040 will not be built on the stack we use today. It will be much closer to optimal. The current stack exhibits 3-4 orders of magnitude data inefficiency and 4-5 orders of magnitude compute inefficiency. Nearly optimal AI is what
-
Three attitudes towards tokens: relaxed, intense, meta
By
–
Relaxed: Maximize tokens
Intense: Minimize tokens
Meta: Min-max tokens -
SaaS bears’ belief: software worth zero with Claude, lack of vision
By
–
It seems almost too stupid to be true, but apparently the literal belief of SaaS bears is 'all software is worth 0 because Claude can one-shot these apps'. Absolutely staggering levels of lack of long-term vision in that statement.
-
Fchollet denounces the madness of generative AI and Adobe
By
–
Yeah, it's pure madness, and people who use both generative AI and Adobe products understand why. Moreover, image generation became mainstream 4 years ago and ChatGPT was launched 3.5 years ago, so if you were right, we shouldn't
-
AI ARR triples to $500M, Firefly reaches $300M
By
–
Their AI-focused ARR tripled year over year to surpass $500 million. Very few enterprise software companies report this level of direct, paid AI adoption. The engine of this breakthrough is Firefly, which now reaches $300 million.
-
Radically efficient AI for an open-source future
By
–
The way we will create a future where powerful AI is open-source and accessible to all is by making AI radically more efficient, both in terms of inference compute and (more importantly) in terms of training data requirements. That is what