
// State-Externalizing Harnesses // A new paradigm is emerging on how to effectively build agents and harnesses. If there is a state that the environment can maintain reliably, it probably doesn't belong inside the policy. Move it into the harness, and a 20B model trains
@dair_ai
-
Principaux articles IA de la semaine (24-31 mai)
By
–
The Top AI Papers of the Week (May 24 – May 31) – SkillOpt
– AutoScientists
– The Efficiency Frontier
– Language Models Need Sleep
– Adapting the Interface, Not the Model
– Forecasting Scientific Progress with AI
– Compiling Agentic Workflows into Weights Read on for more: -

Proactive Agents: LLM Efficiency in Wake Triggers
By
–
Do proactive agents really need an LLM to decide when to wake? The default proactive agent calls an LLM on every event just to decide whether to wake up. That is a lot of expensive inference spent on a yes or no. New research from Microsoft and Purdue asks whether the trigger
-

AutoScientists: Decentralized AI Agents for Scientific Research
By
–
Banger paper from Harvard. AutoScientists drops the central planner entirely. Agents interpret shared experimental data, self-organize around promising directions, evaluate proposals before resource allocation, and document successes AND failures. Decentralized AI co-scientists
-

Long-Horizon Agents: Attention Scaling and Sleep Mechanisms
By
–
// Language Models Need Sleep // Let your agents "sleep", folks. On a serious note, this is a fascinating paper on getting the most from long-horizon agents. Here is the problem with agents today: Attention scales badly with context length, so long-horizon agents keep paying a
-

LLM Context Cost Optimization and Efficiency Strategy
By
–
// The Efficiency Frontier in LLMs // (bookmark this one) How much are you overpaying for context you do not need? It turns out that context costs dominate production LLM bills, and the right strategy depends on how often you reuse preprocessing. Modeling that explicitly lets
-

Microsoft Paper on Self-Evolving Agent Skills
By
–
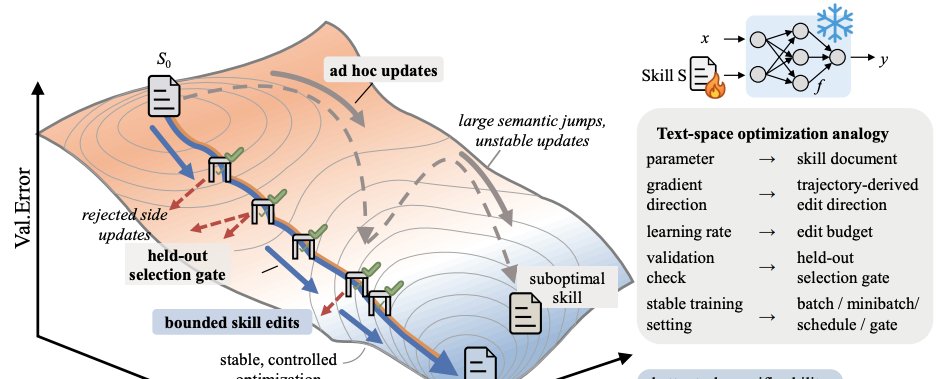
New paper from Microsoft on Self-Evolving Agent Skills
-

Top AI Papers of the Week: Agents and Architecture
By
–
The Top AI Papers of the Week (May 18 – 24): – AIRA
– MetaCogAgent
– Memory as a Model
– Code as Agent Harness
– Weak-Model Critic-Comparator
– OpenAI Disproves the Unit Distance Conjecture
– Production Agent Architecture Methodology Read on for more: -

Frontier Models and Scientific Progress Forecasting Study
By
–
Can frontier models forecast scientific progress? Mostly no, but here is why. This work looks at 4,760 scientific events across disciplines. Frontier models can identify plausible research directions when given options. They cannot reliably predict whether an advance will land,
-

Paper: Memory-as-a-Model for LLMs Enables Continual Learning
By
–
// Memory as a Model // The paper augments any LLM with a separate trained memory model that stores, retrieves, and integrates facts on its behalf. It decouples memory updates from base-model weight updates. It achieves continual-learning robustness without catastrophic