
Who should design the training environment for an RL agent, the practitioner or the policy itself? RL pipelines for LLMs usually rely on manually redesigned environments between stages, with practitioners guessing which configuration will best improve the current policy. This
@dair_ai
-

Autonomous Agents and Task Repetition
By
–
Outstanding paper on computer-using agents. (bookmark it) Computer-using agents drive real software through the screen, but they solve every task from scratch. Ask one to repeat a task, and it re-reads the screen and re-reasons every tap, paying the full cost again. PreAct
-

HarnessX: Harnesses You Compile, Not Hand-Build
By
–
// HarnessX: Harnesses You Compile, Not Hand-Build // (bookmark it) Most agent harnesses are hand-crafted and frozen. Each new model or task means rewriting the prompts, tools, memory, and control flow from scratch, and the rich traces from every run get thrown away. HarnessX
-
Top AI Papers of the Week June 7-14
By
–
The Top AI Papers of the Week (June 7 – June 14) – Agentopia
– Self-Harness
– Agents' Last Exam
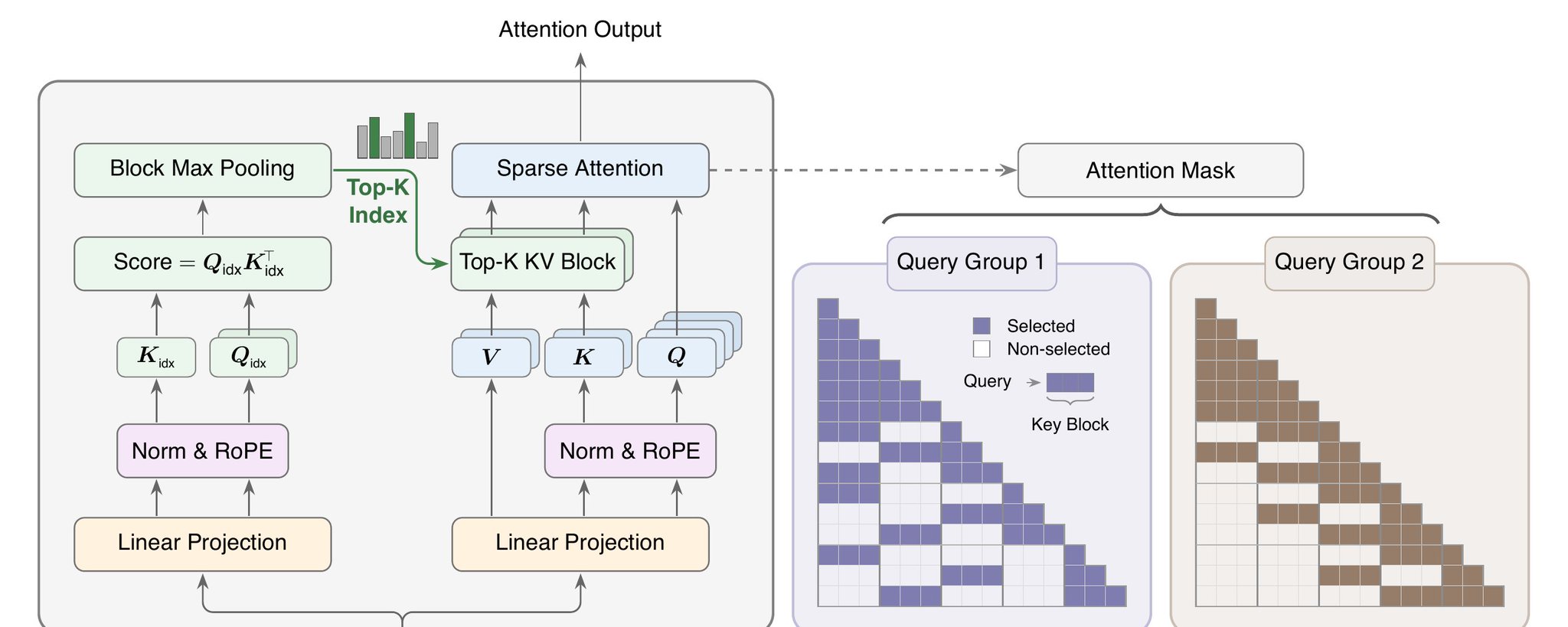
– MiniMax Sparse Attention
– Lookahead Sparse Attention
– How AI Agents Reshape Knowledge Work
– The Geometry of On-Policy Distillation Read on for more: -

Consensus on answers hides deeper reasoning disagreement in agent debates
By
–
// The Consistency Illusion // Multi-agent debate can make agents agree on the final answer while their underlying reasoning stays misaligned. This work finds that consensus on the output hides disagreement on the path that produced it, and you only ever see the output. A lot
-

Agentopia: Long-Running Life Simulation for LLM Agent Societies
By
–
// Life Simulation in Agent Societies // One of the more ambitious agent-society testbeds to land this month, and it arrives as a 79-page release. Agentopia drops many LLM agents into a long-running world where they live, interact, and learn over extended horizons. The goal is
-
Top AI Papers of the Week: May 31 – June 7
By
–
The Top AI Papers of the Week (May 31 – June 7) – LEAP
– AutoLab
– Learn From Your Own Latents
– Reusable Context Engineering
– Self-Revising Discovery Systems
– Scaling Laws for Agent Harnesses
– Disentangling Agent Self-Evolution Read on for more: -

Agents’ Last Exam: A Challenging Benchmark for AI Task Performance
By
–
// Agents' Last Exam // Agents' Last Exam is a living benchmark of over 1,000 economically valuable tasks, built with 250+ industry experts and mapped to the U.S. federal occupational taxonomy. The hardest tier sits at a 2.6% average full pass rate across mainstream harnesses
-

AutoLab: Encoding Persistence in Long-Horizon Agents
By
–
Outstanding paper on long-horizon agents. (bookmark it) Similar to humans, how do you make agents persist on a difficult task, and how is that useful? And which models today work well on this? This new work, AutoLab, explores this question and how encoding persistence in
-

Primer on post-training reasoning data synthesis
By
–
Nice primer on post-training reasoning data. (bookmark it) This is one of the first primers to pull the scattered post-training reasoning-data literature into one place, synthesizing over 150 public studies and system reports that previously lived across dataset papers, RL