Interesting, it somewhat confirms my intuition: > "even with a longer time horizon, xhigh doesn't solve significantly more tasks" Models often hit a conceptual wall and in those cases no amount of extra time will help!
@alexjc
-
Model Inference Performance and Tool Call Optimization Analysis
By
–
OK, I will ponder it! Currently: it's only one turn, about 20-30 tool calls (est.) depending whether you include file reads, and networking is definitely not the bottleneck. But yeah, load/inference speed is punished — but that's real-life! I think Kimi K2.5 might have
-
Continual Learning Benchmark: Knowledge Transfer for AI Models
By
–
Thanks, still finishing the blog post so I'll cover all that! It's designed closer to a continual learning benchmark, new context for each problem and models get to transfer their lessons to future selves. They also have access to prior solutions, as that handoff is necessary to
-
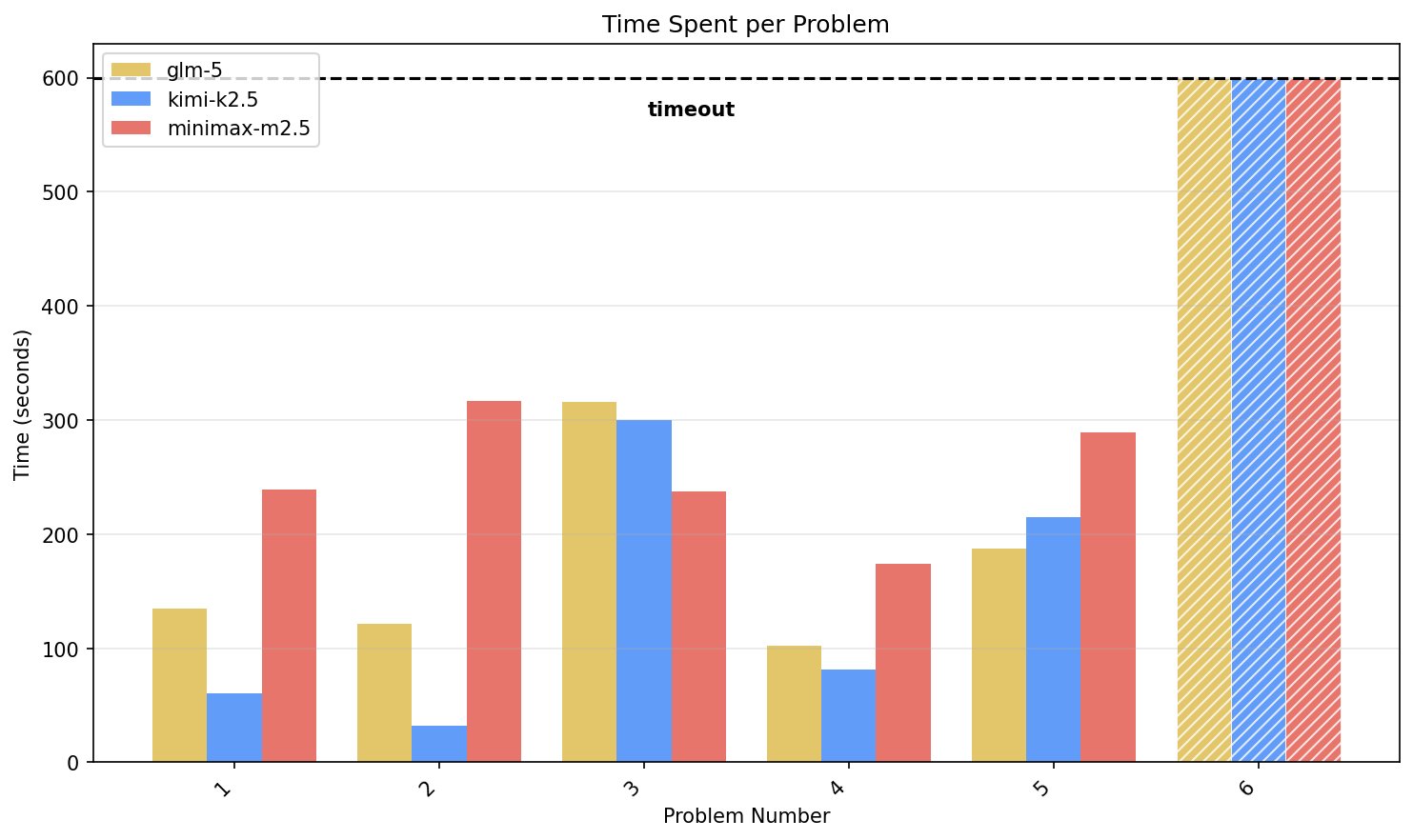
Open Weights Models Struggle on Logic Reasoning Benchmark
By
–
@nrehiew_ Hey, just made a logic reasoning / problem solving benchmark where open weights models get completely lost, but the frontier models make it look easy. Curious about your hypothesis why, thinking it's sparsity related:
-
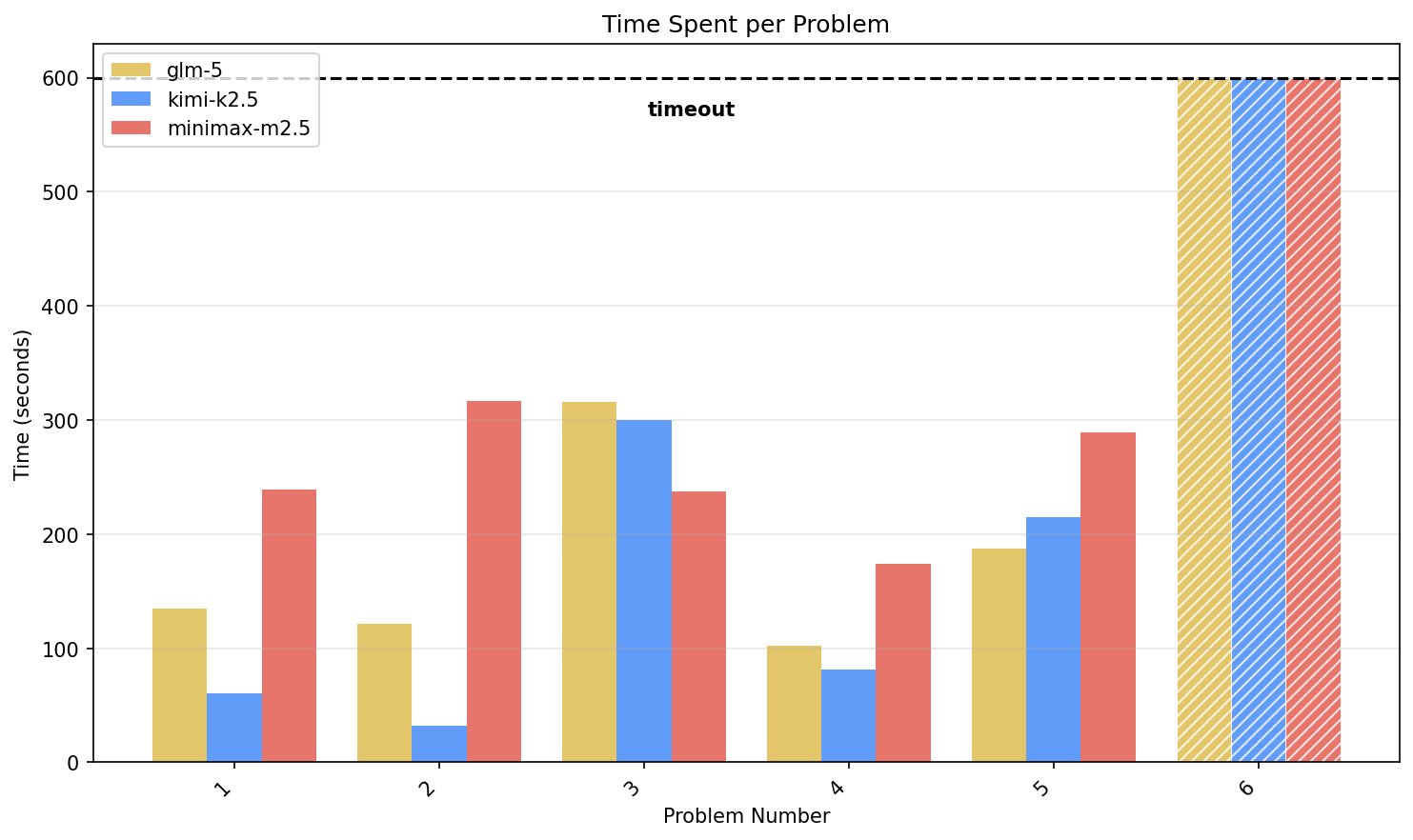
Open Models Overfitting Benchmarks While Losing Reasoning Ability
By
–
@xeophon On the topic of swe-rebench and lower scores, another data point for you: my own analysis suggests open models are overfitting to popular patterns/benchmarks while failing to get better at logical reasoning / problem solving:
-
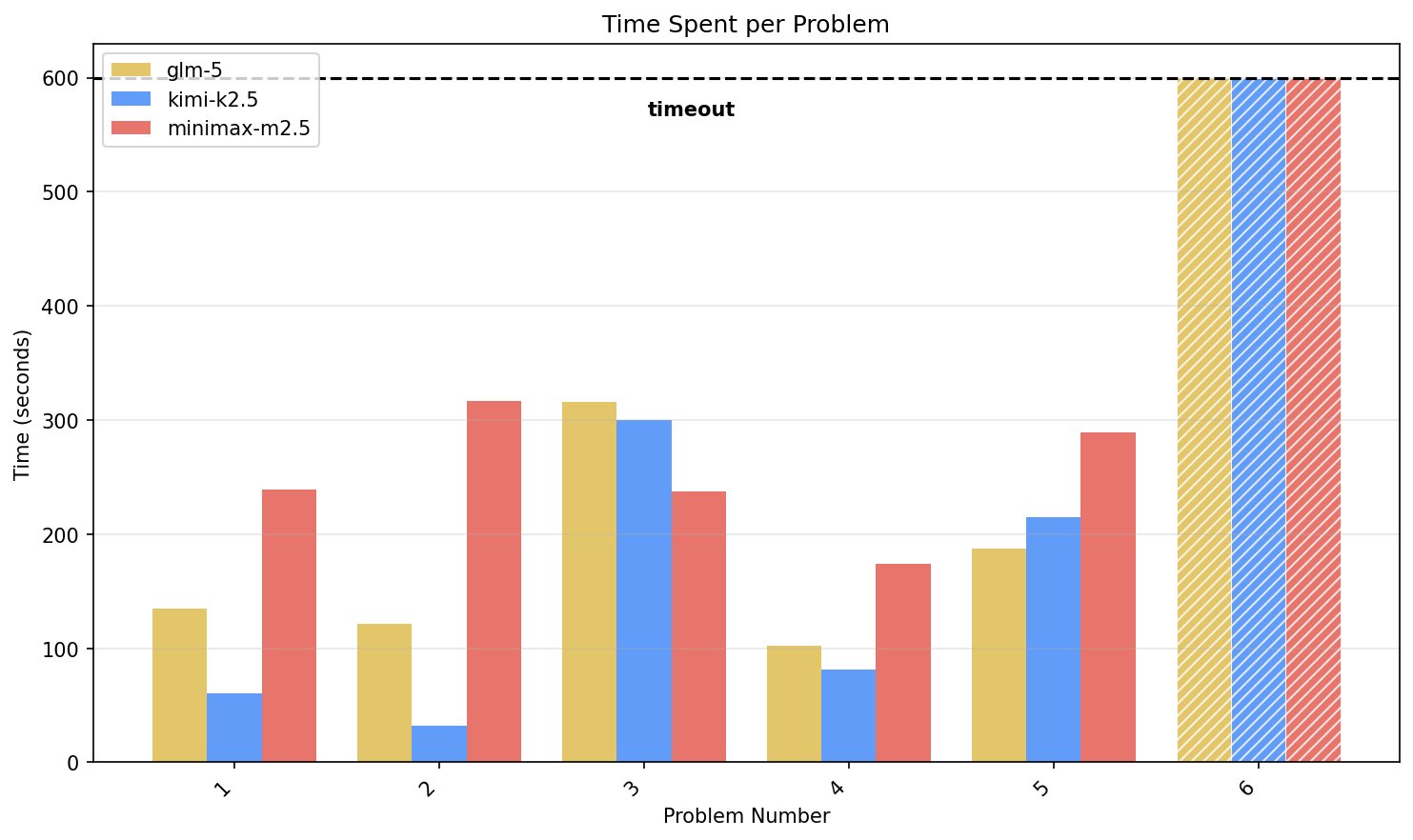
Logic Reasoning Benchmark: Frontier vs Open Weight Models
By
–
@scaling01 Before your pivot to Star Wars memes, I remember you used to be interested in LLMs! I just built a logic reasoning / problem solving benchmark where frontier models one-shot solutions, but the open weights models really struggle:
-
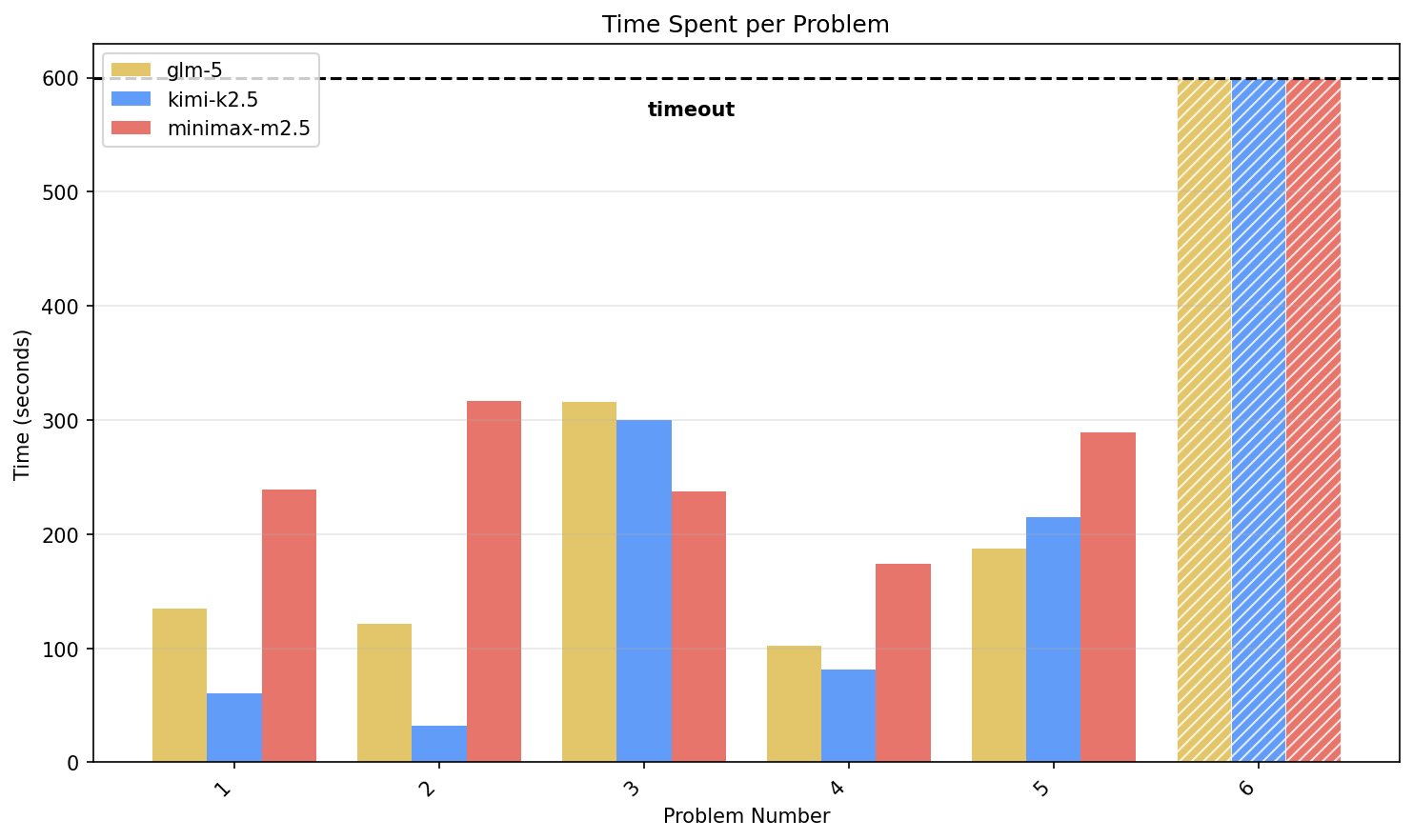
Moonshot’s Ultra-Sparse Approach Struggles With Logical Reasoning
By
–
@zephyr_z9 On the topic of Moonshot affording compute, there's a risk… I think the ultra-sparse approach is failing to handle logical reasoning and problem solving like frontier models. Made a new benchmark digging deeper:
-

DeepSeek V4 Open Models Lag Behind Frontier AI
By
–
@teortaxesTex About DeepSeek V4 being able to compete with the frontier, I made a new benchmark that suggests open models (particularly the new ultra-sparse ones) are qualitatively worse at problem solving and logical reasoning:
-
Open Weights Model Performance: MoE Sparsity Challenges
By
–
I will add the remaining two (?) models rumoured for release early next week and finalize it with a blog post… In the meantime, if you have any theories why open weights struggle (my theory is that it's MoE/sparsity induced) — let me know!
-

Open Weights Models Lag Behind Frontier on Logical Reasoning
By
–
PREVIEW: The Joy Of Benchmarks (Q1'26) My new #AI benchmark on out-of-domain programming languages (joy) suggests that open weights models are qualitatively *far* behind the frontier on logical reasoning and problem solving… The newest models: GLM-5, Minimax M2.5, and Kimi