REMINDER: The project and releases are now hosted on Codeberg. Enjoying it very much, easier to customize the Action Runners.
@alexjc
-

joyfl v0.7: Stack Manipulation Puzzle Solver Framework
By
–
joyfl — v0.7: Quotation Solver Newest release last week uses the existing search framework to find matching program fragments. It's like using a sudoku solver to discover solutions for stack manipulation puzzles, based on user-provided tests.
-
GLM-5 Regression in Interactive Python Coding Performance
By
–
I think GLM-5 is a regression on interactive Python coding though, been using it almost daily and GLM 4.7 before that. The most likely culprit is DSA — and I conclude it's not straightforward to apply. Likely V4 manages better, but there will be tradeoffs.
-
GLM-5 Regression for Python Coding Tasks Compared to GLM 4.7
By
–
Alright, I'm calling it: GLM-5 is a regression from GLM 4.7 for Python coding. Subscribed to Z(.)ai on the basis of 4.7 as it reliably took over all my devops too, and been using GLM 5 since launch. But with multiple turns of Python writing/editing 5 regularly gets confused
-
LLM Performance Degradation Over Extended Context Windows
By
–
Performance degrades over the course of 100k tokens even, let alone the whole currently supported window… After a few turns of coding Python, it just can't reliably use its tools anymore. Requires constant jumping back and/or offloading.
-
Tool calling conventions bug fixed at launch
By
–
At launch it would screw up the tool calling conventions, is that better now? Maybe it was a launch glitch…
-
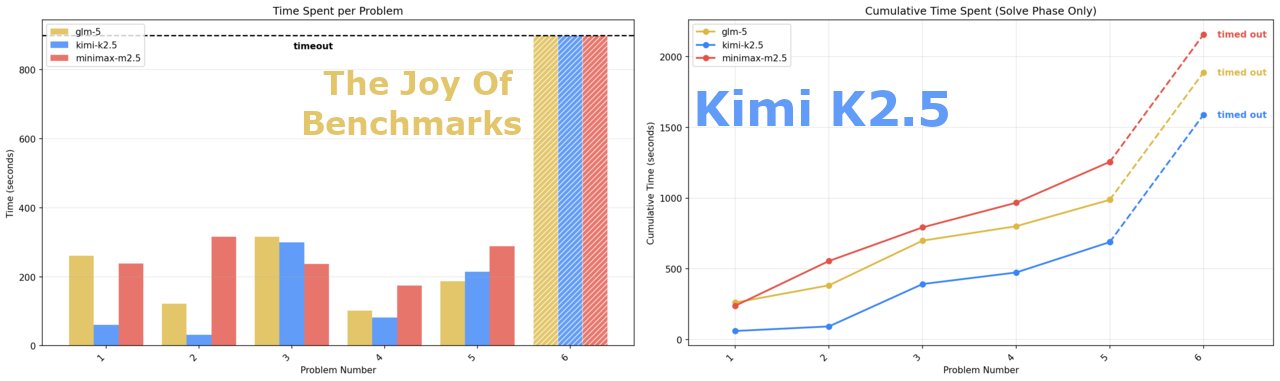
Joy Of Benchmarks Q1’26: AI Problem-Solving Creativity Focus
By
–
You know how AI benchmarks seem to measure intelligence on abstract problems, but then it turns out the models can't even think logically? This one instead focuses on problem solving creativity, not nerdy math… NEW: The Joy Of Benchmarks Q1'26 is out!
-
Zai API reliability concerns following GLM5 launch
By
–
This is a benchmark-specific timeout, I terminate them if they get stuck with no sign of making progress. The Zai API has not been so reliable since GLM5 launch, but much better in the past 24h-36h.
-
Cursor AI struggles with tool reliability and context management
By
–
Not very polished… In Cursor, it barely worked at all even! Couldn't even call basic tools reliably, started screwing up files at turn two as if it was at the end of its context.
-
Compute Budget vs Token Count: Scaling Model Performance
By
–
Yeah, I get it. Just like pass-k also improves things a lot when you increase k, predictably so! Thinking a compute budget is the best compromise in this case, as it's a bit more grounded & less biased than token counts…