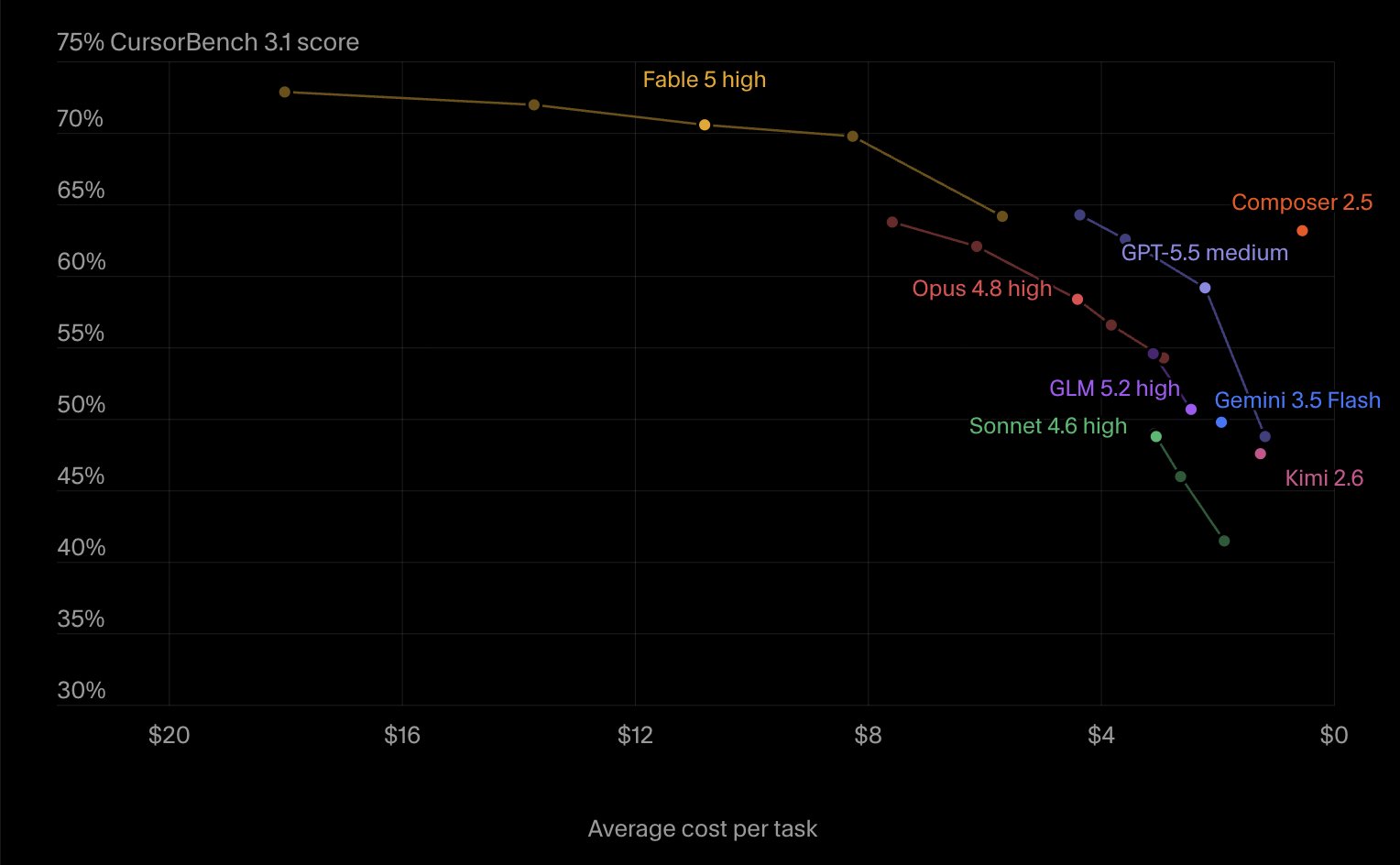
This is good news, but the fact that Composer 2.5 comes out on top over GLM 5.2 here should trigger a serious re-evaluation of the entire benchmark. It's nowhere near in practice except basic tasks… and that undermines trust in Cursor's entire model evaluation / publicity.
@alexjc
-
Cursor may pivot if xAI underperforms, faces strategic board mistakes
By
–
Cursor will get one more chance to pivot if/when the xAI training run underperforms. Should they become sandwiched between Meta and Google in terms of frontier failures, they'll have to consider the strategic mistakes made by their board…
-
Thought process degrades at 400k tokens; tool call tax favors 200k limit
By
–
At around 400k, sometimes much before, there's a degradation of the thought process. Costs increase a lot too due to frequency of calls and the 18.5% "tool call tax." Seriously thinking the default 200k limit is a sensible one… Setting it to 1M gives you flexibility only.
-
Use GLM 5.1 to avoid 3x token cost during morning hours
By
–
Those of you new to Zai coding subscription, the time between 8:00 and 12:00 (Central European Summer tz) costs you 3x the tokens with GLM 5.2. You can use GLM 5.1 for 1x cost, it's IMHO still very good — people didn't catch on to it but I've been using it for a month!
-

Enable Max mode before first message for GLM 5.2 1M context Cursor
By
–
If you want to use GLM 5.2 with the full 1M context on BYOK in Cursor, you need to enable Max mode *before* the first message is sent. Thanks @OnurGvnc
! @Zai_org -
Request for Cursor AI to support 1M context models with BYOK
By
–
Need @cursor_ai to add support for 1m context models with BYOK, defaults at 200k…
-
Chinese peak hours (14-18) cause 3x model cost, CEST 08-12
By
–
Between 14:00-18:00 Chinese time it's peak hours and the model costs 3x, that's 08:00 to 12:00 CEST. People need to work it out in their own timezones…
-
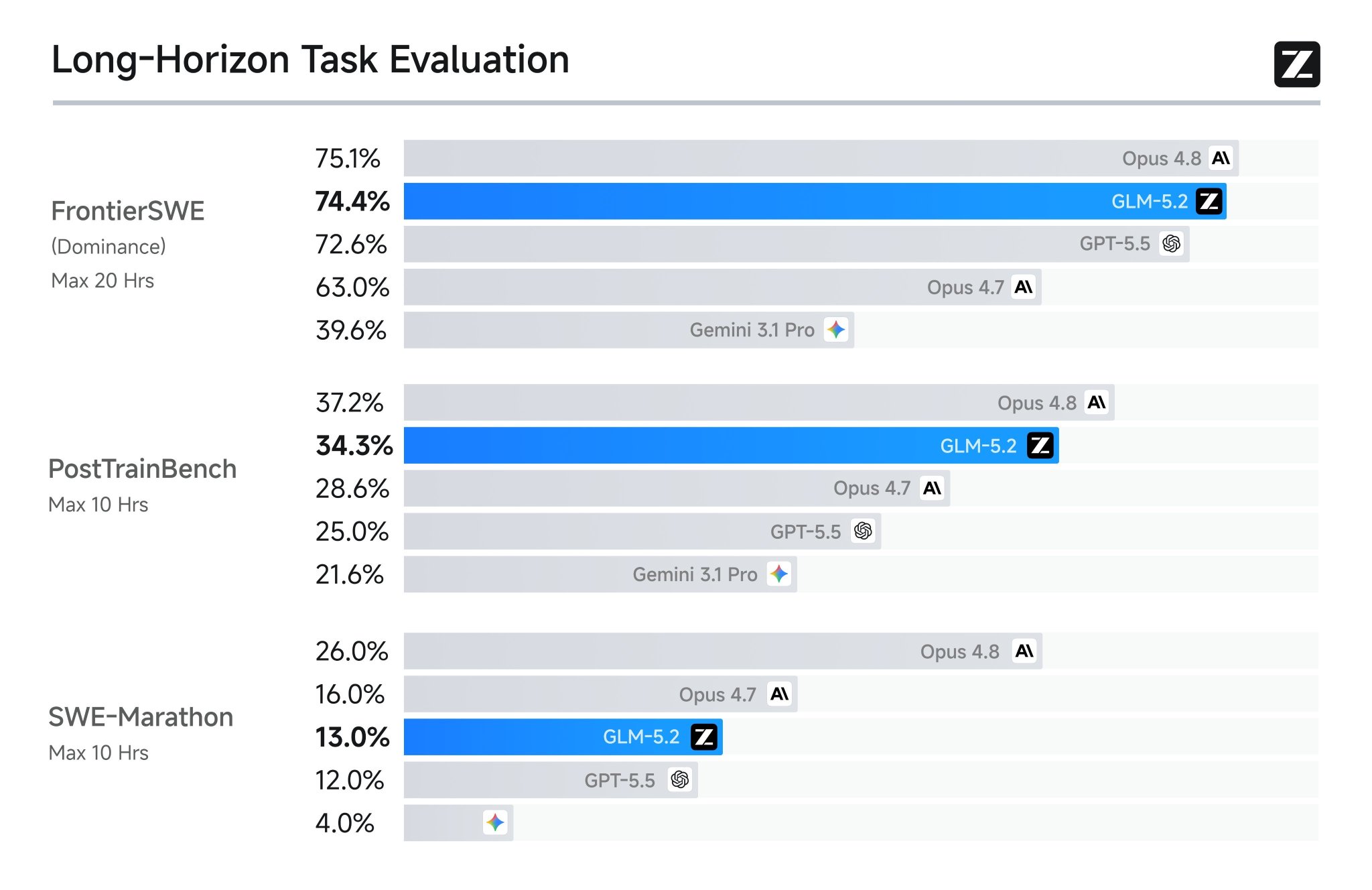
GLM 5.2 Enjoyment Resembles Opus 4.6 Launch, Metrics Miss
By
–

What's missing from all these benchmarks is that GLM 5.2 is enjoyable to interact with, feels much like Opus 4.6 did around launch. The metrics don't capture that! I've been on GLM 5.1, and 5.2 since Saturday, nearly exclusively for almost a month now…
-
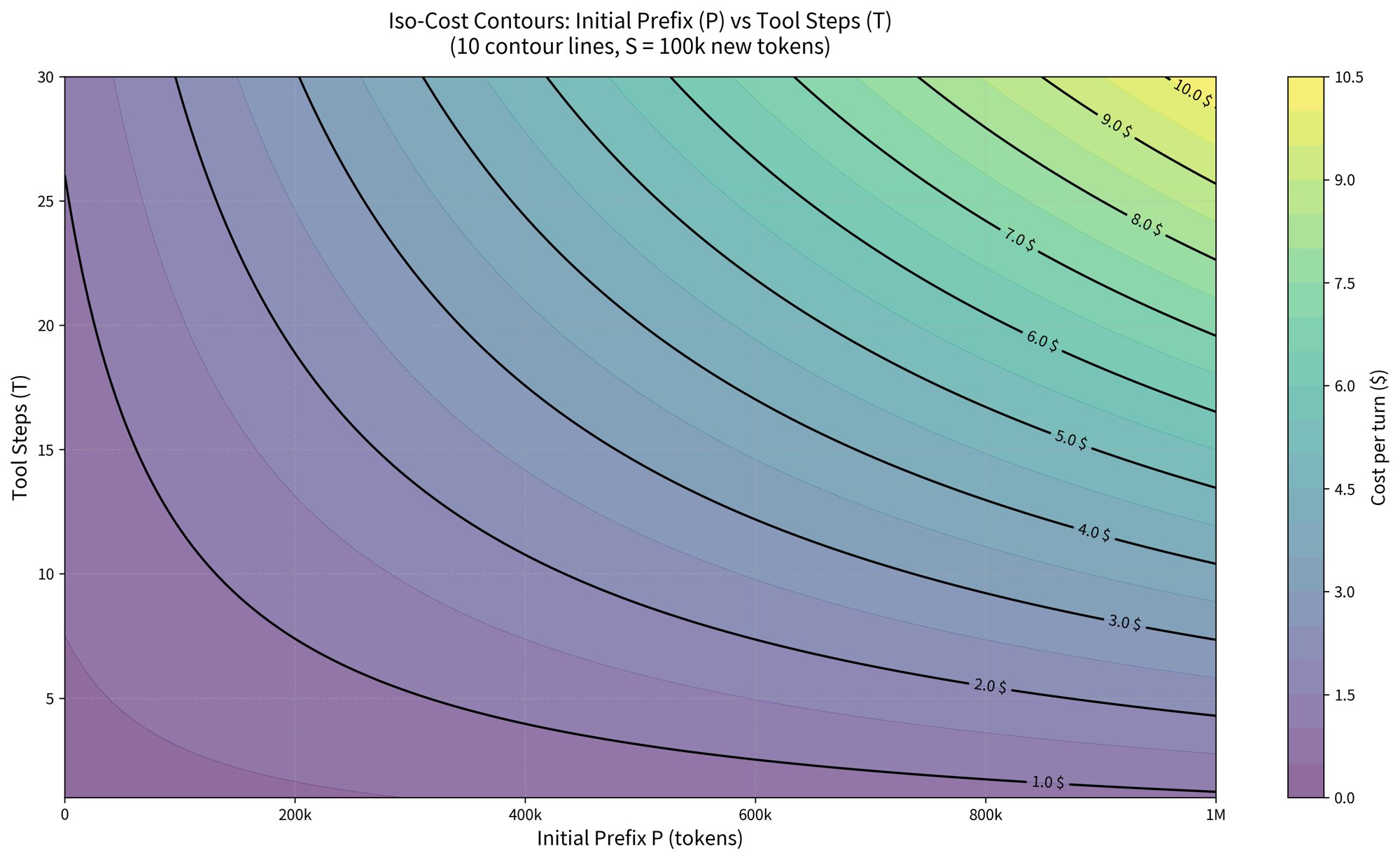
The excessive cost of tool calls in agentic coding
By
–

Biggest problem in agentic coding? The tool call tax! (No, it's not an EU regulation.) Did you know… – It costs you *10x* more $$$ to generate 100k tokens that include T=30 tool calls vs. T=1 tool call at the end of your
-
Experience with Claude Fable: prompts, cost, iteration, and GLM 5.1
By
–
My experience with Claude Fable. > craft a meticulous prompt
> worry about the cost of the task
> iterate to add more details
> decide to run the prompt on a subfrontier model
> GLM 5.1 processes it laboriously
> it really makes some things work!