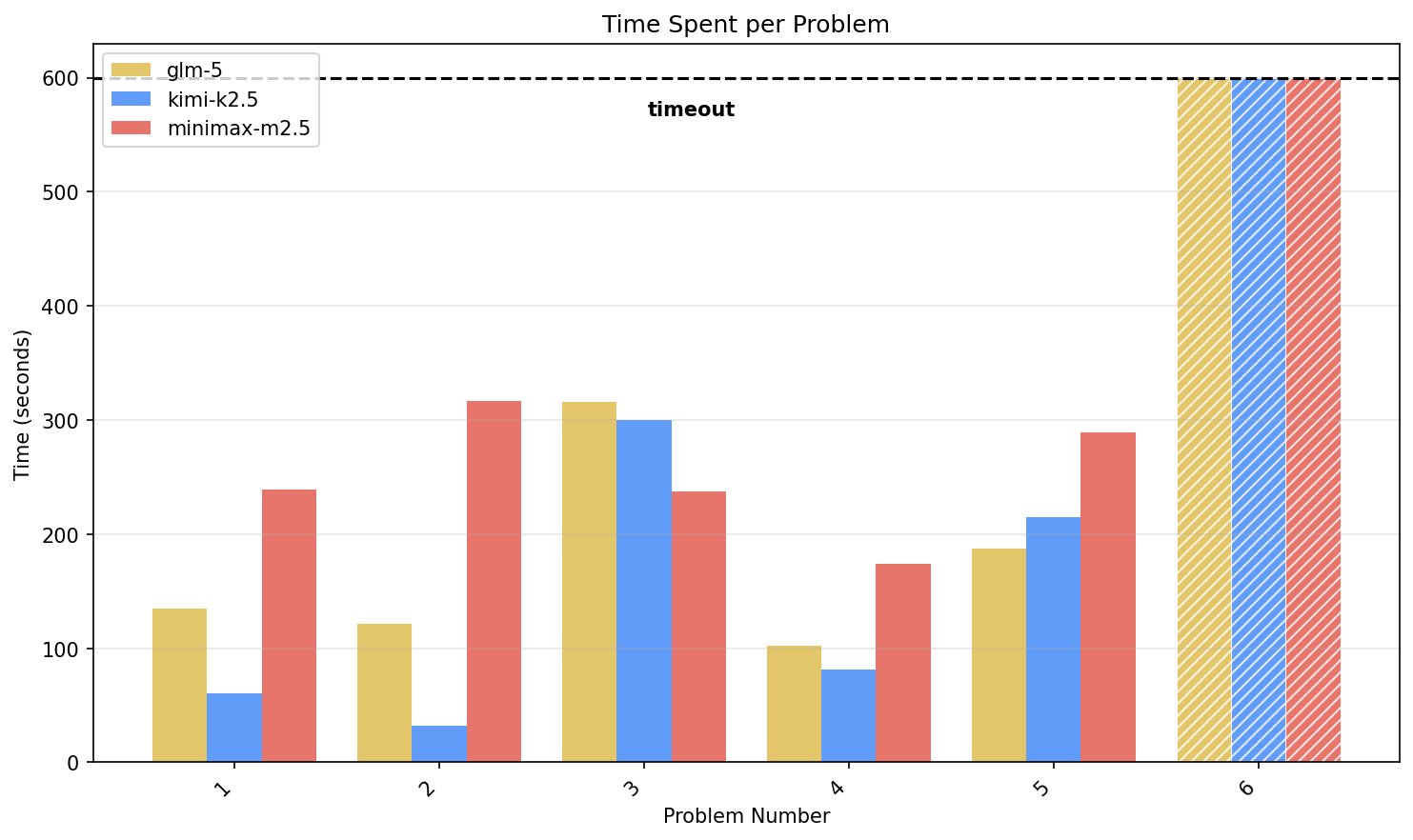
@xeophon On the topic of swe-rebench and lower scores, another data point for you: my own analysis suggests open models are overfitting to popular patterns/benchmarks while failing to get better at logical reasoning / problem solving:
Open Models Overfitting Benchmarks While Losing Reasoning Ability
By
–