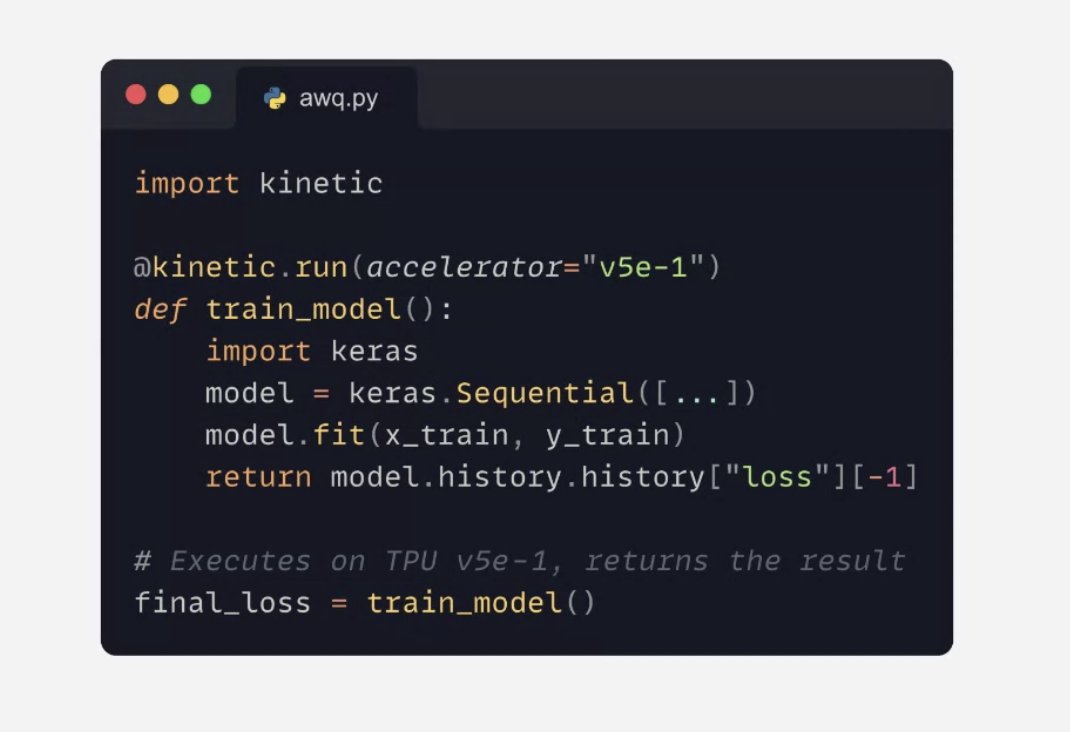
A brand new product: the Keras Kinetic library lets you run jobs on TPU (and Google Cloud GPUs) via a simple decorator. Takes care of packaging your code, uploading your dataset, log streaming, winding down jobs…
SOFTWARE
-
Keras 3.14 Release: New Features Announcement
By
–
Upcoming Keras 3.14 release: a host of new features…
-
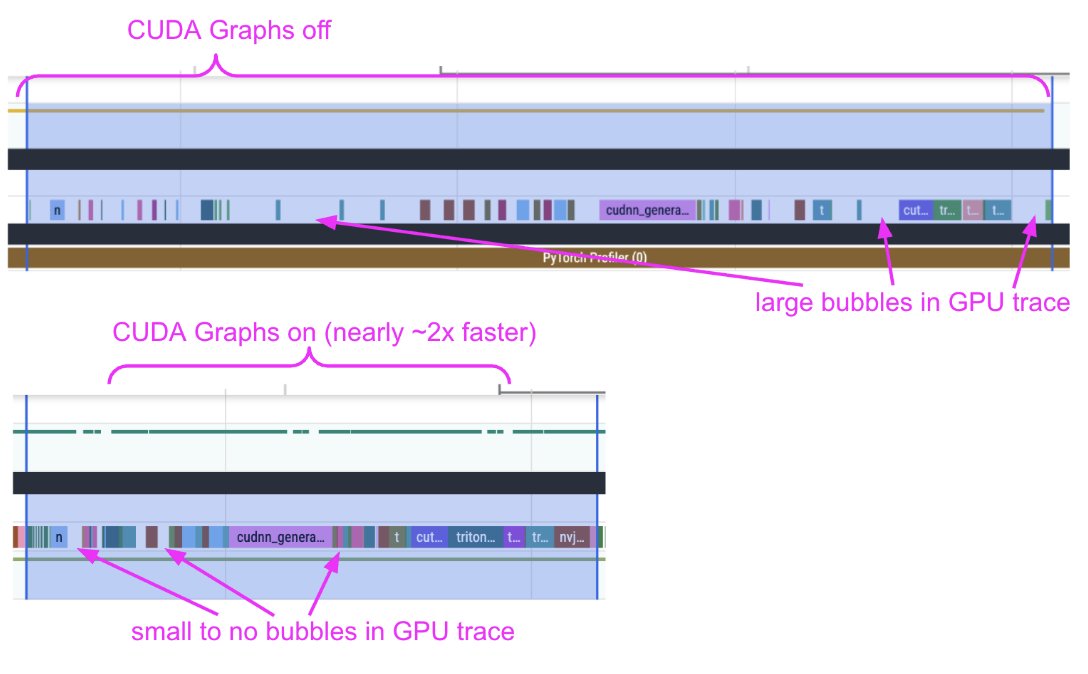
Profiling Diffusion Pipelines with Claude for torch.compile Optimization
By
–
We're shipping an elaborate guide on how to profile diffusion pipelines in Diffusers to set them up for success with `torch.compile` 🔥 We devised a workflow with Claude & it turned out to be quite effective. It served its purpose well. With the help of the trace alone, we uncovered: 1. CPU <-> GPU syncs 2. CPU overheads 3. Kernel launch delays When we provided the profile trace and our observations from the trace to Claude, and helped us get rid of the issues, it did well. However, it did so iteratively. The process was intellectually fun and engaging!
→ View original post on X — @huggingface, 2026-04-03 17:07 UTC
-
Marc Andreessen’s 2026 AI Thesis: Agents and Open Source
By
–
🆕 Marc Andreessen’s 2026 AI Thesis: Agents, Open Source, and Why This Time Is Differenthttps://t.co/wmu0s7vyLn@pmarca of @a16z says AI people keep swinging between utopian and apocalyptic for one simple reason: this field has been “almost here” for 80 years. But now, the… pic.twitter.com/kYnLP5jZh1
— Latent.Space (@latentspacepod) 3 avril 2026🆕 Marc Andreessen’s 2026 AI Thesis: Agents, Open Source, and Why This Time Is Different latent.space/p/pmarca @pmarca of @a16z says AI people keep swinging between utopian and apocalyptic for one simple reason: this field has been “almost here” for 80 years. But now, the breakthroughs are no longer theoretical. Reasoning, coding, agents, and self-improvement are all starting to work at once. This episode goes deep on AI winters, OpenAI + OpenClaw, infrastructure overbuild risk, proof-of-human, why software may soon be written mostly for bots, and why the real bottleneck may be society adopting AI rather than the models improving.
-

Cohere and Microsoft discuss enterprise AI acceleration on Model Mondays
By
–
How can enterprises accelerate decision-making and improve efficiency? We're joining @Microsoft's Model Mondays on April 6th to discuss how AI can help you: 🌎 Drive real-world enterprise value 💡 Surface precise, verifiable insights 📌 Use Microsoft Azure and Cohere enterprise models to accelerate your AI journey
-

CCTV Object Detection: Offloading Pi 5 to Metis Compute Board
By
–
Offloaded CCTV object detection from a Pi 5 to a Metis Compute Board. Pi fan stopped screaming. ~30 FPS across two 1080p cameras, ~196ms latency. Zone filtering, Home Assistant webhooks, phone snapshots in 1-2 seconds. Full tutorial + code. #HomeAssistant #EdgeAI 📹 eu1.hubs.ly/H0t23Nx0 @raspberry_pi
→ View original post on X — @axeleraai, 2026-04-03 13:45 UTC
-
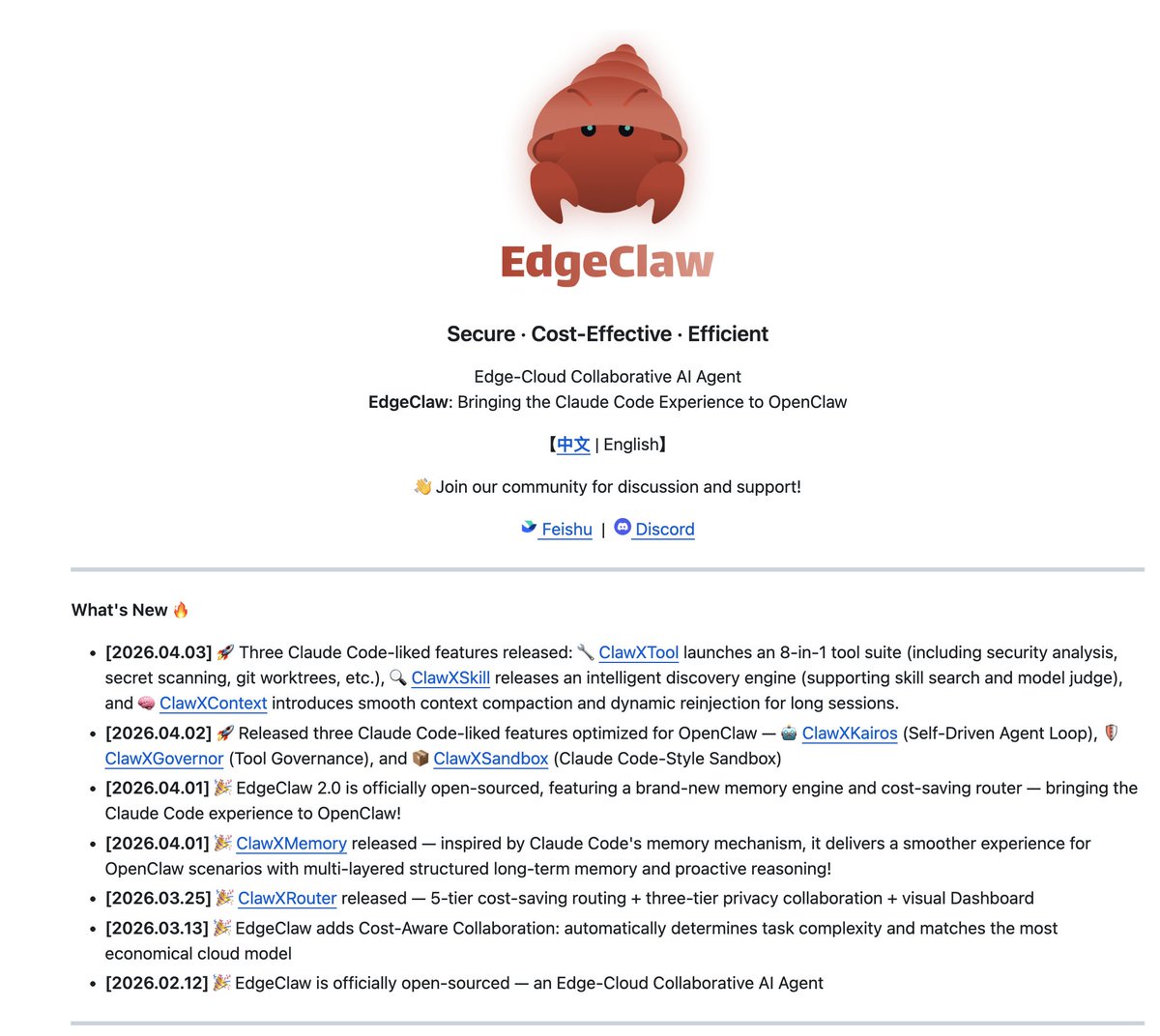
EdgeClaw 2.2 Launches Three New Claude Code Features
By
–
🚀 [OpenClaw x Claude Code DAY 3 – Almost Done!] 🚀 Three more CC features—including the highly requested Buddy—are now live in EdgeClaw 2.2! 🦞 Try it now: github.com/OpenBMB/EdgeClaw Here is what we shipped today: 👇 ⚡️ ClawXskills: Progressive, high-efficiency skill calling. The loading phase now consumes just 15% of the original tokens! 🧠 ClawXcontext: Hierarchical context compression with on-demand expansion. Say goodbye to context bloat and lost information! 🐾 ClawXBuddy: Draw a random "blind box" to get your own unique companion pet! (Warning: No abandoning allowed! 🙅♂️❤️) The reconstruction of CC features is complete, but EdgeClaw’s evolution has just begun. We will keep pushing boundaries! 🌊🚀 #ClaudeCode #OpenClaw #EdgeClaw #LLMs #OpenSource
→ View original post on X — @aihighlight, 2026-04-03 13:39 UTC
-
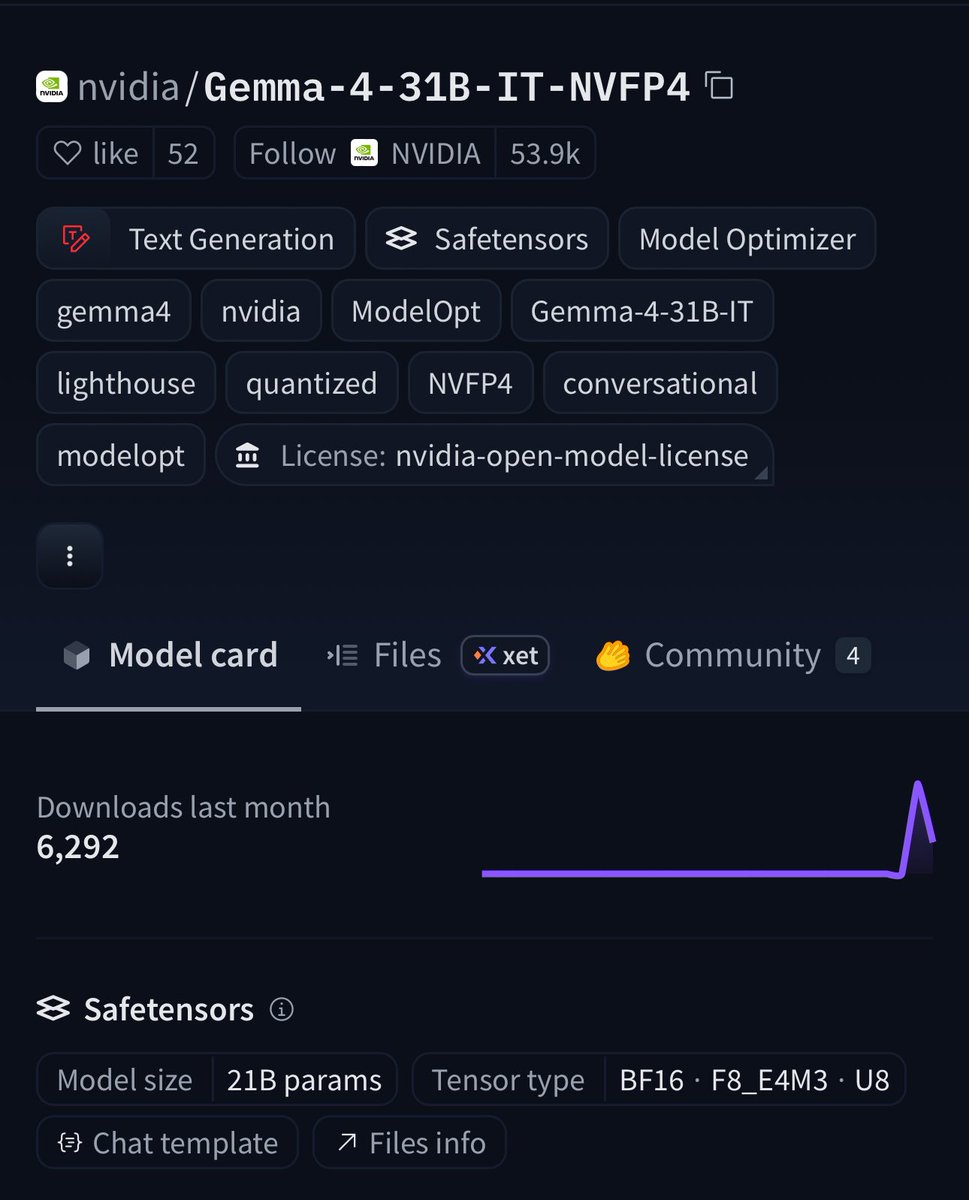
NVIDIA Quantizes Gemma 4 31B with NVFP4 Compression Technology
By
–
BREAKING:🚨 NVIDIA just quantized Gemma 4 31B on Hugging Face 🔥 NVFP4 compression = 4x smaller weights with frontier-level accuracy. ✅99.7% of baseline on GPQA (75.46% vs 75.71%). 📈256K context window. 🧐Multimodal (text + images + video). vLLM-ready + Blackwell optimized. VRAM requirements: ⚡️Weights only: ~16–21 GB 🚀Everyday use: Runs on 24 GB GPUs 📈Full 256K context = 32 GB VRAM sweet spot (RTX 5090-class consumer GPUs) This is the 31B-class frontier model you can actually run locally on a high-end rig. Try it today👉 huggingface.co/nvidia/Gemma-…
→ View original post on X — @huggingface, 2026-04-03 13:30 UTC
-
Software Engineers Transform Robotics: New Infrastructure Opportunities Emerge
By
–
There are now two types of robotics founders and the split matters more than consumer vs. industrial. A growing wave of software engineers are building robots, but they're bringing software expectations with them: simulation should work like Vercel, hardware talent should be sourceable via API, and if CAD takes three months to learn, they'll find a workaround in three days. The gap between what they expect and what exists is enormous. There's no Common Crawl for robotics data. Selling hardware is nothing like selling SaaS. And the entire tooling stack was built for people willing to spend weeks wiring things together. That gap is where the next generation of robotics infrastructure companies gets built. Diego Prats | 🤖 (@mexitlan) Are you fleeing to robotics because Claude Code cooked your job? Yeah… me neither… 😅… As part of building in the open, here are some more learnings from the physical AI ecosystem: Folks under-estimate the number of pain points and problems worth solving for the software-first robotics founder persona! — https://nitter.net/mexitlan/status/2039870415401836773#m
→ View original post on X — @whiteafrican, 2026-04-03 13:15 UTC
-
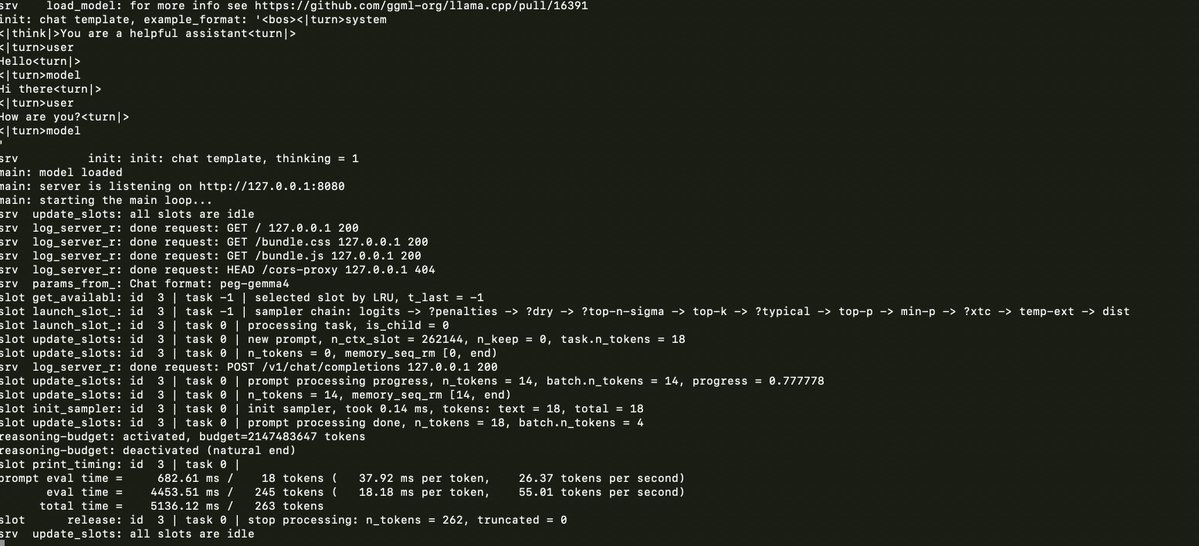
Running Llama.cpp and Gemma 4 on M1 Max MacBook Pro
By
–
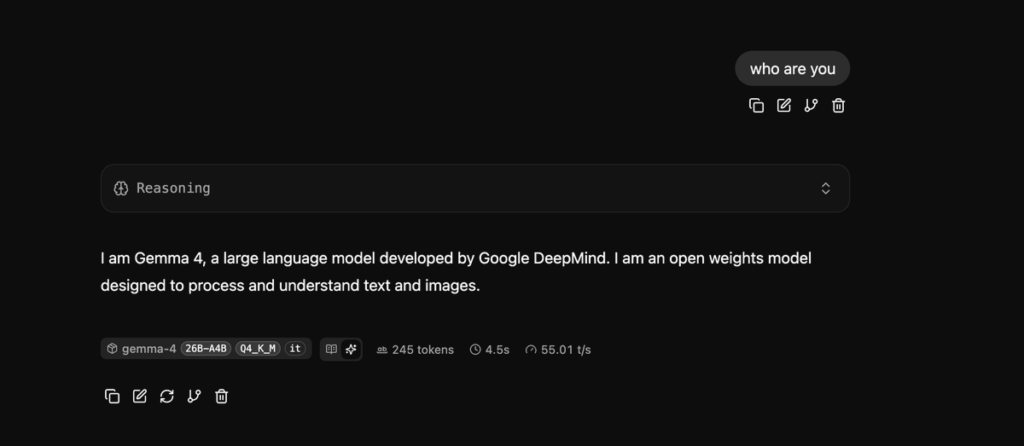
llama.cpp and gemma 4 on a 6 year old Macbook Pro M1 Max