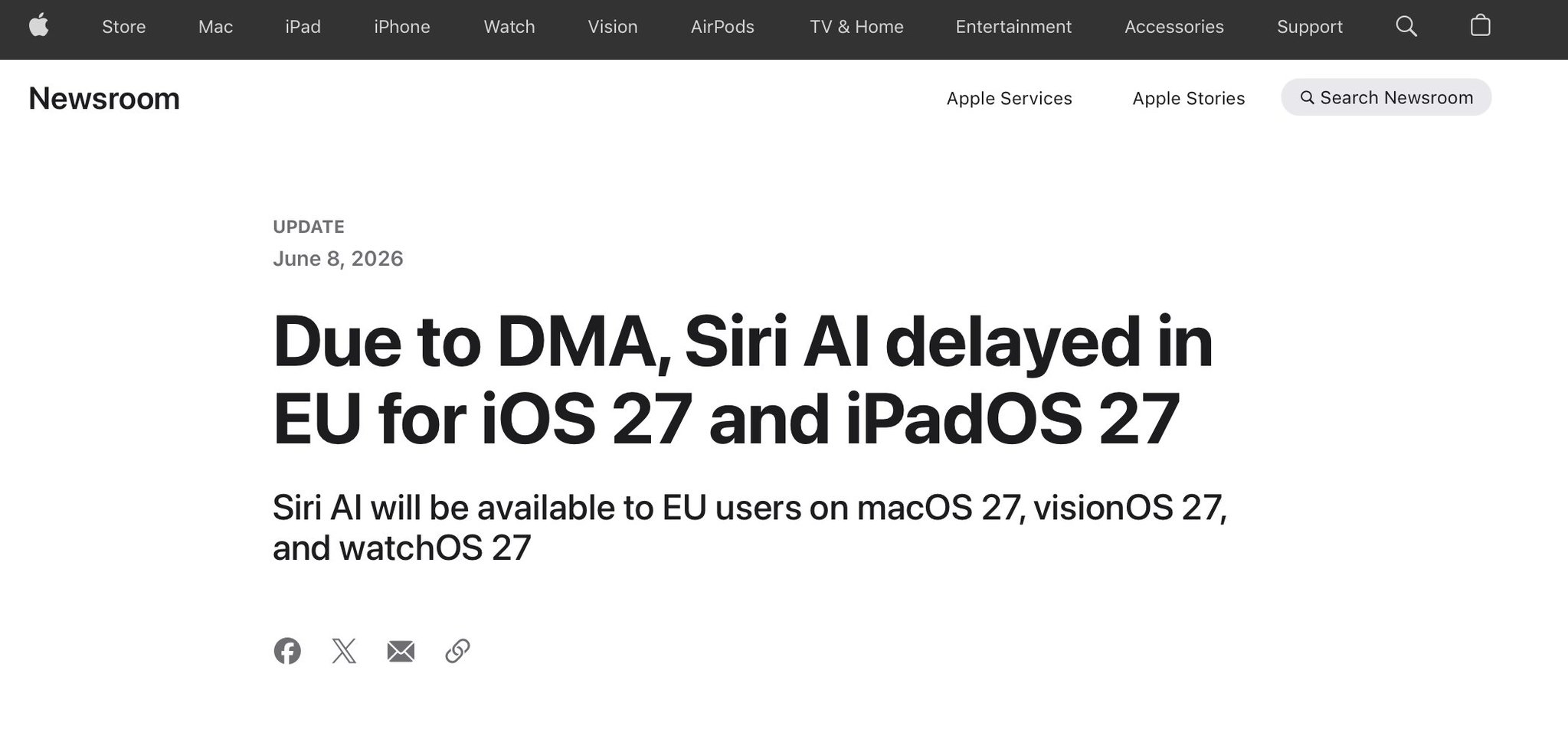


Apple makes it clear that Europe is itself to blame for the unavailability of Apple Intelligence. Apple says Siri AI won’t launch on iPhone and iPad in the EU because regulators interpret the DMA as requiring Apple to give rival AI assistants broad access to private user data.