Exactly. Scaling AI responsibly will depend on more than model performance. Data governance, residency, and trusted infrastructure are becoming core business and sovereignty considerations—not just IT requirements. Appreciate the share, @Lenovodc
DATA
-

Book on ML for Time Series Forecasting and Anomaly Detection
By
–
Machine Learning for Time Series with Python — Forecast, predict, and detect anomalies with state-of-the-art ML methods: http://
amzn.to/3wrjXVv by @benji1a —————
#DataScience #AI #Forecasting #PredictiveAnaytics #AnomalyDetection #IoT #IIoT #EdgeAI #EdgeComputing -

Designing Machine Learning Systems – Iterative Process for Production
By
–
Designing #MachineLearning Systems — An Iterative Process for Production-Ready Applications: http://
amzn.to/46epLSi by @chipro — 𝓣𝓸𝓹𝓲𝓬𝓼:
Engineering data and choosing the right metrics to solve a business problem Automating the process for continually developing, -

RAG-Driven Generative AI 2nd Edition: Build MAS-RAG with DualRAG
By
–
New (2nd edition) from @PacktDataML available at http://
amzn.to/4tULP1b RAG-Driven Generative AI — Build MAS-RAG with DualRAG, GraphRAG, multimodal video pipelines, and Oracle Database 23ai 𝗞𝗲𝘆 𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀:
Master DualRAG by combining vector search with SQL filtering -

LLM Engineer’s Handbook: Master LLM engineering from concept to production
By
–
LLM Engineer's Handbook — Master the art of engineering Large Language Models LLMs from concept to production: http://
amzn.to/4dUQrv6 v/ @PacktDataML Implement robust data pipelines and manage LLM training cycles Create your own LLM and refine with the help of hands-on -

NVIDIA and Zaha Hadid Architects Build Custom AI Tools for Secure Design
By
–
AI is most impactful when it's tailored to the way teams already work. Discover how Zaha Hadid Architects uses local compute, fine-tuned AI models, and NVIDIA technologies to build custom AI tools that accelerate design while keeping proprietary data secure.
-
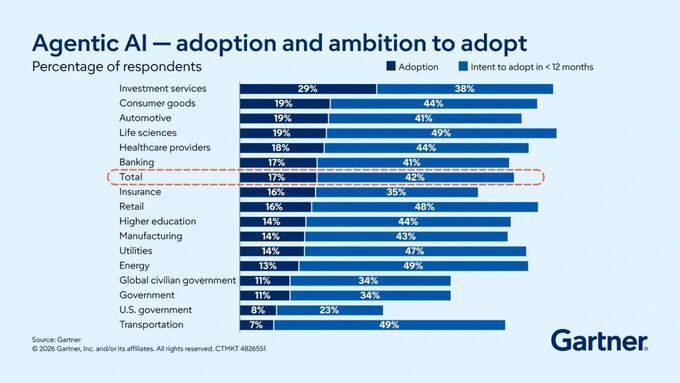
AI agent delays shift from code to coordination as platforms converge
By
–
Enterprise platforms converge on data, models and orchestration layers. Choices on architecture now steer how fast AI agents act across processes, so delays shift from code to coordination. Source @Gartner_inc Link https://
gtnr.it/4tKg5vC via @antgrasso -

2nd Edition Graph Machine Learning with PyTorch Geometric and DGL
By
–
2nd Edition at http://
amzn.to/45Y3LyI Graph Machine Learning — the latest advancements in graph data to build robust machine learning algorithms. 𝓚𝓮𝔂 𝓕𝓮𝓪𝓽𝓾𝓻𝓮𝓼: Master new graph ML techniques through updated examples using PyTorch Geometric and Deep Graph Library -
Static benchmarks measure memorization, not intelligence
By
–
If your benchmark relies on a static dataset or sampling from a static distribution densely known at training time, then it is fundamentally measuring memorization/retrieval. Which might be fine if you're looking for a retrieval benchmark! But don't confuse it with intelligence.
-

Autodata: An agentic data scientist to create high quality synthetic data
By
–
"Autodata: An agentic data scientist to create high quality synthetic data" If there's auto-research, shouldn't there also be a auto-data generation? In this new Meta paper, they proposed Autodata, which makes synthetic data generation work more like a data scientist, with an