Been here 19 years and your advice is right on. I've been studying the algorithm at quite a deep level. I even built an AI that lets you see the entire AI community in a new way: https://
alginednews.com/ai (AI using the X API builds that entire page from X). The algorithm is
COMPUTING
-
AI-Powered Algorithm Analysis Tool Built on X API
By
–
-
Using AI to Harden and Secure Your Systems Now
By
–
Well you better use AI to harden your systems now then.
-
Google’s Strategic Advantage: TPU Dominance and AI Compute Leadership
By
–
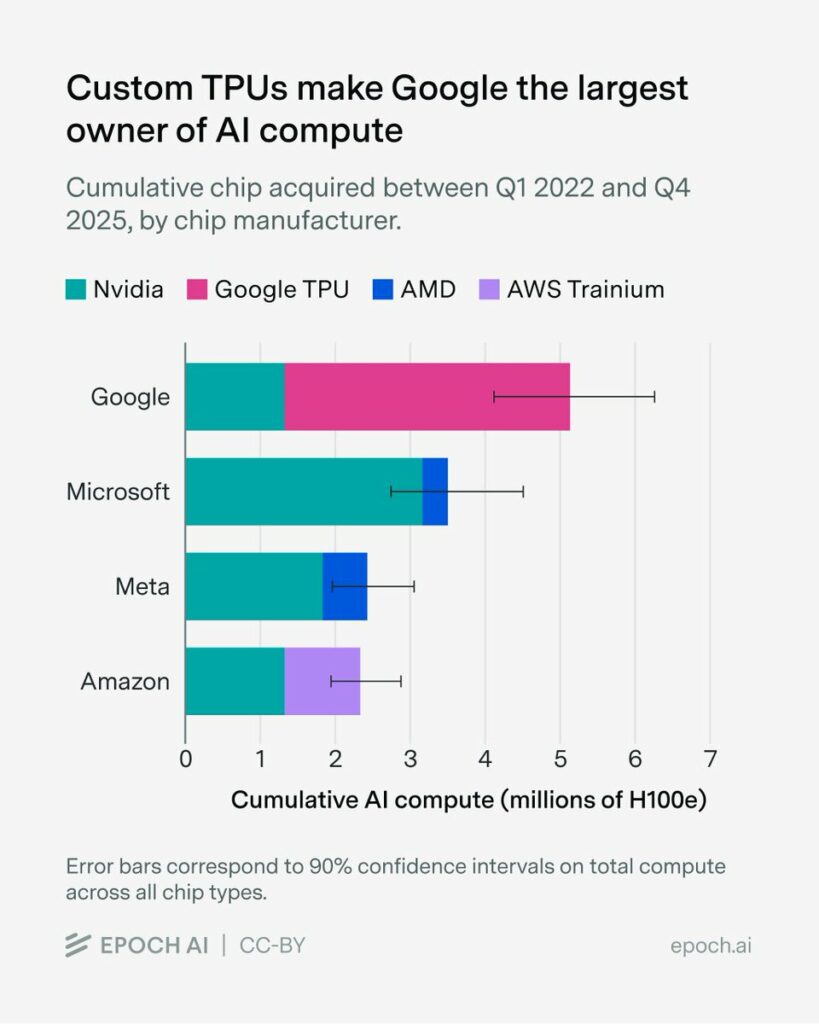
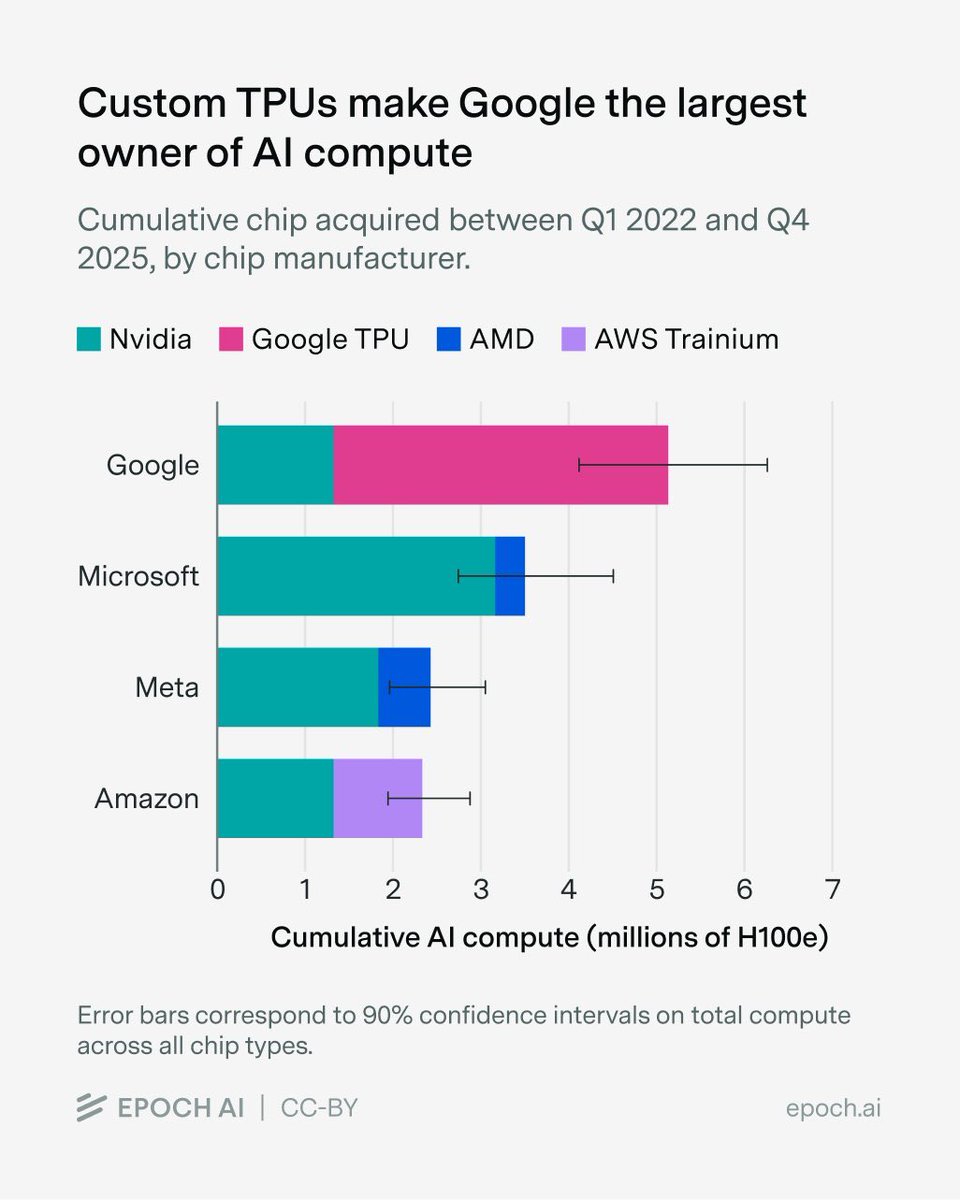
Google had the foresight to develop TPUs back in 2012. Today, they have by far the most compute. In the long term, Google is in one of the best starting positions: a solid revenue and product base, compute, and above all: distribution. Epoch AI (@EpochAIResearch) We estimate that over 60% of global AI compute is owned by the top US hyperscalers, led by Google with the equivalent of roughly 5 million Nvidia H100 GPUs! Unlike the other hyperscalers, which rely primarily on Nvidia, Google’s fleet is dominated by its custom TPU chips. — https://nitter.net/EpochAIResearch/status/2041241217334419851#m
→ View original post on X — @kimmonismus, 2026-04-06 21:13 UTC
-
Hybrid System Achieves 95% Accuracy With Minimal Energy Consumption
By
–
On a planning puzzle, the hybrid system hit 95% accuracy vs. 34% for standard models. Training took 34 minutes instead of 36 hours. Energy use dropped to 1% during training. It didn't just use less power, it got dramatically smarter. [Translated from EN to English]
→ View original post on X — @kimmonismus, 2026-04-06 20:42 UTC
-
AI’s Massive Energy Consumption and Persistent Hallucination Problem
By
–
2/ AI is devouring electricity. Data centers already consume over 10% of U.S. power, and demand is set to double by 2030. Meanwhile, these systems still hallucinate, although its getting more and more correct. However: We're burning city-sized energy budgets.
→ View original post on X — @kimmonismus, 2026-04-06 20:42 UTC
-
AI Agents Transform the Web into Autonomous Platform
By
–
AI is changing the Internet into a platform where you can build literally anything. Travel site? Check. Weather site? Check. An app to watch your favorite sports team? Check. Automatic shopping? Check. And millions of other things. Arlan lays out how to turn the Web into a file system. A new web is here. The autonomous web. Agents are like autonomous vehicles. Get in a Tesla and it will take you to In-N-Out. Or anywhere. It turns the world into a thrill park ride. Same for your agents on the Web. They are like little autonomous vehicles that can do anything. Why do you think the OpenClaw got the nerds so excited? They are building systems to do millions of things automatically on the Web. Where's @timoreilly? He wrote the Web 2.0 memo that gave that its name. Is this Web 4.0? I'd rather call it the autonomous web. How about you? Arlan (@arlanr) x.com/i/article/203981724469… — https://nitter.net/arlanr/status/2041215978957389908#m
→ View original post on X — @scobleizer, 2026-04-06 20:29 UTC
-
Codex Open Source Support Update: Major Projects List
By
–
Codex for open source update! Some of the main projects we’ve supported: – Linux – React – Node.js – Rust – Python / CPython – Kubernetes – Flutter – Electron – Ollama – Dify – Transformers – LangChain – yt-dlp – OpenCV – Home Assistant – Storybook – Astro – vLLM – SGLang – TiDB – Airflow – Superset – Doris – APISIX – Pulsar – RocketMQ – DataFusion – Arrow – SeaTunnel – ShardingSphere – DolphinScheduler – Apache ECharts – Ant Design – Tailwind CSS – Material UI – Svelte – Vue – Solid – Qwik – Hono – tRPC – Prisma – TypeORM – NextAuth – TanStack Query – TanStack Table – Rspack – Biome – Ruff – Docusaurus – Zed – Tauri – Deno – Turso – SQLite Browser – Difftastic – core-js – nvm – pnpm – zoxide – fd – bat – k9s – Harbor – containerd – etcd – Envoy – gRPC – Jaeger – Trivy – Vaultwarden – Firecracker – Gitea – Homebrew Core – Nixpkgs – Julia – Ruby – Rails – Symfony – scikit-learn – PaddlePaddle – Diffusers – Llama Factory – Unsloth – DeepSpeed – DSPy – RAGFlow – MinerU – ComfyUI – Jan – Khoj – LibreChat – Chainlit – LobeHub – GPT Engineer – Browser Use – OpenClaw – Zeroclaw – Plane – Appwrite – Directus – Strapi – Calcom – Metabase – PostHog – Budibase – Documenso – Chatwoot – Logto – Zammad – Discourse – BTCPay Server – Bagisto – ABP – Vitess – TiKV – RisingWave – Milvus – Kong – SigNoz – Manticore Search – JuiceFS – SeaweedFS – Reth – Aptos Core – Ripple – Wormhole – Go Ethereum – Bevy – Godot – PixiJS – Excalidraw – JSON Crack – RSSHub – SiYuan – Logseq – Refined GitHub – Better Auth – OpenPilot – FFmpeg – XBMC / Kodi – MeshCentral – ZMap – Yacy – Zplug – ZipArchive – ZIO – Godoxy – rengine – pyod – node-telegram-bot-api – Avante.nvim – Repomix – Zfile – Vant – Vant Weapp – Yamada UI – WordPress Playground – Gutenberg And a bunch of number of Apache, AI, database, frontend, security, CLI, infra, and devtool projects!
→ View original post on X — @romainhuet, 2026-04-06 20:17 UTC
-

NVIDIA Reduces Token Costs Through Extreme Software Co-Design
By
–
We deliver the lowest token cost through extreme co-design. As NVIDIA software optimizations increase token throughput, the value of your NVIDIA GPUs grows from the moment you invest in them. Learn more ➡️ nvda.ws/4me7HBr [Translated from EN to English]
-
The Ultra-Scale Playbook: GPU Parallelism Strategies for LLM Training
By
–
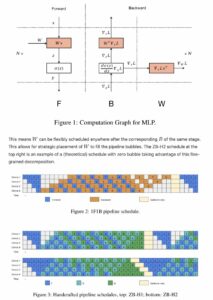


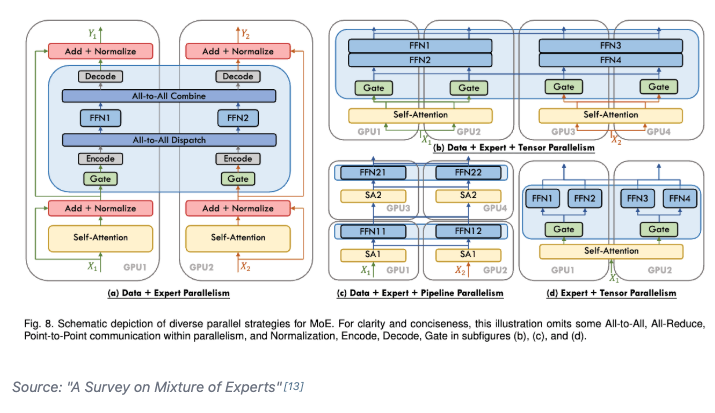
Day 93/365 of GPU Programming Studying parallelism today and stumbled upon this incredible blog post/book The Ultra-Scale Playbook: Training LLMs on GPU Clusters by Hugging Face that dives deep into data parallelism, expert parallelism, tensor parallelism, pipeline parallelism and context parallelism. I've read a bit about each of these methodologies before but this is the best resource I've found that really pieces them all together into a unified coherent picture. Kinda like its name implies, the team goes into actual empirical examples based on the 4000 scaling experiments (across up to 512 GPUs!) they conducted. E.g. how does tensor parallelism reduce activation memory for matmuls but still require gathering full activations for LayerNorm? When does pipeline parallelism's bubble overhead outweigh its memory savings? When and why would you combine TP/PP/DP on a specific cluster topology? What's the real memory breakdown between params, gradients, optimizer states and activations and which parallelism strategy targets which? et cetera Also loved all the beautiful and sometimes interactive diagrams that reminded me of distill.pub (which makes sense given they used distill's template to create the post). I wish more blog posts in ML would use a similar approach to help visual learners understand the content at an intuitive level. Especially now that rich visualizations/animations are so easy to spin up with LLMs. Really wonderful work by @Nouamanetazi @FerdinandMom @xariusrke @mekkcyber @lvwerra @Thom_Wolf. In times when things are going more and more closed source in, this is such a good example of what great open source AI education and research can look like. levi (@levidiamode) Day 92/365 of GPU Programming Taking a closer look at disaggregated LLM inference today, which I've been wanting to survey more after listening to the Dean <> Daly discussion at GTC. The best resource I found on the topic was this great talk by @Junda_Chen_ on the past, present and future of prefill decode disaggregation. In the lecture, Junda goes through Nvidia's dynamo, the intrinsic tradeoff spectrum between throughput & latency, TTFT, TPOT, the "goodput" metric, distinct characteristics between prefill vs decode, chunking P&D, the problem of interference, pipeline parallelism, resource & parallelism coupling, disaggregation and DistServe. — https://nitter.net/levidiamode/status/2040938107604742640#m
→ View original post on X — @thom_wolf, 2026-04-06 18:58 UTC
-

Test-Time Scaling Makes Overtraining Compute-Optimal
By
–
Most scaling laws assume you train once and answer once. But this paper says that if you already know you'll spend extra compute at test time by sampling many answers, then you should train a different model. So instead of a bigger model trained the usual way, it can be better to train a smaller model for much longer. As smaller models are cheaper to sample many times, those extra tries can beat one expensive shot from a larger model. So the real thing to optimize is not just training compute, but training + inference together. And this paper shows overtraining can actually become the compute-optimal choice. [Translated from EN to English]
→ View original post on X — @askalphaxiv, 2026-04-06 18:08 UTC