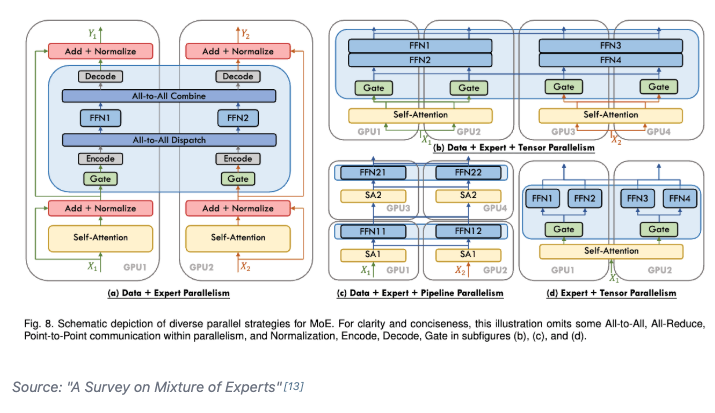
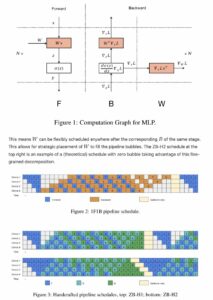


Day 93/365 of GPU Programming Studying parallelism today and stumbled upon this incredible blog post/book The Ultra-Scale Playbook: Training LLMs on GPU Clusters by Hugging Face that dives deep into data parallelism, expert parallelism, tensor parallelism, pipeline parallelism and context parallelism. I've read a bit about each of these methodologies before but this is the best resource I've found that really pieces them all together into a unified coherent picture. Kinda like its name implies, the team goes into actual empirical examples based on the 4000 scaling experiments (across up to 512 GPUs!) they conducted. E.g. how does tensor parallelism reduce activation memory for matmuls but still require gathering full activations for LayerNorm? When does pipeline parallelism's bubble overhead outweigh its memory savings? When and why would you combine TP/PP/DP on a specific cluster topology? What's the real memory breakdown between params, gradients, optimizer states and activations and which parallelism strategy targets which? et cetera Also loved all the beautiful and sometimes interactive diagrams that reminded me of distill.pub (which makes sense given they used distill's template to create the post). I wish more blog posts in ML would use a similar approach to help visual learners understand the content at an intuitive level. Especially now that rich visualizations/animations are so easy to spin up with LLMs. Really wonderful work by @Nouamanetazi @FerdinandMom @xariusrke @mekkcyber @lvwerra @Thom_Wolf. In times when things are going more and more closed source in, this is such a good example of what great open source AI education and research can look like. levi (@levidiamode) Day 92/365 of GPU Programming Taking a closer look at disaggregated LLM inference today, which I've been wanting to survey more after listening to the Dean <> Daly discussion at GTC. The best resource I found on the topic was this great talk by @Junda_Chen_ on the past, present and future of prefill decode disaggregation. In the lecture, Junda goes through Nvidia's dynamo, the intrinsic tradeoff spectrum between throughput & latency, TTFT, TPOT, the "goodput" metric, distinct characteristics between prefill vs decode, chunking P&D, the problem of interference, pipeline parallelism, resource & parallelism coupling, disaggregation and DistServe. — https://nitter.net/levidiamode/status/2040938107604742640#m
→ View original post on X — @thom_wolf, 2026-04-06 18:58 UTC