It is truly astonishing to see the entire field evolving in the neurosymbolic and world model directions that I advocated in 2019 and 2020, and simultaneously to observe people claiming (inevitably without specific evidence) that I am still wrong.
AGI
-
Global cognitive models have finally come of age
By
–
six years ago world (cognitive) models were the centerpiece of my essay The Next Decade in AI.
— Gary Marcus (@GaryMarcus) 23 mai 2026
their time is finally coming. https://t.co/VdnPWajZckSix years ago, global (cognitive) models were at the heart of my essay *The Next Decade in AI*. Their time has finally come.
-
LLMs as Philosophical Zombies: Consciousness Debate
By
–
A lot of people are arguing that LLMs are philosophical zombies
-
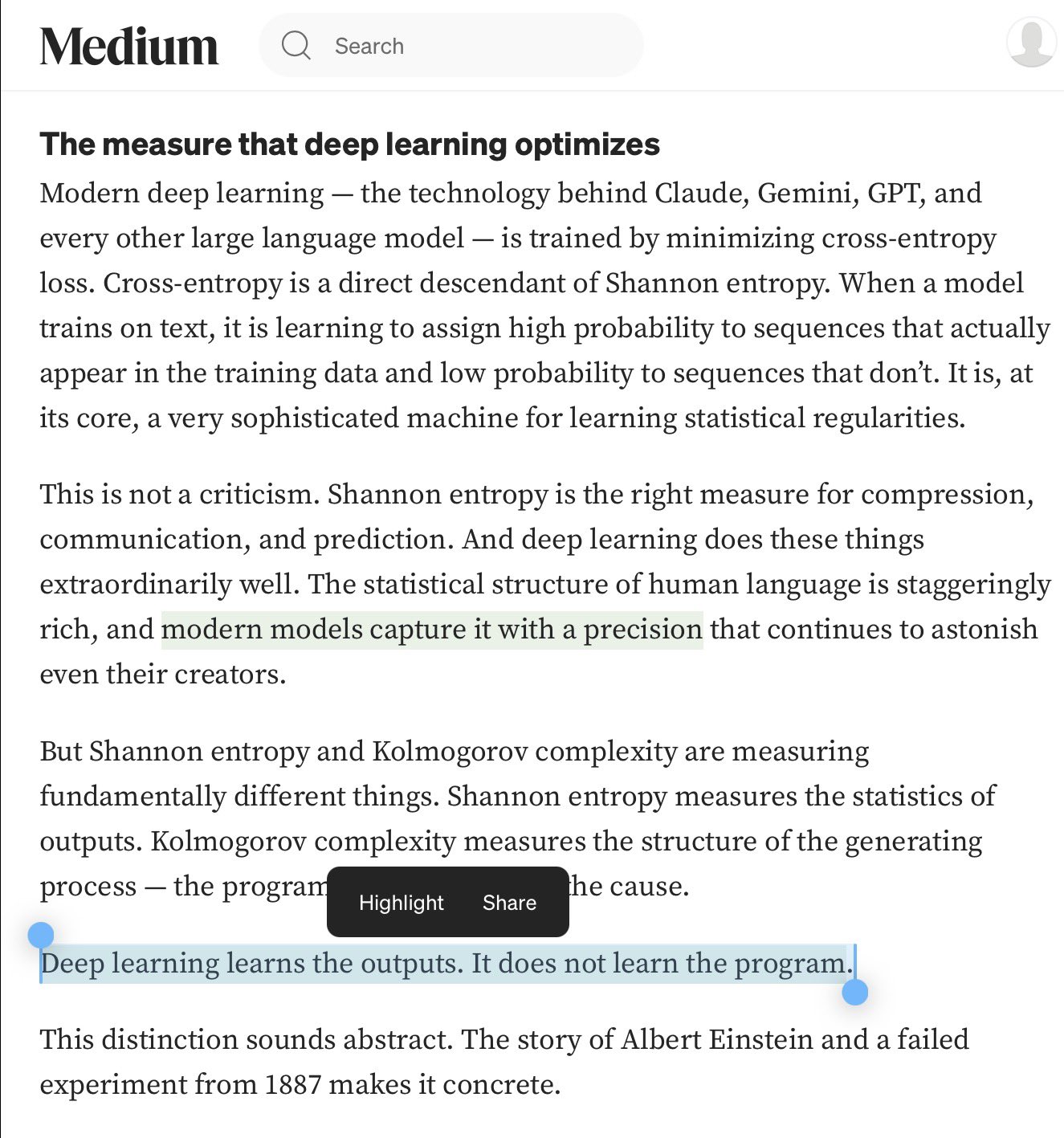
Transformer Learning Frameworks and Adversarial World Models
By
–
co-sign. a very handy mental framework for what kinds of learning transformers do well today, and why it runs into limitations. when @ankit2119 and i wrote about the need for adversarial world models earlier this year, we were describing a couple of the functions of these rungs
-
Demis says Singularity few years away, AGI transformative technology
By
–
Demis says the Singularity may now be only a few years away, potentially set in motion by the arrival of true AGI.
— Chubby♨️ (@kimmonismus) 23 mai 2026
"Its being so transformative, it will be the most important technology ever" pic.twitter.com/5VOBLc8Eh8Demis says the Singularity may now be only a few years away, potentially set in motion by the arrival of true AGI. "Its being so transformative, it will be the most important technology ever"
-
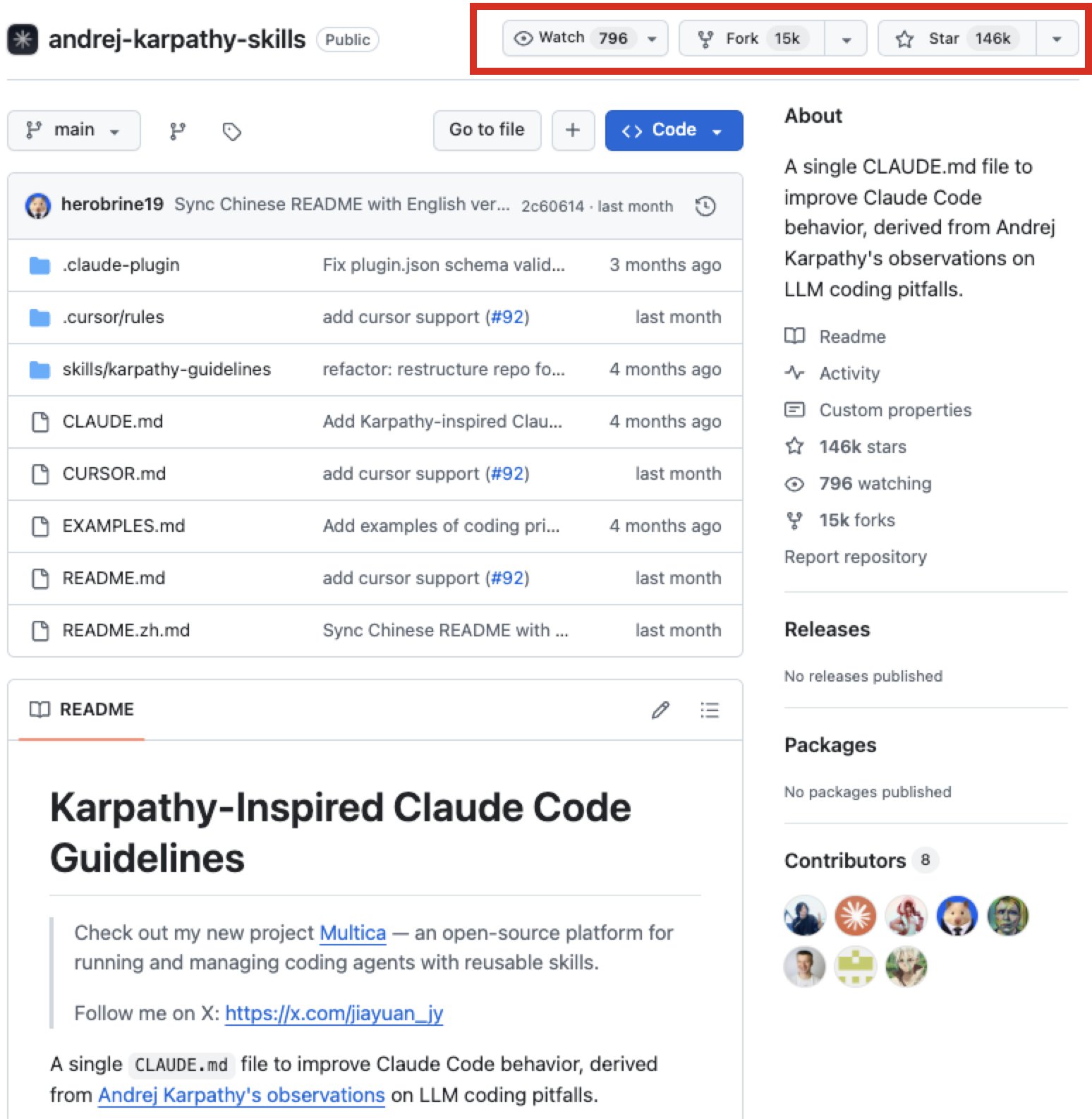
Claude MD File: Top GitHub Repo Uses Karpathy’s 4 LLM Principles for AI Control
By
–
DID YOU KNOW THE #1 GITHUB TRENDING REPO (146K+ STARS) IS LITERALLY JUST A CLAUDE MD FILE? It uses @karpathy
's 4 LLM principles to keep AI in check: → Seek clarity: Always ask before making assumptions.
→ Stay minimal: Avoid bloat and keep things simple.
→ Edit -

Codex’s AI capabilities on macOS showcased
By
–
Watching Codex use a Mac that’s fully locked feels slightly impossible the first time you see it. Apple built trusted foundations on macOS for this years ago. Codex is now shipping something magical on top of them!
-
GigaAI’s Maker H01 Robotics Debut
By
–
Wheels Meet #AI: GigaAI’s Maker H01 Is Here
— Ronald van Loon (@Ronald_vanLoon) 22 mai 2026
by @CyberRobooo#Robotics #Engineering #Innovation #Technology pic.twitter.com/4YYpqvqCGUWheels Meet #AI: GigaAI’s Maker H01 Is Here
by @CyberRobooo #Robotics #Engineering #Innovation #Technology -
AI simulates human conversation and thought patterns
By
–
It can even simulate me. "Simulate a conversation between Robert Scoble and Elon Musk about the future of brain/computer interfaces." And it can tell you, quite accurately, how I think. The last thing it doesn't know is my bank account password. Yeah, that matters. 🙂
-
Open Source Deep Research for Agent Harnesses with AI-Q Skills
By
–
Say hello to open source deep research for your favorite agent harness.
— NVIDIA AI (@NVIDIAAI) 22 mai 2026
Our AI-Q agent skill packages the work of building a research pipeline into a portable skill. Drop it into your harness, and the agent delegates a research task to a local or hosted AI-Q server and gets back… pic.twitter.com/u7tVWvCUWdSay hello to open source deep research for your favorite agent harness. Our AI-Q agent skill packages the work of building a research pipeline into a portable skill. Drop it into your harness, and the agent delegates a research task to a local or hosted AI-Q server and gets back