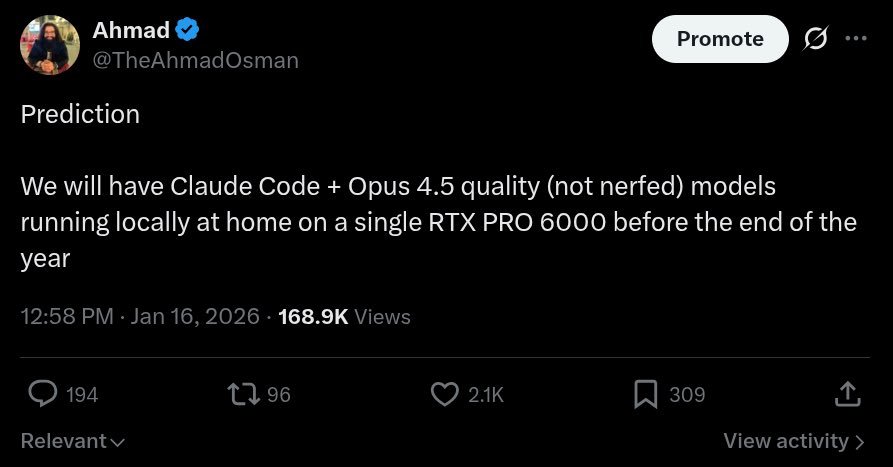
To avoid this EVER happening again Because WE CANNOT trust them Opensource AI MUST WIN Opensource AI will win.
@theahmadosman
-
Google accused of lazy benchmaxxing of models
By
–
Nah, thankfully Google is lazy and just benchmaxxing their models at this point
-
Gentle reminder: Anthropic and OpenAI are not your friends
By
–
Gentle reminder Anthropic & OpenAI are not your friends Dario and Sam Altman are mercenaries who would love for no one else but themselves to control that blackbox we call AI Don’t let PR campaigns & limit resets make you forget that they have every intention of rugpulling you
-
OpenClaw: a weird, fleeting phase in LLM history
By
–
OpenClaw was such a weird phase in LLMs Glad that thing disappeared as fast as it took the spotlight
-
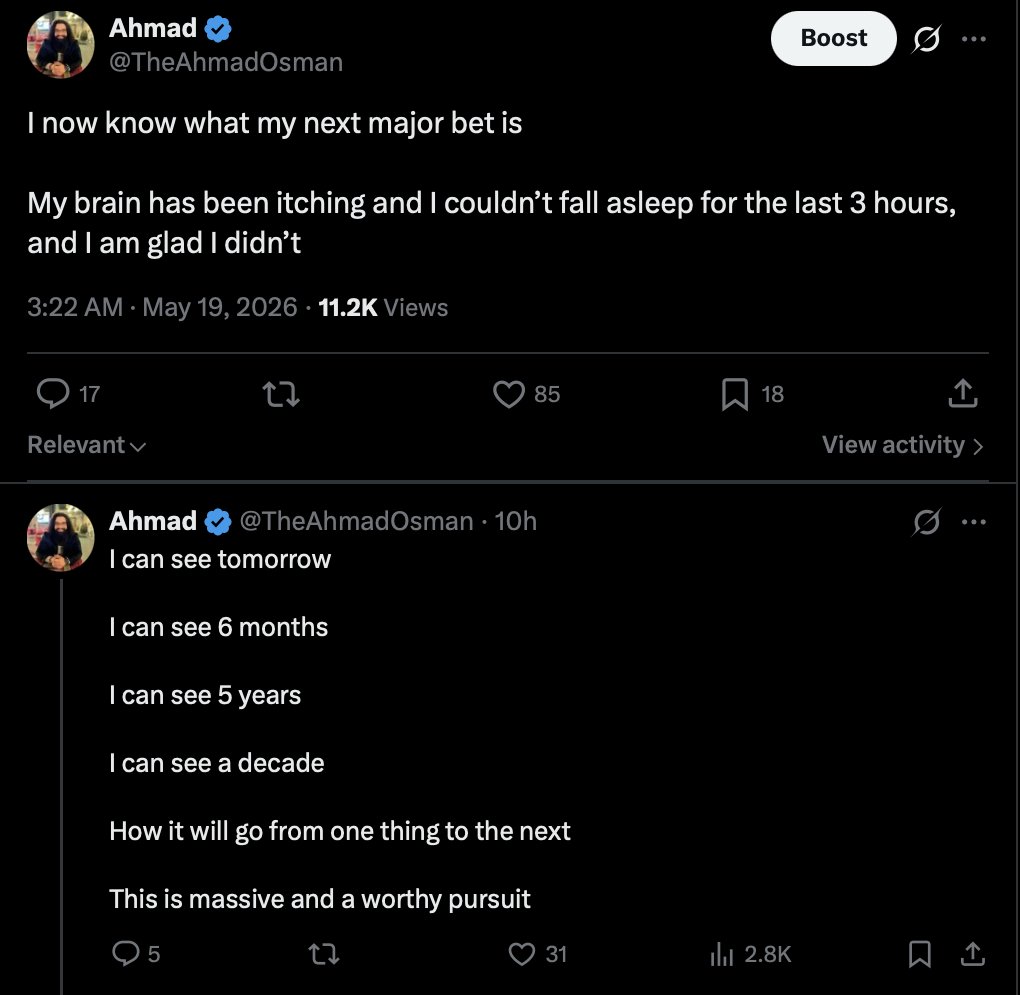
Making Local AI effortless eliminates subscription and API limit fears
By
–
I am gonna make Local AI so easy people are gonna wonder why they were so worried about subscriptions and API limits
-
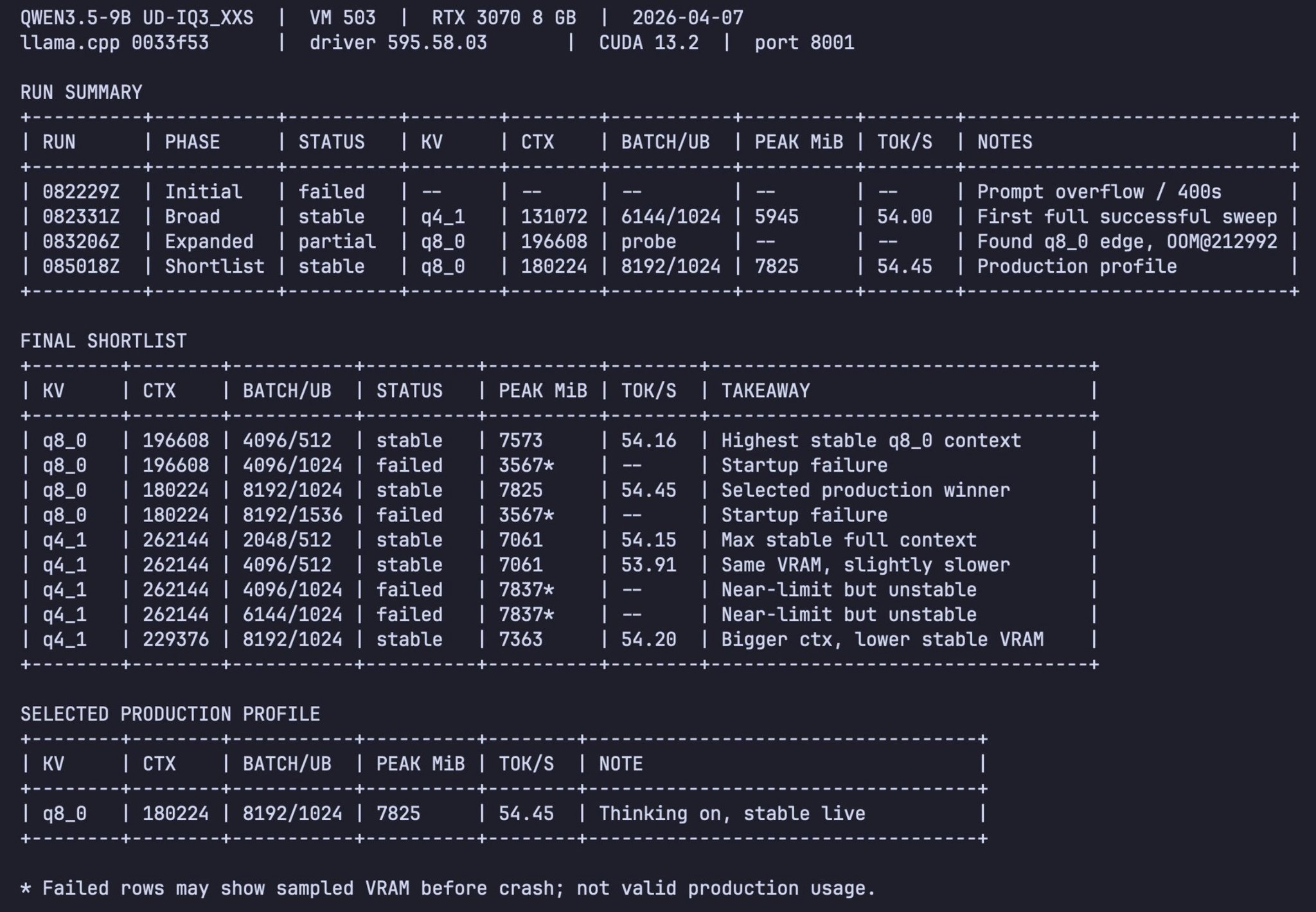
Codex Cli Makes Local AI Effortless: Hardware, Model & Performance Optimization
By
–

Local AI Is Now Easy With This Give Codex Cli the article below & tell it: – Infer the right Inference Engine from your hardware + article below
– Use uv+venv
– Pick the right kernels
– Tune flags, batching, KVCache, etc
– Optimize for your hardware & chosen model See? SO EASY -

Educational thread on Local AI covering software, hardware, and infrastructure
By
–
BTW, I have an entire thread with all of my educational content on Local AI Covers everything from Software to Hardware to Infrastructure & Systems Design for running AI locally You absolutely should check it out as well for the bigger picture
-

Free online bible for running LLMs locally on any hardware
By
–
DROP EVERYTHING The bible for running LLMs locally is now available online to read for free Covers what to use on – Laptop / edge / odd hardware
– Mac-first workflows
– Single RTX GPUs
– 2-4+ NVIDIA / CUDA GPUs
– General production serving
– Long-context / MoE / routing
– -

Understanding Inference Engines for Local AI Model Deployment
By
–

Inference Engines and why they matter when you're running models locally High-level overview article that, in my honest opinion, should be read by everyone in tech Let me know if you have questions / requests for next one
-
A Guide to Setting Up Local AI Environments
By
–
Gentle reminder that all you need to start with Local AI is: – 2x RTX 3090s (pick up for $700-$900 on r/hardwareswap) – Qwen 3.6 27B / Gemma 4 31B – Your favorite agent (Claude Code / OpenCode / etc) – Self-hosted SearXNG for web access And you got yourself Opus 4.5 at home