No, I am saying that this is the equivalent of TikTok brain rot for Local AI Longest prompt was 368 tons, longest output was 3k and some grifters out there are saying that this is great results of 45tok/s lol If you cannot see how this is performative slop / grifting then
@theahmadosman
-
Sarcastic commentary on short prompt and costly hardware
By
–
I mean, dude's longest prompt was 368 tokens and longest output was 4k He's literally crying next to that hardware and hoping to get enough engagement that elonbux can pay for his next month installment on those desk warmers
-
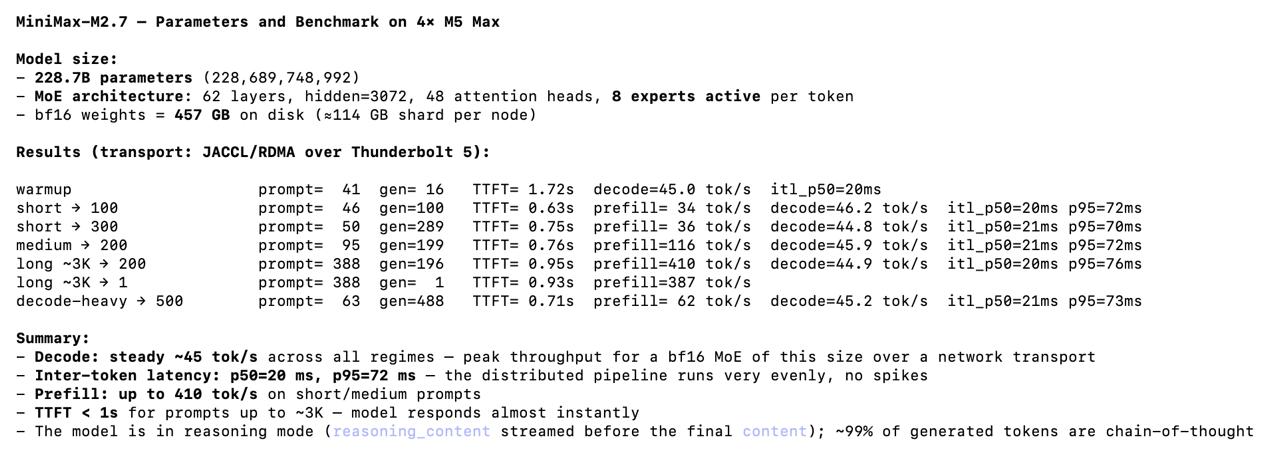
Expensive MacBooks run MiniMax with low performance and limited context
By
–

Good example of Performative Inference / Local AI grifting MiniMax-M2.7 on 4x M5 Max MacBooks (~$22,000 USD) – Longest prompt: 338 (???) – Max context: ~3k (???) – 45 tok/s (lol) – Single prompt, no parallel requests Some of the funniest & stupidest shit I've ever seen
-

Qwen 3.5 27B: Buy RTX 3090s or Stay Underclass
By
–
If you saw Qwen 3.5 27B and didn’t see that as a chance to ensure the permanent underclass semi-joke never happens to you (by simply purchasing a couple of RTX 3090s) I am sorry to say but you ngmi
-
Criticism of corporations banning open-source AI and hardware ownership
By
–
At least people could cook and drive their own cars before DoorDash / Uber These corporations are trying to hard to ban opensource AI and you from owning a piece of hardware that lets you run a similar model independent of them If you cannot see how this is so evil you ngmi
-

Subsidized token industry ending, users still ignore local models
By
–
How it feels to know that the subsidized token industry is coming to an end and people are still not worrying about the right thing (running the models locally on your own compute) No more free DoorDash deliveries / $5 Uber trips for you (after they got you addicted)
-
Disappearance of instant, thinking, pro and effort levels
By
–
You had instant, thinking, pro, etc and then each had the ability to specify their effort levels (4 levels) All of that is gone lol
-
User angry at OpenAI for enforcing router model selection on paid subscription
By
–
OpenAI, what the fuck is this? Give me back the ability to specify WHICH MODEL I am using + their effort levels EXPLICITLY I don't want this router crap you're enforcing on my $200 paid subscription I DID NOT AGREE TO THIS SHIT
-
Skills enable deterministic execution for parallel model usage
By
–
Skills can allow you to have deterministic execution patterns, so I have a lot of minimal harnesses for repeated tasks, that way I can control outcome no matter what model I use This is extremely helpful if you have multiple endpoints / models that you want to run in parallel
-

Complete guide to understanding LLMs from first principles free online
By
–
INCREDIBLE The MOST COMPLETE GUIDE for understanding LLMs from first principles is now available online to read for free Covers the model mechanics – Tokens / tokenizers
– Transformers
– Attention
– KV cache
– Prefill vs decode
– Decoding controls
– Model packages
– Chat