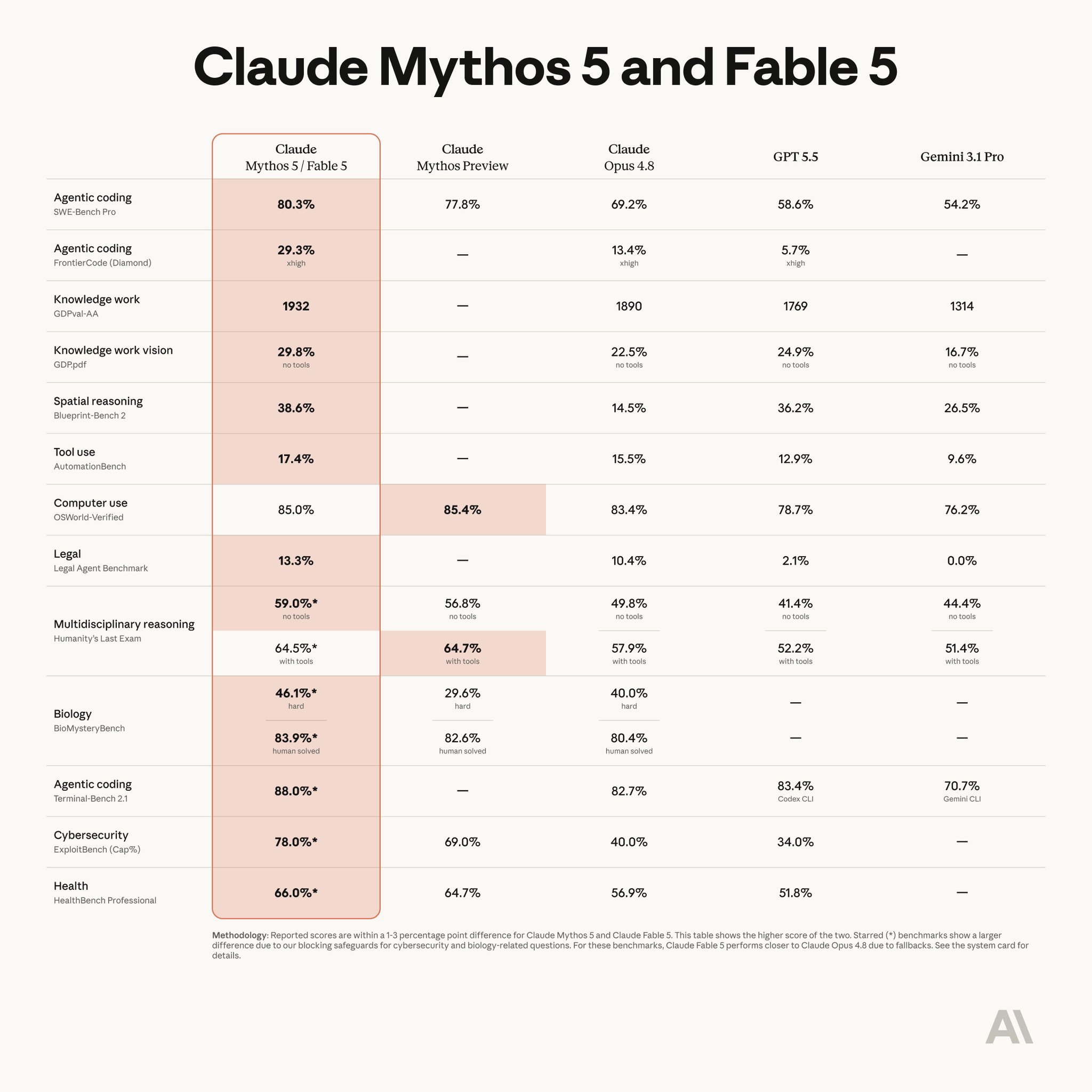
This is a super exciting release – Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward
@karpathy
-
Researcher joins Anthropic to work on frontier LLM R&D
By
–
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
-
Technical challenges in deploying H100 clusters for AI development
By
–
I was recording my nanochat video when I realized that “first boot up an 8XH100 from your favorite provider!” would instantly get everyone stuck on step 1 of the video
-
FDM1 Scales VPT Idea for Knowledge Work and Computer Use
By
–
VPT (
https://
openai.com/index/vpt/) blew my mind back in 2022 so I was very excited to see SI scale up the idea with FDM1, but for knowledge work / computer use. Excited and looking forward to more! -
LLMs Enable New Horizons Beyond Coding Acceleration
By
–
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
— Andrej Karpathy (@karpathy) 30 avril 2026
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by… https://t.co/AJFgYC6SoNFireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights: The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons: 1. menugen: an app that can be fully engulfed by
-
Cozy Coding: Programming Together with Love
By
–
Haha yeah I call it cozy coding 🙂
Usage: “This valentines, cozy code with someone you love” -
Enneagram Type Fives and LLM Knowledge Base Psychosis
By
–
Yeah I've seen it a few times now, all the Enneagram type fives get one shotted into AI psychosis when they discover LLM knowledge bases 🙂 And an especially a strong fit when you have a lot of pre-existing data to insert into it.
-
Company conducts optimized questionnaire for consciousness upload fidelity
By
–
No the company physically gets you to come in, sits you down and asks you a precise set of maximally informative questions specifically designed for the best upload fidelity.
-
LLM Simulation Path Outperforms Neuroscience Adjacent Philosophy
By
–
These neuroscience adjacent ideas are exotic armchair philosophy when the LLM simulation path will work really well and so much faster and it's not even remotely a contest.
-
Brain Upload via LLM Simulators: Near-term Tractable Alternative
By
–
Yes it's the tractable form of brain upload. There's a ton of scifi on brain uploads that requires way too exotic tech (scanning and simulating brains etc), when we're about to get a lossy and approximate version of that *a lot* sooner via LLM simulators. You can easily imagine a