The study cited in the article that I considered a wake-up call found a 13-fold risk of cardiac mortality with 1 inflamed artery, which rose to nearly 30-fold when all 3 arteries were inflamed, as determined by AI of non-invasive CT angio imaging https://
thelancet.com/article/S0140-
6736(24)00596-8/fulltext
…
@erictopol
-
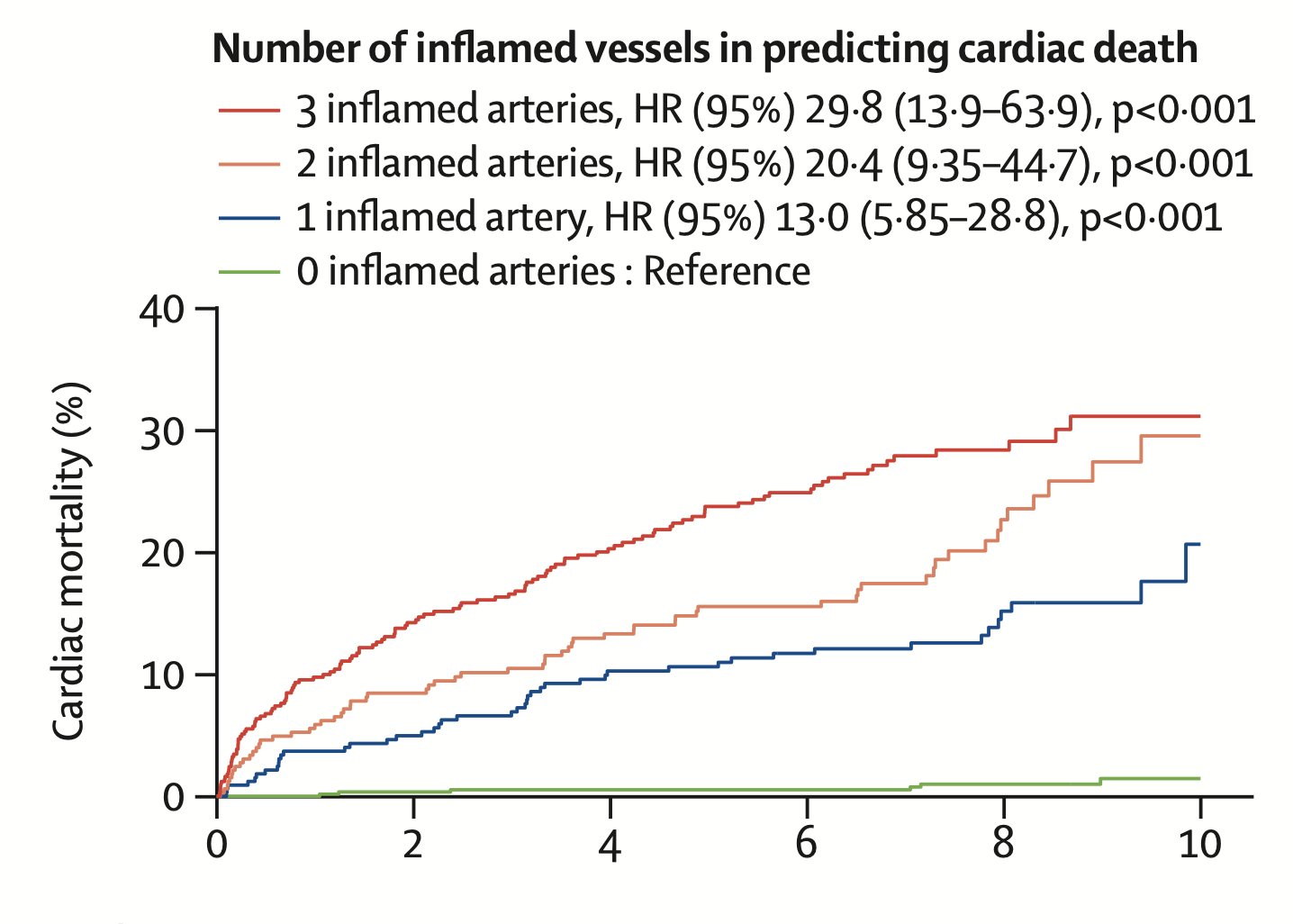
AI-detected artery inflammation dramatically increases cardiac mortality risk
By
–
-
Annual AI copilot screening saves $1.32M and gains 14.73 QALYs per 100k
By
–
A cost-effectiveness assessment of using AI in disease screening (modeling)
"Implementing an annual ‘copilot’ strategy in all ages would save US$1.32 million while gaining 14.73 quality-adjusted life years over a lifetime [per 100,000 people]"
"Our findings demonstrate the -
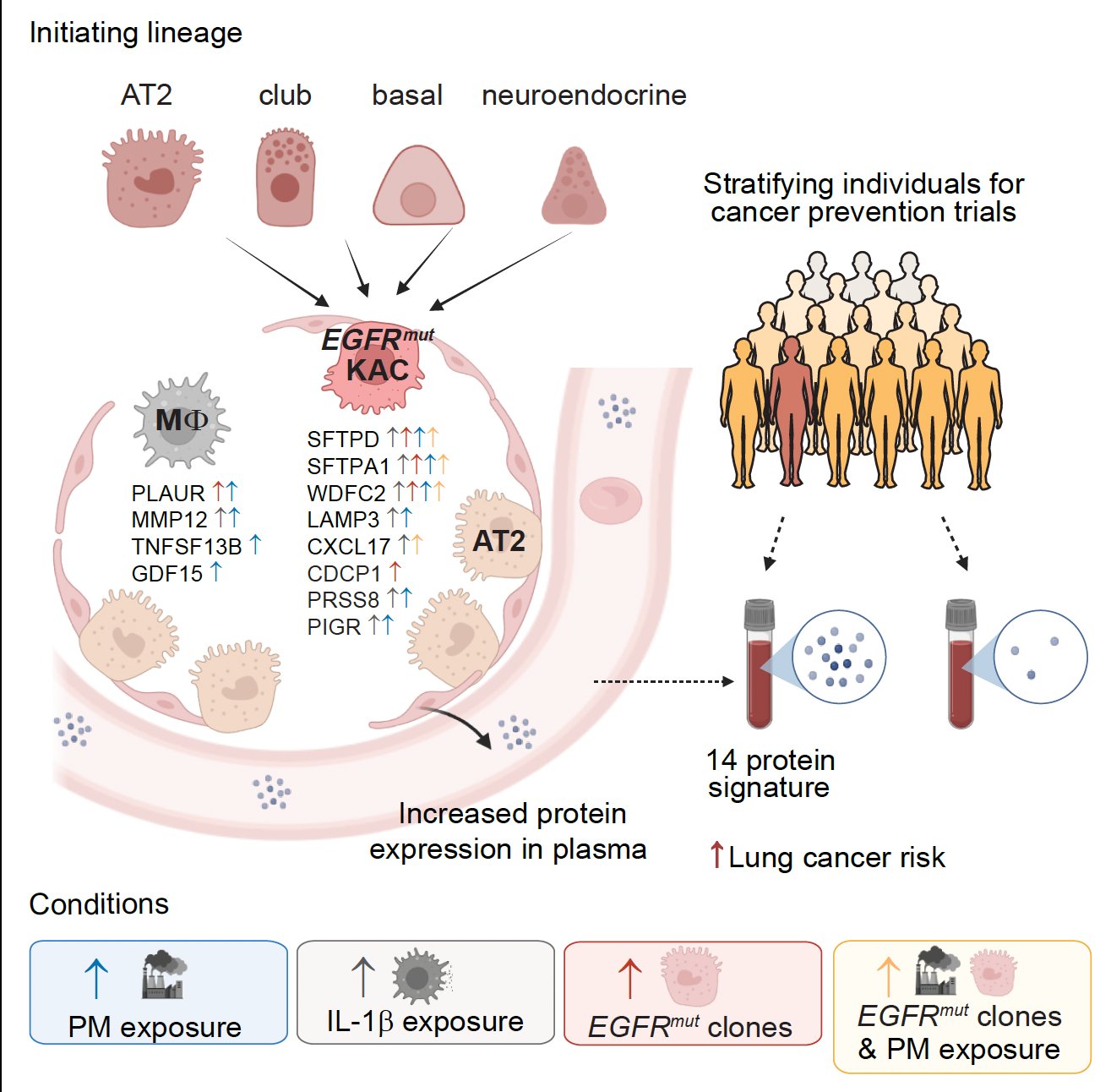
Machine learning identifies 14-protein signature predicting lung cancer risk and therapy response.
By
–
A very impressive study for how we could prevent lung cancer more than 5 years before it is diagnosed. Using machine learning, discovery of a 14-plasma protein signature of risk that predicts responsiveness to an antibody therapy to interleukin, IL-1β
Validated across 8 cohorts -
Administration working on pathway to regulate independent AI doctors
By
–
"Administration figures are working a pathway to regulate independent AI doctors." by @lizzadwoskin gift link https://
wapo.st/4x74KaP -
Inverse Care Law: Medical AI risks exacerbating health inequities
By
–
The Inverse Care Law. The people who need medical care the most tend to get the least access.
It will take deliberate and extensive efforts for medical AI not to exacerbate health inequities, by @ejosipcar We've seen some examples where AI reduced inequities and need to build -

AI-Driven Medical Scan Analysis for Disease Prevention
By
–
Using AI of a medical scan to achieve primary prevention of disease over the next decade in people at high-risk @ScienceTM https://
science.org/doi/10.1126/sc
itranslmed.ady7414
… -
Nature Editorial on the Role and Impact of AI Scientists
By
–
Important editorial @Nature on the new "AI-scientist" papers
"AI scientists can and should empower human
researchers. They cannot and should not replace them." https://
nature.com/articles/d4158
6-026-01551-3
… -
AI MouseMapper: Whole-body 3D model assesses cell-level perturbations across systems
By
–
An AI foundation whole-body 3D model that assesses perturbations (such as obesity) across multiple systems (such as immune, neural) at the cell level. This is MouseMapper. Imagine HumanMapper someday @Nature @erturklab https://t.co/jsg3VMzOqg pic.twitter.com/tktuINis2W
— Eric Topol (@EricTopol) 20 mai 2026An AI foundation whole-body 3D model that assesses perturbations (such as obesity) across multiple systems (such as immune, neural) at the cell level. This is MouseMapper. Imagine HumanMapper someday @Nature @erturklab https://
nature.com/articles/s4158
6-026-10535-2
… -
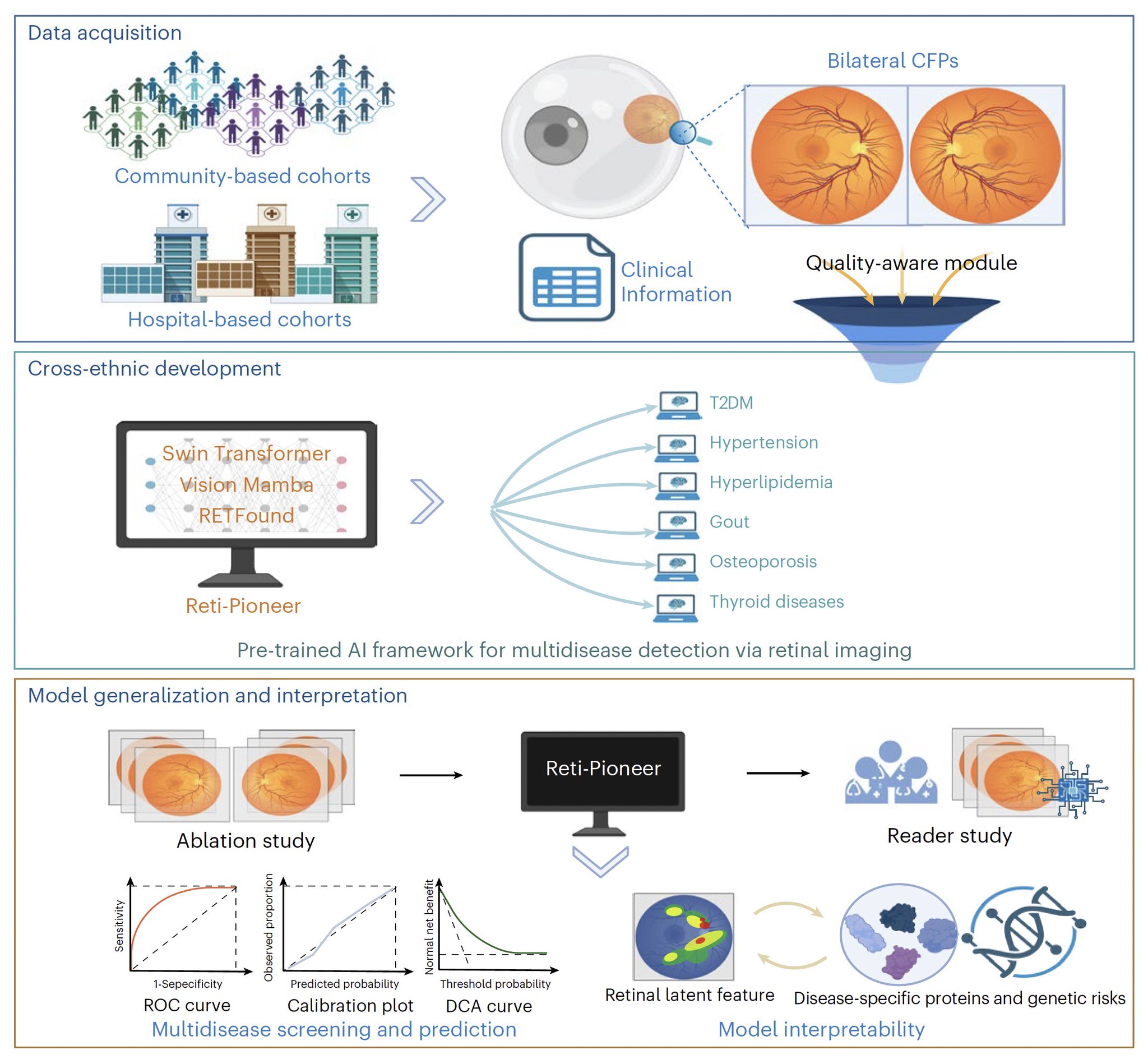
AI tool enables rapid screening for multiple systemic diseases using retinal photos
By
–
“The [AI] tool presented here will enable rapid screening for multiple systemic diseases using retinal photographs, and it is a step forward in the evolution of oculomics from experimental research to real-world clinical practice.” —Editorial Team, @NatureMedicine
-
Study finds modern AI models achieve 50% pass rate on Turing test
By
–
A paper published @PNASNews today: "three current AI systems achieve a pass rate of at least 50% in a standard Turing test"
The systems were GPT-4o, LLaMa-3.1, and GPT-4.5
All over 1-2 years old.