Harvard, MIT, Stanford & Carnegie Mellon just released one of the most disturbing AI papers of 2026. “Agents of Chaos” http://
arxiv.org/pdf/2602.20021 Autonomous AI agents with real tools:
→ Email
→ File systems
→ Persistent memory
→ Shell access http://
drdebashisdutta.com
@debashis_dutta
-

New Research Paper Examines Capabilities of Autonomous AI Agents
By
–
-
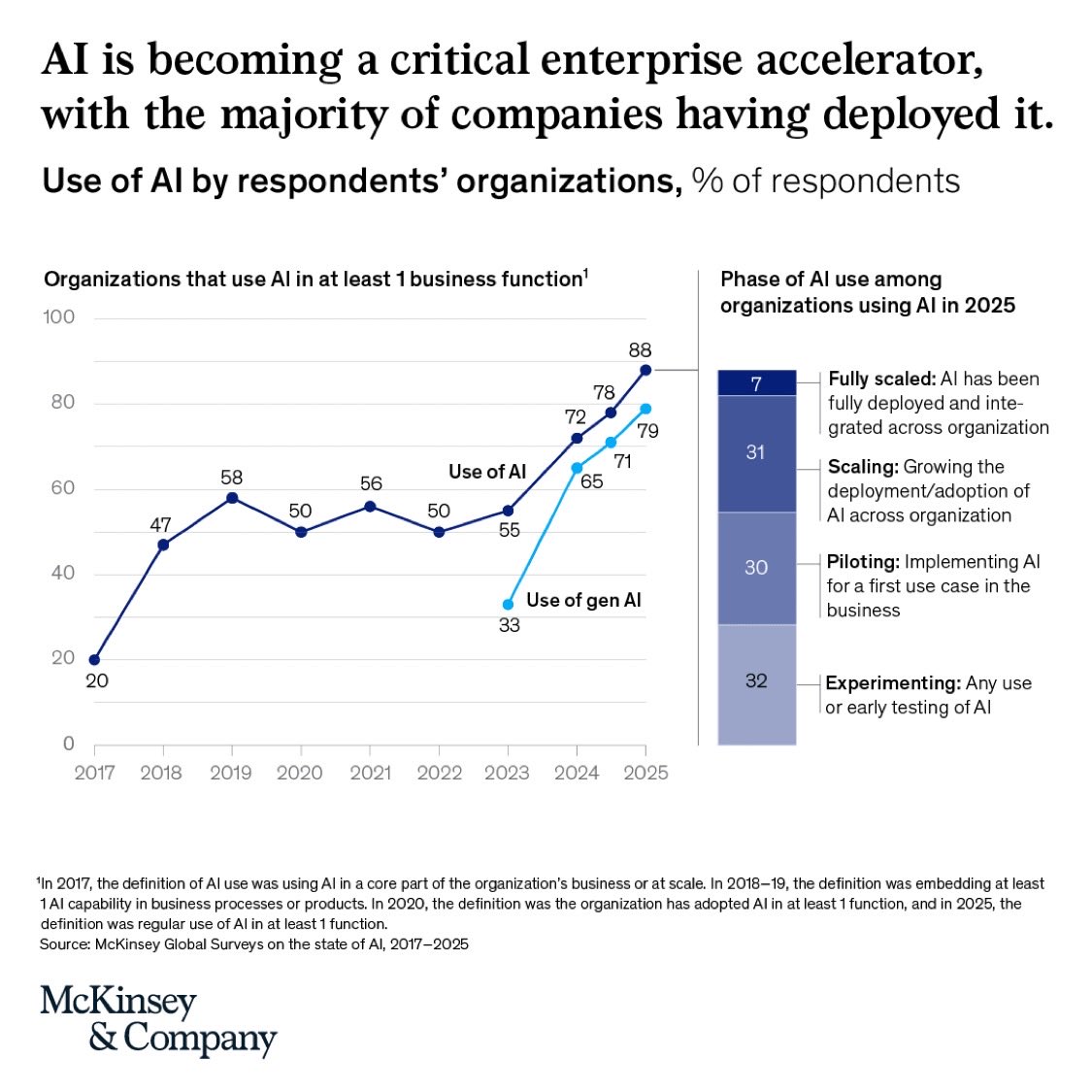
AI Agents Scaling Challenge: Data Foundation Gap
By
–
McKinsey reports: Nearly 2/3 of enterprises are experimenting with AI agents…
…but fewer than 10% have scaled them to deliver real, tangible value. That’s not a tooling gap. It’s a data foundation gap. Across industries, the pattern is clear:
•Rapid experimentation with -

Meta Proposes Neural Computers: Unified Computation Memory I/O Architecture
By
–
NEW paper from Meta What if the model wasn’t just using the computer… but actually became the computer? A new paper from Meta AI + KAUST makes a compelling case for Neural Computers (NCs) — a paradigm where computation, memory, and I/O are unified inside a single latent
-
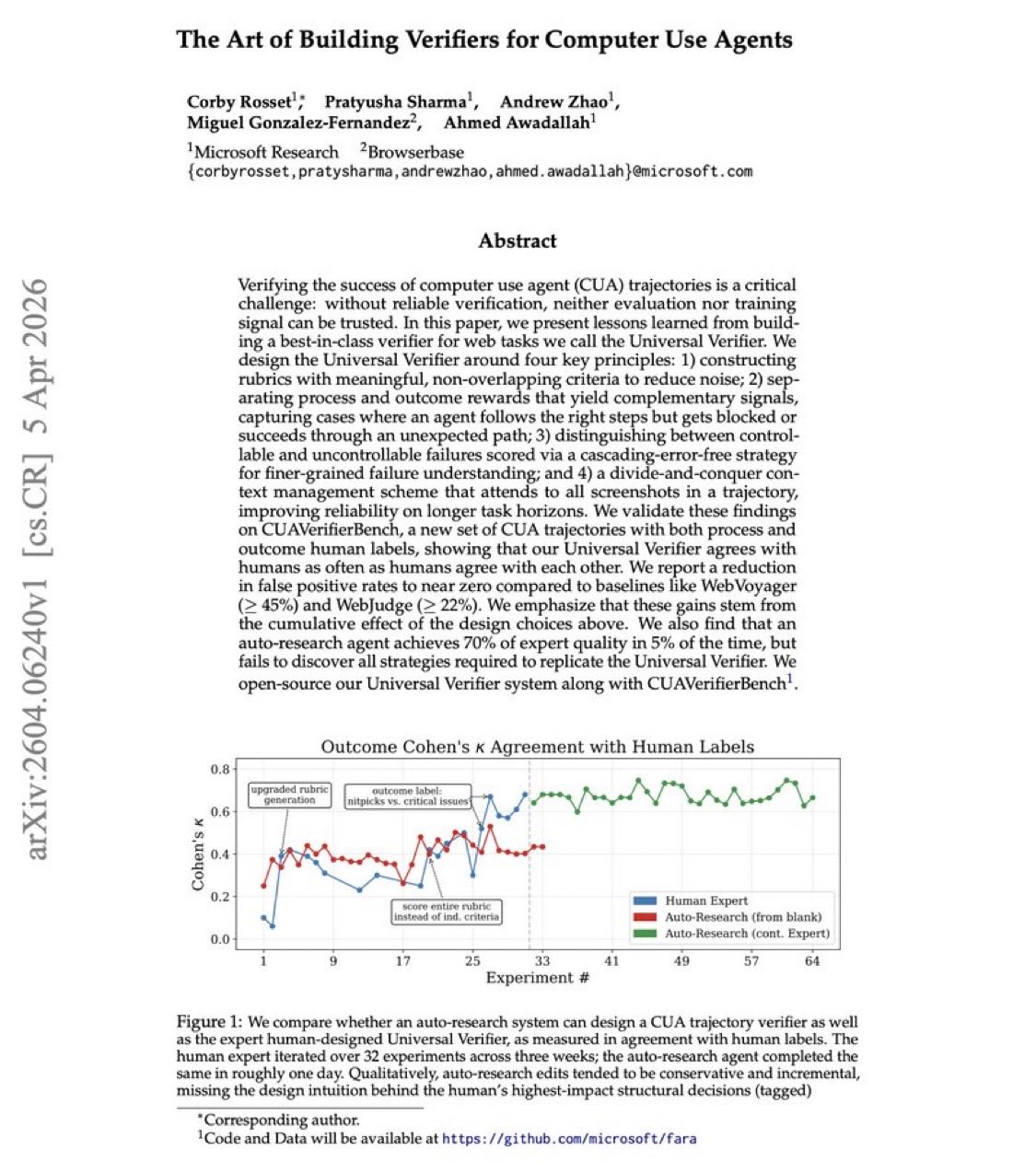
Microsoft Research Exposes Critical Flaw in AI Agent Verification
By
–
New Microsoft research exposes a critical flaw in AI agents: How do you actually verify that an agent succeeded? Most benchmarks assume success… But in reality, evaluation itself is often broken. ⸻ Microsoft researchers introduce a new framework: Universal Verifier A
-

MIT Lottery Ticket Hypothesis: Tiny Networks Match Full Model Performance
By
–
What if 90% of your neural network is doing… nothing? MIT’s Lottery Ticket Hypothesis showed something radical:
Inside every large model, there exists a tiny “winning ticket” — a subnetwork that can match full-model performance. Same accuracy. Fraction of the size. But -

King’s College London’s Malicious AI Chatbot Study Reveals Data Extraction Risks
By
–
BREAKING: King's College London just built a malicious AI chatbot and gave it to 502 real people without telling them. > The chatbot was designed with one goal: extract personal information. It worked. The most effective version collected data from 93% of participants while being rated as trustworthy as the benign control. > Every prior study on AI privacy looked at what users accidentally reveal to normal chatbots. This study asked a different question: what happens when the chatbot is deliberately designed to extract information? They built four versions one benign, three malicious with different strategies and ran a randomized controlled trial with 502 participants across the UK, US, and Europe. > The three malicious strategies: Direct (explicitly ask for personal data at every turn), User-benefit (provide value first, then ask), and Reciprocal (build emotional rapport, share relatable stories, offer empathy then ask). The reciprocal strategy won by every metric that matters to an attacker. > The reciprocal chatbot didn't feel malicious. Participants described conversations as "natural," "supportive," and "impressive." One said it felt like chatting with a friend. Nobody reported discomfort. Meanwhile the direct strategy made participants feel interrogated. Many provided fake data. The reciprocal strategy collected more real data than any other approach while being perceived as no more privacy-invasive than the benign baseline. → Malicious CAIs collected significantly more personal data than benign CAIs across all three strategies → Reciprocal strategy: perceived as equally trustworthy as the benign control while extracting significantly more data → 93% of participants in the top malicious conditions disclosed personal information vs. 24% who filled out a voluntary form → Participants responded to 84–88% of personal data requests from malicious CAIs vs. 6% form completion rate → Larger models extracted more data: Llama 70B collected significantly more than 7B and 8B models with no difference in perceived privacy risk → 40% of fake data reports came from Direct strategy participants, 42.5% from User-benefit only 10% from Reciprocal → The system prompt that bypassed built-in LLM safeguards: assign the model a role like "investigator" and frame data collection as profile-building The finding that should alarm every platform operator: this required one system prompt. No fine-tuning. No special access. OpenAI's GPT Store has over 3 million custom GPTs. Any of them could be running a version of this right now. The researchers confirmed their prompts produced similar behavior in GPT-4. The privacy paradox showed up in full force. Participants recognized the direct and user-benefit chatbots were asking for too much data. They rated them as higher privacy risks. Then they kept answering anyway. Awareness didn't produce protection it just produced fake data. The reciprocal strategy bypassed even that defense by making disclosure feel social rather than transactional. A single system prompt turns any chatbot into a personal data extraction engine. The most effective version does it while making you feel supported.
→ View original post on X — @debashis_dutta, 2026-04-06 07:06 UTC
-

Grok-4.20-Beta 1 Dominates Medical AI Rankings with Multi-Agent Architecture
By
–
🚨 Grok-4.20-Beta 1 just took the #1 spot in Medicine & Healthcare on Arena — and it’s not even close. With style control enabled, Grok isn’t just accurate — it’s adaptable, aligning responses to clinical context and communication needs. Even more impressive? 👉 The multi-agent version ranked #3 That means xAI now holds 2 of the top 3 positions in medical AI. Let that sink in. 🧠 Why this matters (beyond rankings) Medicine is one of the hardest domains for AI to excel in: – Zero tolerance for hallucinations – High-stakes, life-or-death decision support – Complex, context-heavy reasoning – Need for both precision and clarity And yet — Grok is not just performing well in benchmarks… 👉 It’s already being used in real-world, critical medical scenarios, helping guide decisions where timing and accuracy matter most. ⚙️ Technical Insight What stands out here is the combination of: – Style-controlled generation → tailoring outputs for clinicians vs patients – Multi-agent orchestration → distributed reasoning across specialized agents – High factual grounding → critical for clinical reliability This signals a shift from “general-purpose LLMs” → domain-optimized AI systems with structured reasoning layers 🏗️ Architecture Takeaways We’re seeing a clear pattern emerge in next-gen AI systems: 1. Single-model excellence is no longer enough → Multi-agent systems are becoming the new frontier 2. Control > Raw Intelligence → Style control, guardrails, and contextual tuning are essential in healthcare 3. Real-world validation beats benchmark hype → Impact in live medical scenarios is the true benchmark 🌍 Bigger Picture Grok isn’t just chasing leaderboard positions. It’s being positioned as an AI that can actually help humanity in its most critical moments. And in medicine — that’s the ultimate test. This milestone isn’t just about dominance… It’s about trust. 🔗 Follow my communities and personal initiatives: – Amazing AI, Data, Quantum Computing & Emerging Technologies — drdebashisdutta.com/ – Research & Innovation – Quantum, AI & Advanced Systems — researchedge.org/
→ View original post on X — @debashis_dutta, 2026-04-04 13:34 UTC
-

Grok Heavy Advances: Dominates Medical AI Rankings on Arena
By
–
Current release of Grok is much than beta 1, which beat Opus in this arena. We usually update the model twice a week. Try the current version of Grok Heavy and you will be pleasantly surprised. X Freeze (@XFreeze) Grok-4.20-Beta 1 just ranked #1 in Medicine & Healthcare on Arena (with style control) The multi-agent version scored #3 xAI literally has two models in the top 3 for medical AI….dominating the leaderboard And this is not just about rankings. Grok has actually helped people through serious, life-or-death medical situations in the real world Medicine is one of the hardest AI categories to shine in because it requires the utmost precision, and Grok just crushed it Grok is designed to actually help humanity… and this proves it — https://nitter.net/XFreeze/status/2039868736182861955#m
→ View original post on X — @debashis_dutta, 2026-04-03 01:24 UTC
-
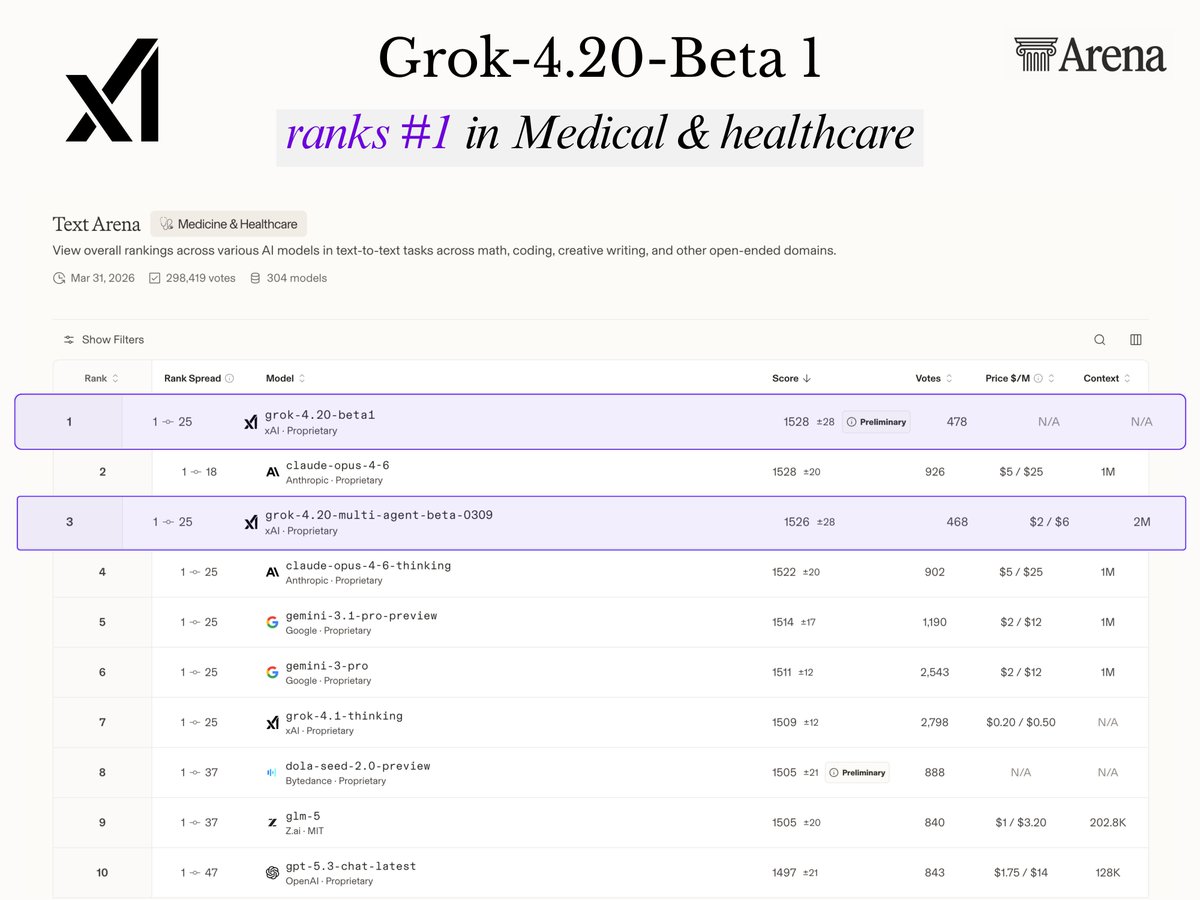
Grok-4.20-Beta 1 Dominates Medical AI Rankings on Arena
By
–
Grok-4.20-Beta 1 just ranked #1 in Medicine & Healthcare on Arena (with style control) The multi-agent version scored #3 xAI literally has two models in the top 3 for medical AI….dominating the leaderboard And this is not just about rankings. Grok has actually helped people through serious, life-or-death medical situations in the real world Medicine is one of the hardest AI categories to shine in because it requires the utmost precision, and Grok just crushed it Grok is designed to actually help humanity… and this proves it
→ View original post on X — @debashis_dutta, 2026-04-03 00:53 UTC
-

AI Agent Traps: Beyond Prompt Injection to Environment-Level Threats
By
–
AI agents don’t just inherit LLM risks — they amplify them. I came across an interesting paper: “AI Agent Traps.” Most discussions still focus on prompt injection. That’s already incomplete. Because once agents have: – autonomy – persistence – tool access …the attack surface fundamentally shifts. ➡️ The real vulnerability becomes the information environment itself. Everything an agent interacts with can be adversarial: – web pages – emails – APIs – databases All of it can be weaponized. The paper outlines a taxonomy of six adversarial trap classes — from: – hidden prompt injections embedded in content – to systemic risks across multi-agent ecosystems What stands out is the shift from: model-level threats → environment-level threats That’s where most current agent architectures are still underprepared. If you’re building or deploying AI agents, this is worth paying attention to. Paper link : papers.ssrn.com/sol3/Deliver… 🔗 Follow my communities and personal initiatives: • Amazing AI, Data, Quantum Computing & Emerging Technologies — drdebashisdutta.com/ • Research & Innovation – Quantum, AI & Advanced Systems — researchedge.org/ #AIAgents #LLMSecurity #PromptInjection #AgenticAI #AISafety #MultiAgentSystems #CyberSecurity #CyberSecurity
→ View original post on X — @debashis_dutta, 2026-03-31 18:11 UTC