Thank you for the feedback . We are actively working on improving quality and streamlining the product, and are continuing to focus on quality until it feels really good. If there are specific papercuts I’d love to hear so we can fix those. Are you using CLI, Desktop, VSCode,
@bcherny
-
Using AI agents to automate travel booking and task management
By
–
Open Cowork, then ask it to book flights
-
Automating Travel Bookings with AI Agents
By
–
I put my flight preferences in my Cowork instructions, then let Opus get to work. It opened my browser, navigated a bunch of websites, and booked everything for me. The result: Cowork booked 8 flights and 5 hotels for me, while I was hacking on something else in Claude Code. It
-
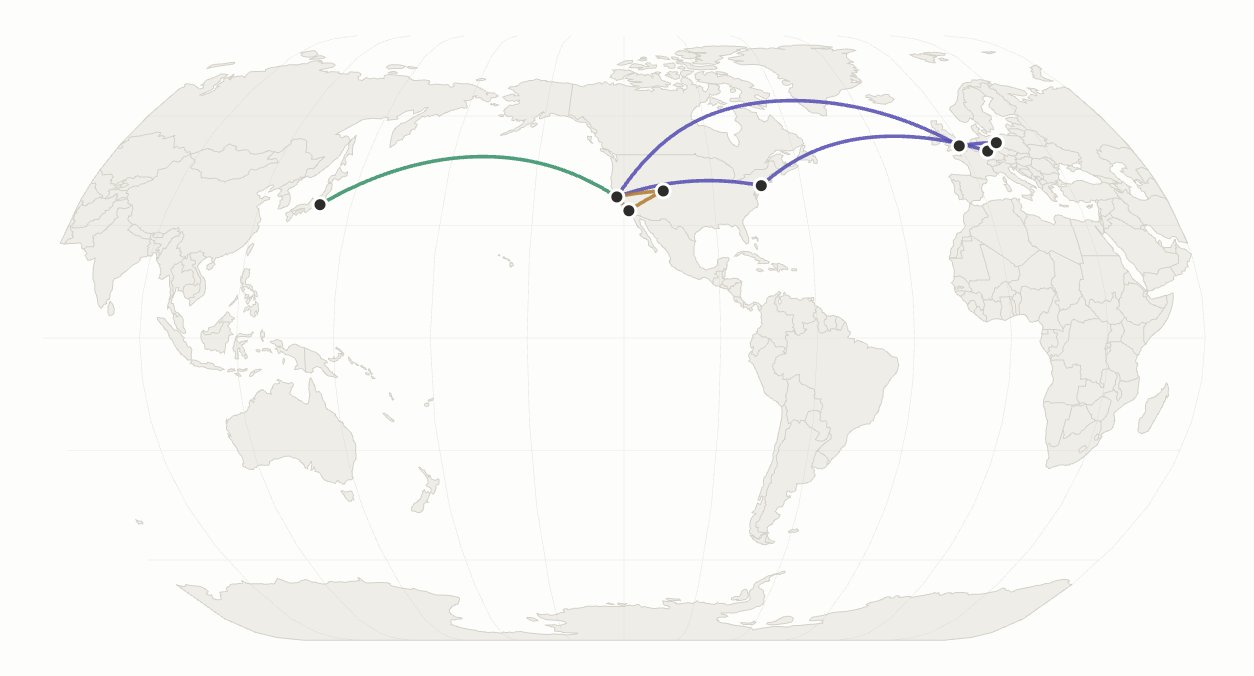
Using Claude Cowork and Opus 4.7 for automated flight booking
By
–
I needed to book flights for a bunch of upcoming travel. As always, I used Claude Cowork to do it. In the past, Cowork has been decent at booking flights, but with Opus 4.7, for the first time ever, it 1-shotted it!
-
Scaling from Single to Multi-Agent Workflows
By
–
The best way to level up from 1 agent => many agents. No more cycling between terminal tabs https://t.co/PjQpKdi1aO
— Boris Cherny (@bcherny) 11 mai 2026The best way to level up from 1 agent => many agents. No more cycling between terminal tabs
-
Claude Code sees 15x growth and SQL debugging feature
By
–
Guessing you're looking at npm-only data. We switched to a native installer a few months back, so the majority of installs aren't captured here. Thursday was the second-highest Claude Code signup day we've ever had (15x growth since Jan 1). Ask Claude to debug your SQL?
-
Usage tracking improvements for plugins skills and custom agents
By
–
Run /usage to see what's eating up your limits. Improving this over the coming days to give you more visibility into plugins, skills, and custom agents
-
Usage Limits Reset for AI Service Subscribers
By
–
We’re resetting usage limits for subscribers. Thank you so much for your feedback and patience!
-
Anthropic Addresses Opus 4.7 Issues in Claude Code
By
–
Separately, we’ve also heard reports of issues with Opus 4.7 in Claude Code. The team is working on those and we’ll share more as we roll out improvements over the coming days.