Blog post:
https://
blog.arcee.ai/arcee-supernov
a-training-pipeline-and-model-composition/
…
Model on HF:
https://
huggingface.co/arcee-ai/Llama
-3.1-SuperNova-Lite
…
@aymericroucher
-
New SuperNova Training Pipeline and Llama-3.1-SuperNova-Lite Model
By
–
-
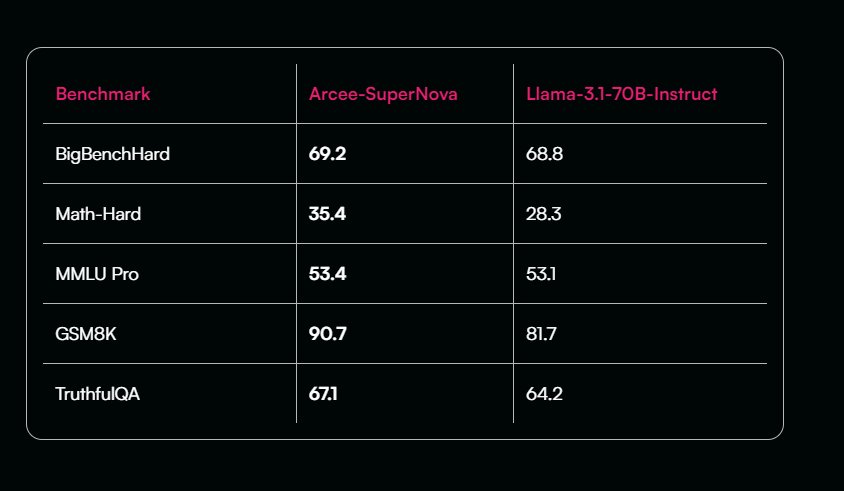
Arcee SuperNova: Llama-3.1-70B fine-tune with 405B distillation
By
–
Arcee releases Arcee-SuperNova, better fine-tune of Llama-3.1-70B! versions: 70B and 8B Trained by distilling logits from Llama-3.1-405B Used a clever compression method to reduce dataset weight from 2.9 Petabytes down to 50GB (may share it in a paper) Not all
-
Philschmid’s space to compare LLM prices
By
–
In a similar vein, check out @_philschmid
's great space to compare LLM prices across providers: -
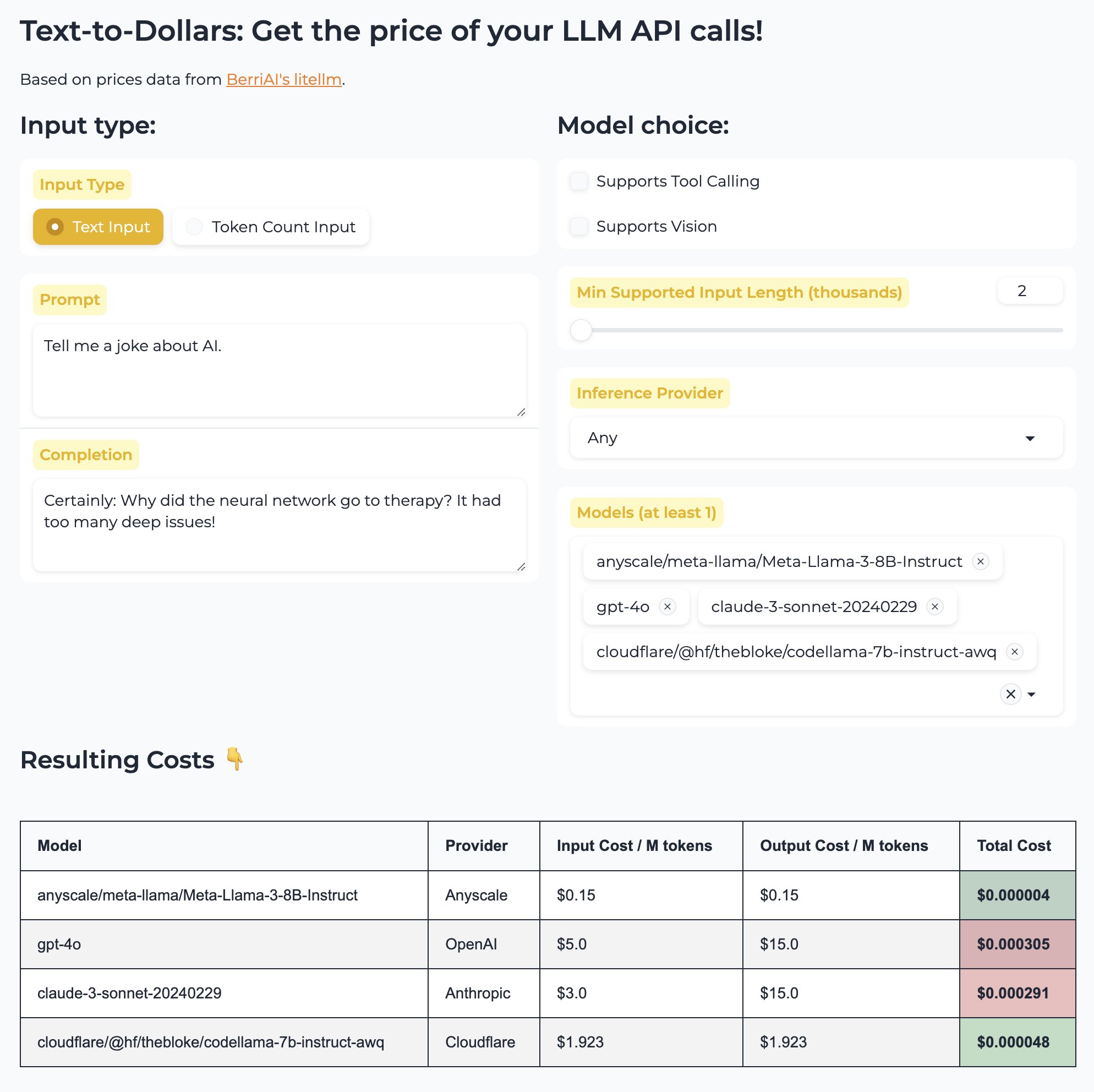
Space that calculates API LLM call costs for all providers
By
–
> Want to know how much an API LLM call costs you? I've just made a Space that gets you the API price for any LLM call, for nearly all inference providers out there! This is based on a comment by @victormustar under my HF Post a few months back, and leverages @make_berri
's data -
LLM Inference with TGI: A Must-Read Guide
By
–
> Article read: Simple guide to LLM inference and to TGI I've just read the article "LLM inference at scale with TGI" by @martinigoyanes
. It's really good content, a must-read if you want a good low-level intro to LLM inference with TGI! My takeaways: How does inference work? -
New cookbook: Multi-agent web browsing system with Transformers Agents
By
–
New cookbook: Multi-agent web browsing system! To support the launch of multi-agent systems in our Transformers Agents library, I highlight how to build one of these hierarchies to make a system that browses the web and leverages code to efficiently answer user questions!
-
Link to the Reflection-Llama-3.1-70B model on the Hub
By
–
Check it out on the Hub -> https://
huggingface.co/mattshumer/Ref
lection-Llama-3.1-70B
… -

New 70B LLM Outperforms Claude-3.5-Sonnet and GPT-4o with Innovative Fine-Tuning
By
–
> A new 70B open-source LLM beats Claude-3.5-Sonnet and GPT-4o! Matt Schumer, CEO from Hyperwrite AI, had an idea he wanted to try out: why not fine-tune LLMs to always output their thoughts in specific parts, delineated by tags? Even better: inside of that, you
-
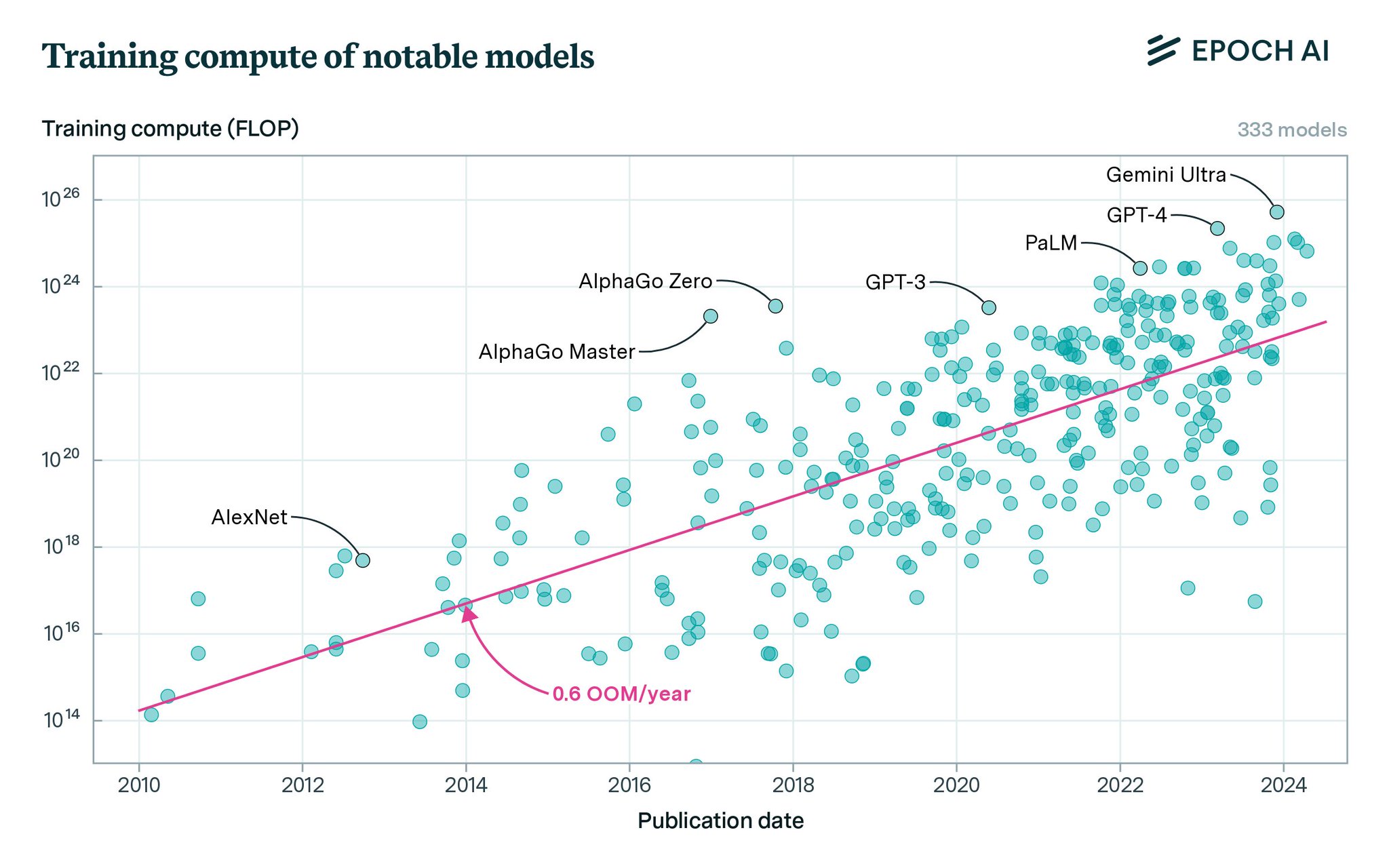
AI clusters’ power consumption to rival entire countries by 2028
By
–
> By 2028, AI Clusters will reach the power consumption of entire countries Reminder : “Scaling laws” are empirical laws saying that if you keep multiplying your compute by x10, your models will mechanically keep getting better and better. To give you an idea, GPT-3 can barely
-
Generate image morphing from one concept to another, like Mannerism to Cubism
By
–
Very cool space by @linoy_tsaban and @multimodalart : you can generate an image an make it morph from one concept to the other!
— m_ric (@AymericRoucher) 5 septembre 2024
Mine below is:
"A painting of a woman"
Mannerism ⬅️➡️ Cubism pic.twitter.com/wiq7SDLh9KVery cool space by @linoy_tsaban and @multimodalart : you can generate an image an make it morph from one concept to the other! Mine below is:
"A painting of a woman"
Mannerism Cubism