This is great news! There's one router between Llama-3.1-405B and Llama-3.1-70B, can come in really handy to arbitrate between strength and speed depending on your task!
@aymericroucher
-
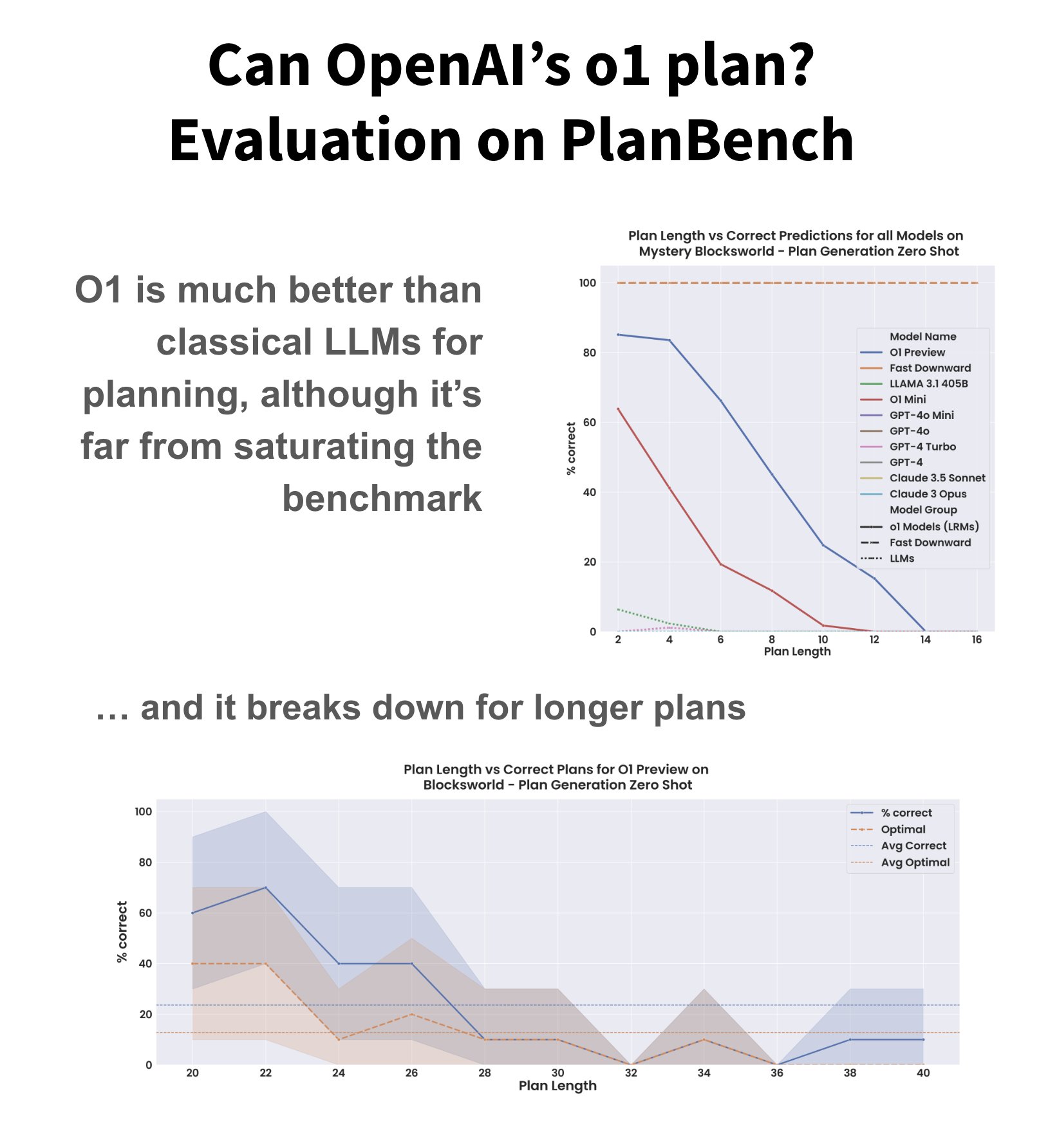
OpenAI’s o1 still can’t plan reliably but is a massive leap forward
By
–
Paper read – OpenAI's o1 still can't plan reliably – but is still a massive leap forward Can OpenAI's o1 actually plan and reason, as claimed in its release? Researchers put it to the test using PlanBench, a planning benchmark that has stumped even the best language
-
New paper evaluates VLMs for meme detection, releases dataset
By
–
Now finally someone decides to take on the hard problems! > A new paper evaluates the ability of VLMs to detect memes! Of course, they also release a dataset of memes to test models!
-
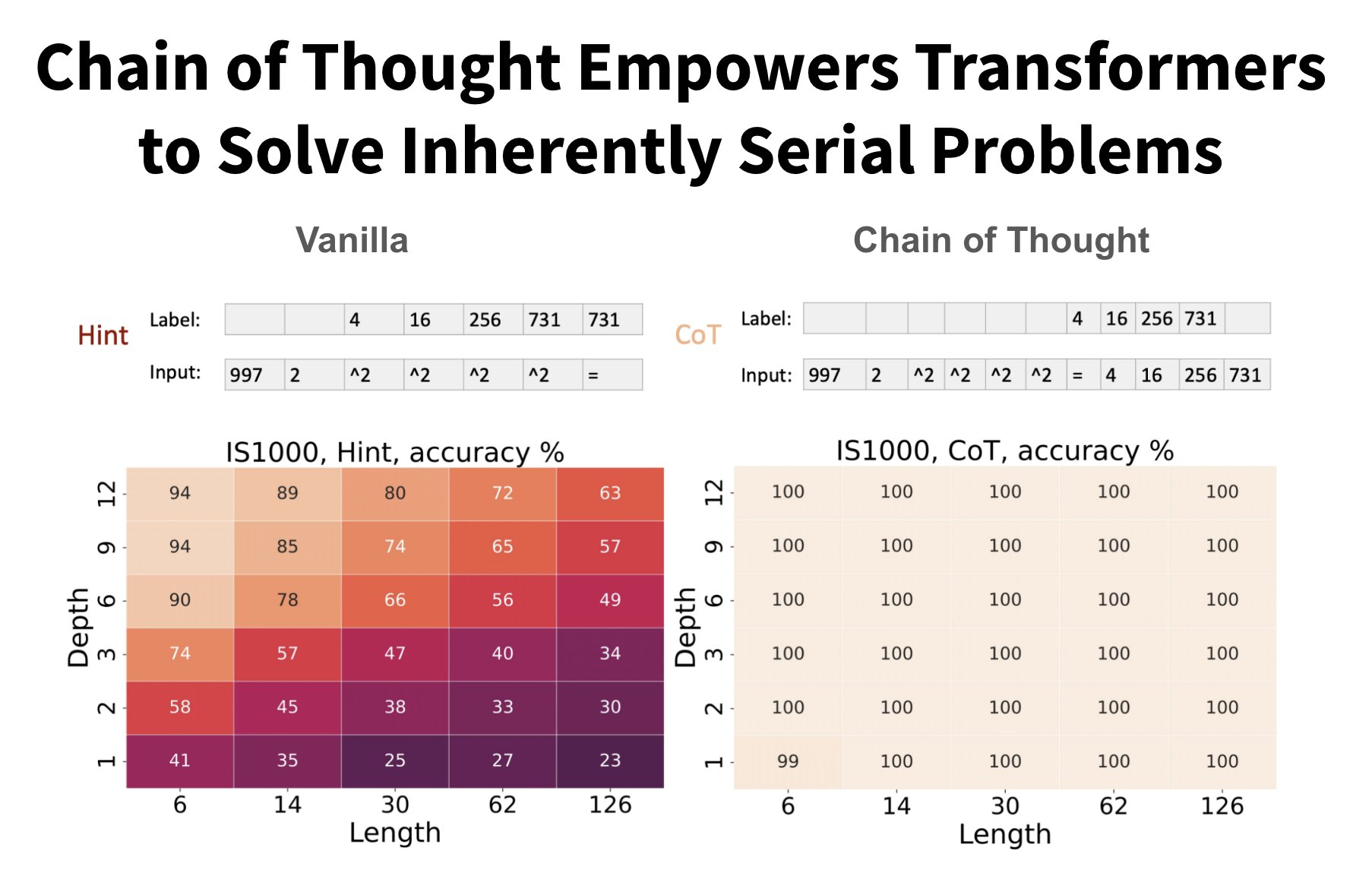
Stanford paper reveals Chain of Thought unlocks sequential tasks.
By
–
Stanford paper might be the key to OpenAI o1’s performance: What’s so effective about Chain of Thought? ⇒ it unlocks radically different sequential tasks! Reminder: A Chain of Thought (CoT) means that you instruct the model to “think step by step”. Often it’s literally
-
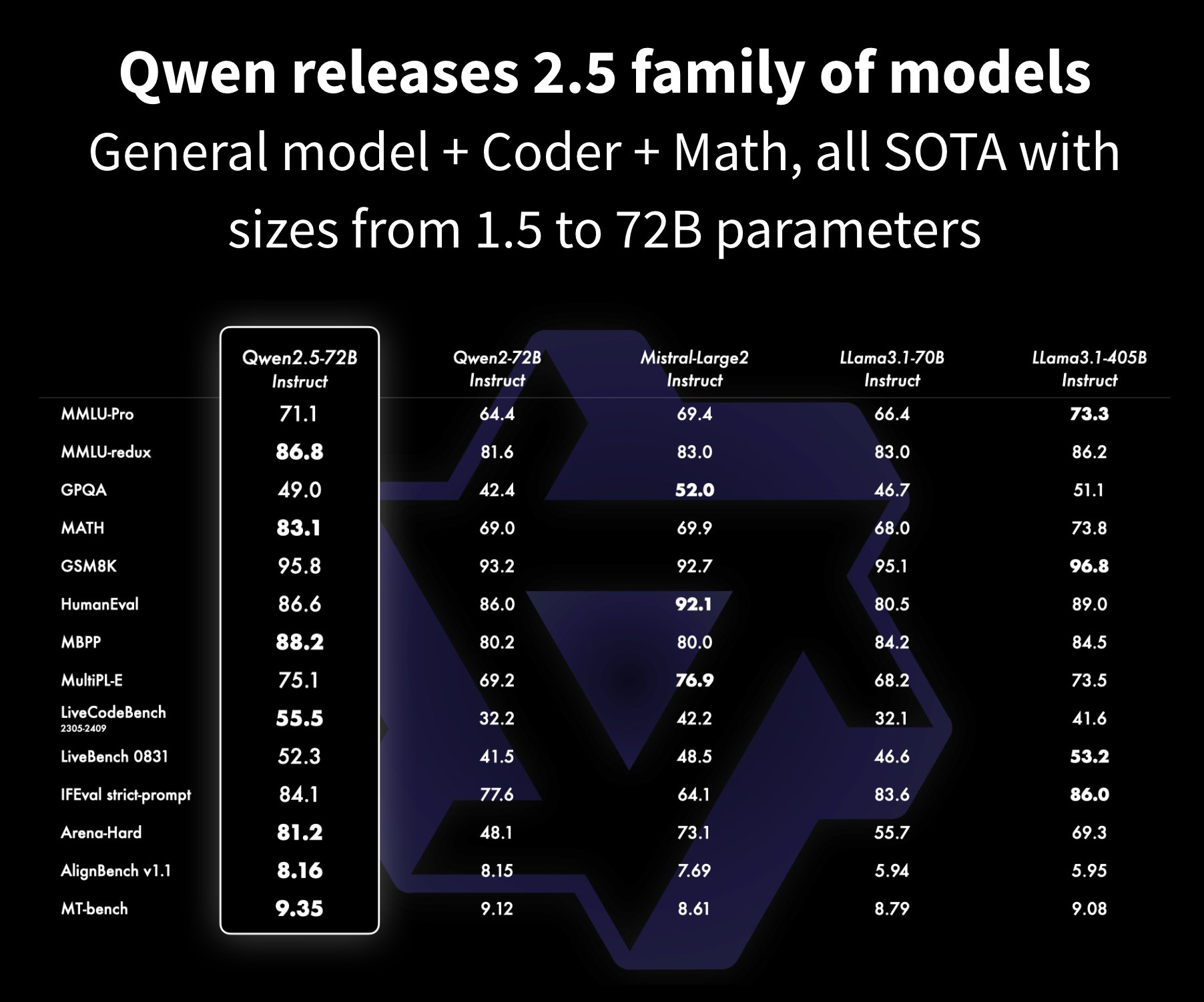
Qwen 2.5: new family of SOTA models up to 72B
By
–
Qwen releases their 2.5 family of models: New SOTA for all sizes up to 72B! The Chinese LLM maker just dropped a flurry of different models, ensuring there will be a Qwen SOTA model for every application out there: Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B
-
Evaluating Agentic Systems on Data Science with DSBench
By
–
Are Agents capable enough for Data Science? ⇒ Measure their performance with DSBench A team from Tencent AI wanted to evaluate agentic systems on data science (DS) tasks : but they noticed that existing agentic benchmarks were severely limited in several aspects: they were
-
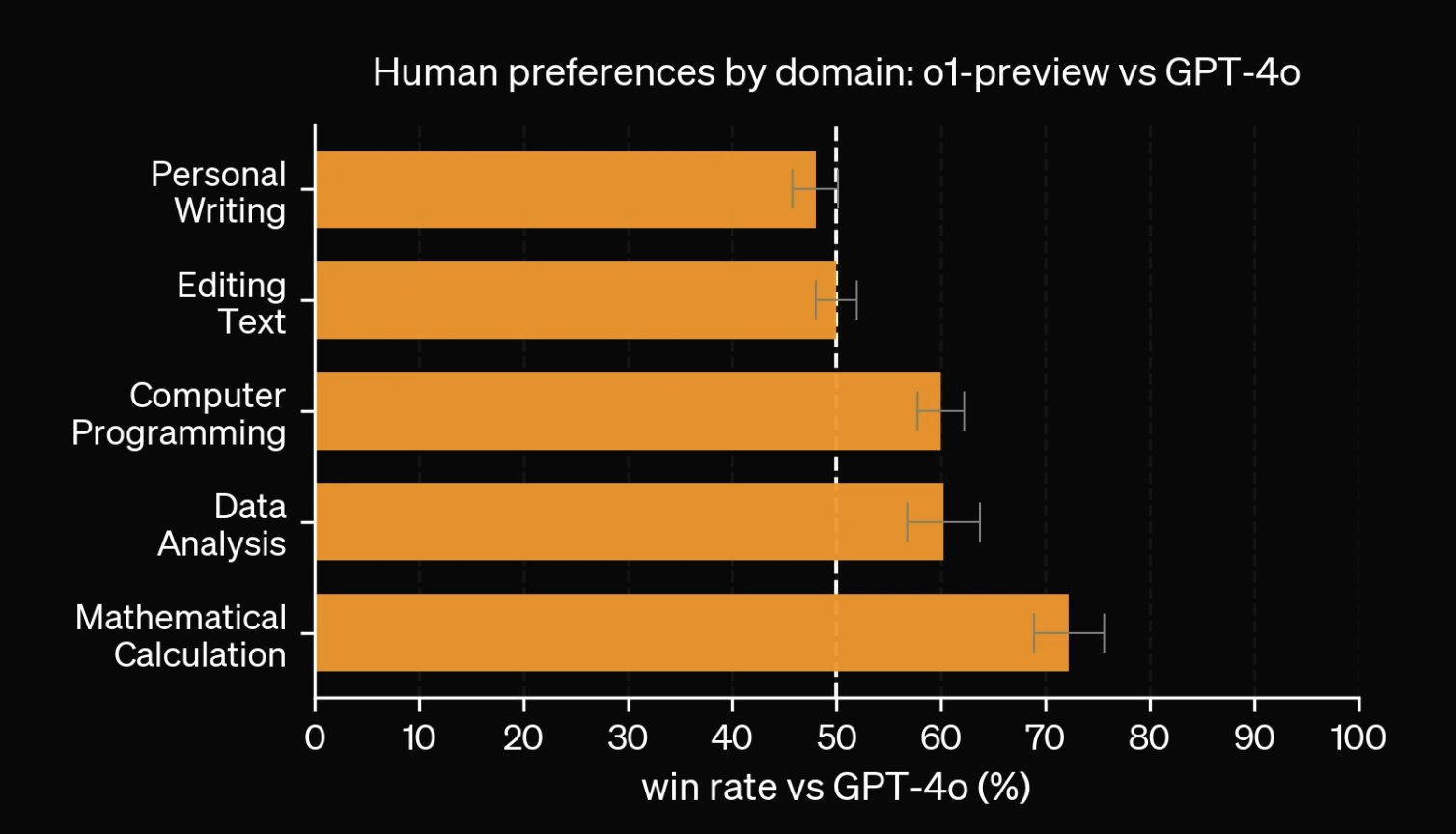
Important quote: AIME and GPQA results strong but not user-visible
By
–
This quote is especially important:
> "Results on AIME and GPQA are really strong, but that doesn’t necessarily translate to something that a user can feel. Even as someone working in science, it’s not easy to find the slice of prompts where GPT-4o fails, o1 does well, and I can -
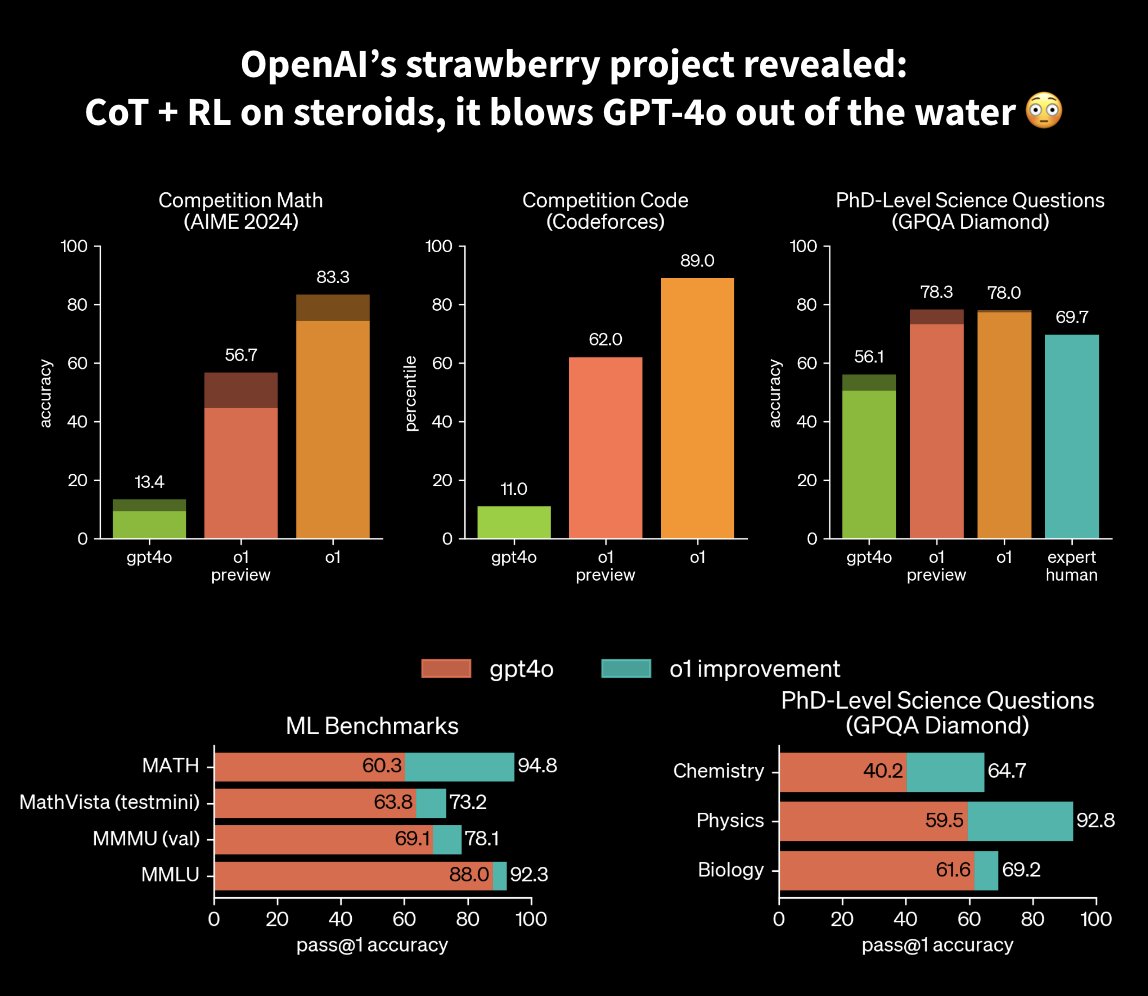
OpenAI reveals o1: chain-of-thought model beats GPT-4o
By
–
OpenAI finally reveals “”: crazy chain-of-thought-tuned model >> GPT-4o OpenAI had hinted at a mysterious “project strawberry” for a long time: they revealed this new model called "o1" 1hour ago, and the performance is just mind-blowing. Places among the top 500 students
-
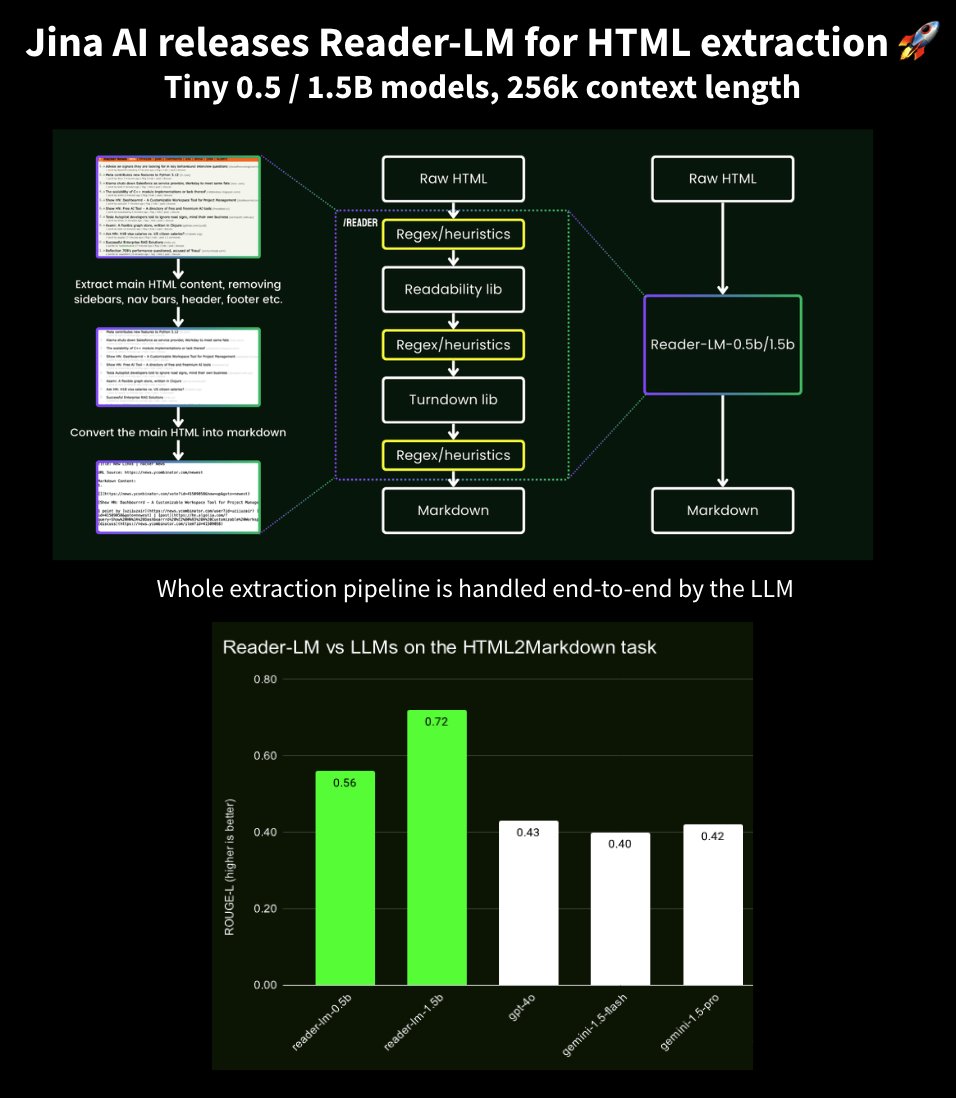
JinaAI Reader-LM extracts markdown from HTML webpages
By
–
Extracting your HTML webpages to markdown is now possible end-to-end with a simple LLM! @JinaAI_ just released Reader-LM, that handles the whole pipeline of extracting markdown from HTML webpages. A while ago, they had released a completely code-based deterministic program
-
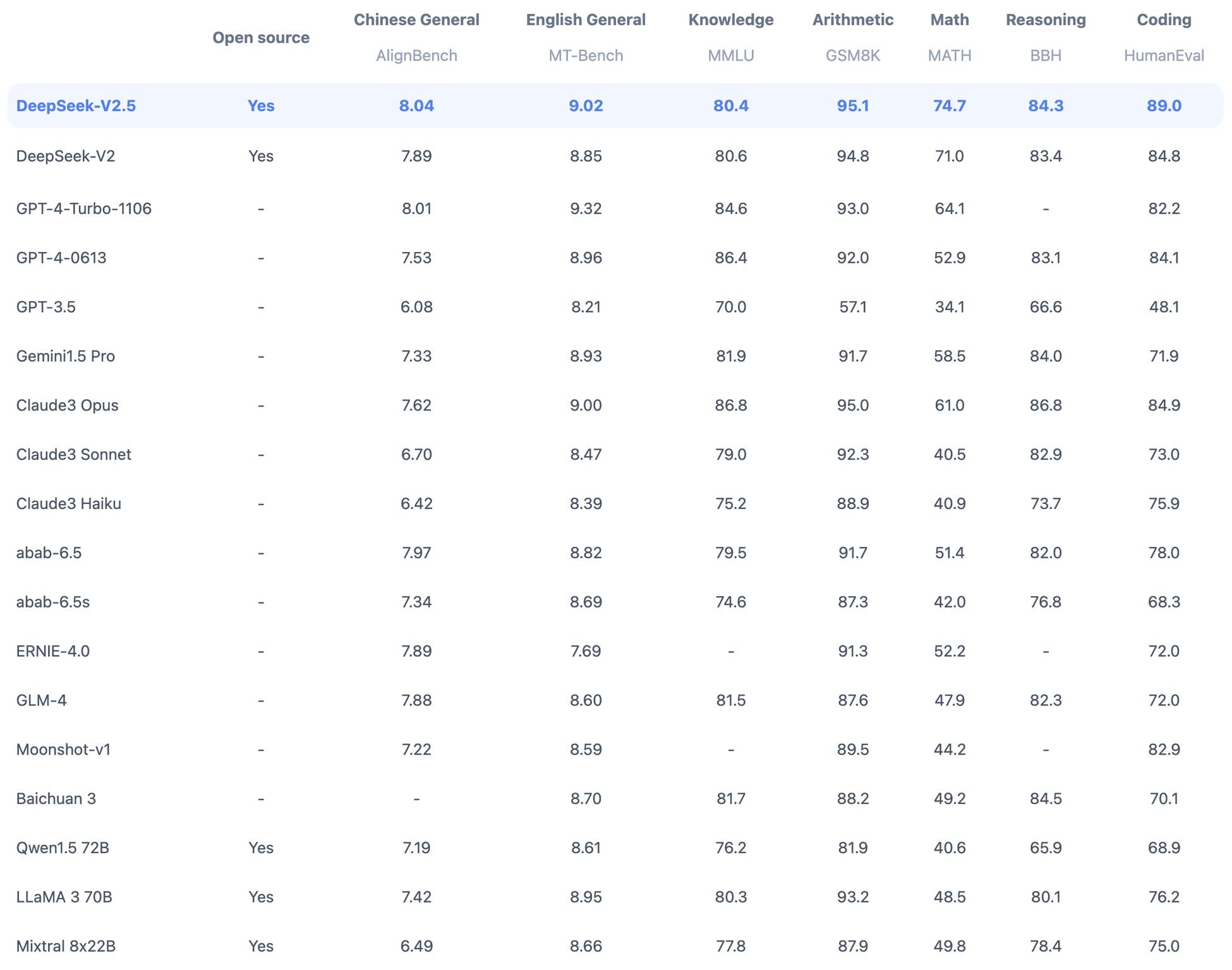
Mistral AI’s Pixtral-12B Vision Model Excels, Outperforming Qwen2-7B
By
–
𝗢𝗽𝗲𝗻 𝗟𝗟𝗠𝘀 𝗮𝗿𝗲 𝗼𝗻 𝗳𝗶𝗿𝗲 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄! 𝗗𝗲𝗲𝗽𝗦𝗲𝗲𝗸-𝗩𝟮.𝟱 𝗮𝗻𝗱 𝗼𝘁𝗵𝗲𝗿 𝘁𝗼𝗽 𝗿𝗲𝗹𝗲𝗮𝘀𝗲𝘀 Mistral AI just released Pixtral-12B, a vision models that seems to perform extremely well! From Mistral’s own benchmark, it beats the great Qwen2-7B