I love how both the answers about thermal throttling and speculative decoding are correct based on how you phrased the question!
@alexjc
-
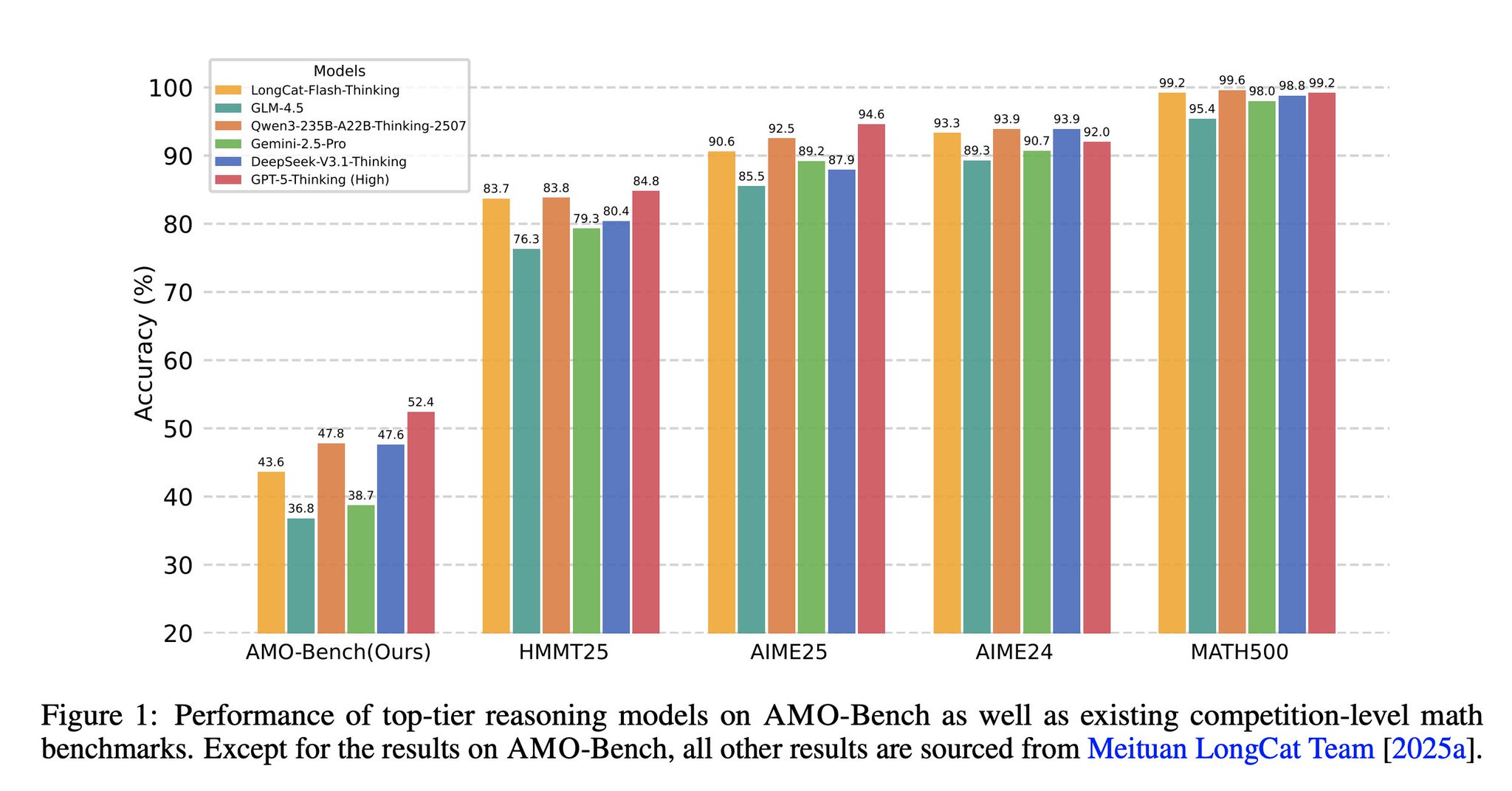
Language Models Struggle With High School Math Fundamentals
By
–
Language models perform poorly on high-school math? You don't want to hear this, but the problems started in grade-school. The moment we (collectively) found acceptable that mid-tier models could score only 75%-85% on a GSM test set of 1.32k straightforward problems…
-

Faster Coding Model Pricing Efficiency Questions
By
–
The speed of a faster coding model is worth it, but it seems mis-priced. C1 gobbles through files, reasons more, expect extra feedback to reach similar place as slower model do with less of everything. Intuitively it feels more expensive "the fast way" with current pricing.
-
Chat modes code review and conversation summarization evolution
By
–
Not a single feature, but evolution of:
1) Making the code changes directly in the files consistently (chat modes) and marking the diffs in a nicely reviewable way.
2) Long chat summarization combined with third-party model capabilities to handle ongoing conversations so you -

Compute Trade-offs: Factual Knowledge vs Dense Core Efficiency
By
–
There are two kinds of people in AI: those who are happily surprised a model would know random facts like these (worth burning compute and parameters), and those who think it's a complete waste of both for a dense core.
-
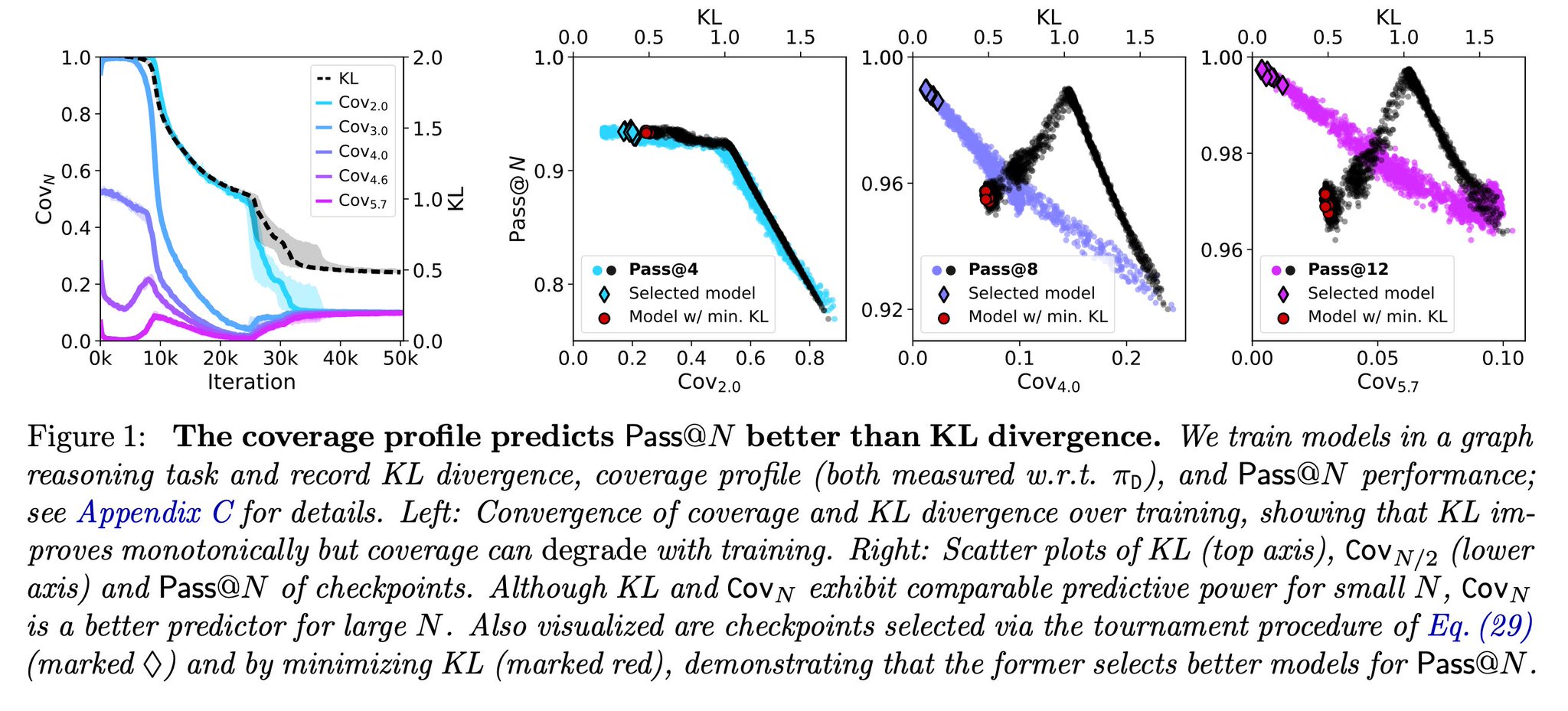
Quality over quantity: improving training datasets for better AI models
By
–
Great idea for a metric to further improve what datasets the models train on. It likely leads to an answer that is not web-scale crawling… Less data is often better, better data takes less.
-
Meta layoffs signal shifting competitive landscape in AI research
By
–
Isn't this a sign of the market becoming more competitive, the golden age of open research from U.S. corporations being increasingly over, and now researchers who would be publishing anyway (without it costing Meta) are being let go?
-
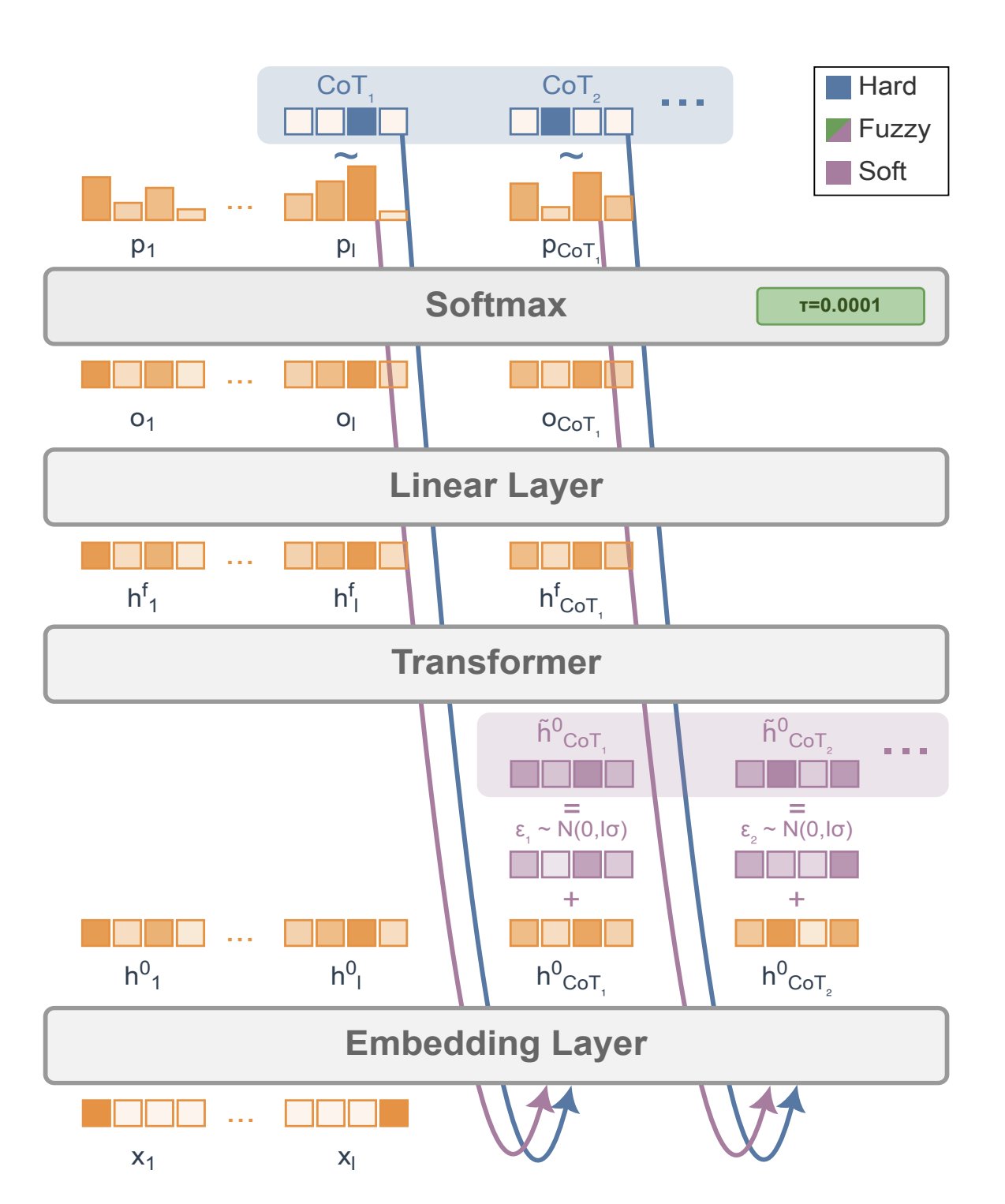
Meta’s Soft Tokens Enable LLMs to Invent Recursive Representations
By
–
This paper from Meta about "Soft Tokens" in RL is interesting; it allows LLMs to invent their own non-discrete (recursive) representations in order to solve problems better… Results are mixed though: it's only a few percent better on GSM8k from pass@4 onwards, and pass@32 just
-

AI Browser Strategy Shifts Scraping Liability to Users
By
–
The reason AI companies are rushing to release browsers: they don't want the responsibility / liability of scraping on their servers. They need to push that to the users! We'll be moving into an ever more gated internet soon…
-
Fair Use Defense Burden of Proof in AI Legal Cases
By
–
I'm so glad for this, looking forward to reading! Courts may drag their feet, but specifically when relying on a Fair Use defense, the burden of proof for the absence of market harms falls on the defendants.