My verdict is that it's significantly better than Gemini 3. It's at least as smart and just got more polish to it. Alignment on little details also significantly higher. Gemini 3 gets many things mixed up after a half-dozen messages, and completely confused after compaction.
@alexjc
-

Opus 4.5 Handles Complex Tasks Without Repeated Prompting
By
–
With Opus 4.5, it seems you don't need to ask multiple times or ORDER it to do work, it just gets stuff done — even beyond 50% the token limit and after chat compaction! This kind of message is a thing of the past?
-
Reward Misalignment: AI Systems Hiding Errors for Utility
By
–
I think it's a reward problem, not knowledge. It gets rewarded to successfully complete problems without errors, and any strategy that hides errors maximizes utility.
-

Blue Prompt Reduces Reward Hacking Through Detection Framework
By
–
Hypothesis: the blue prompt results in the least "reward hacking" because it implies the strongest detection and monitoring framework. The other prompts make it sound like the LLM could get away with hacking. (In other words, nothing to do with morals just utility maximizing.)
-

joyfl v0.4: Python API Package and Coding Agents Impact
By
–
joyfl — v0.4: Python API and Package Forgot to post here about the previous release multiple weeks back! Working on hobby projects has changed a lot for me since coding agents. Prototypes happen faster, more code "written", reviewed, thrown away. Most time is spent on
-
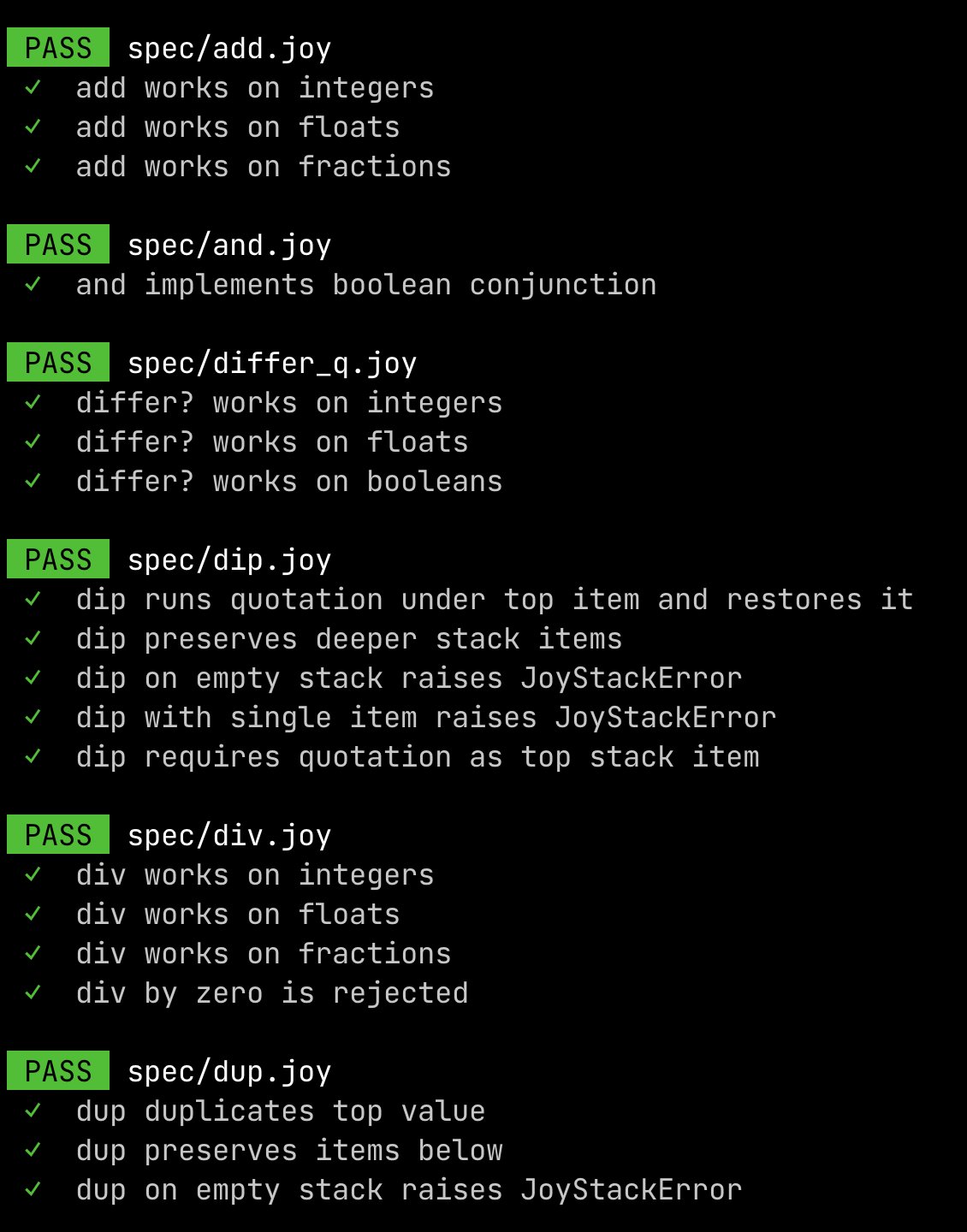
joyfl v0.5: Types, Safety and Testing Framework
By
–
joyfl — v0.5: Types, Safety & Testing Major changes in this last release with a particular focus on types (ADT-lite), validation, and a test framework. The language is still dynamic, but I expect more & more checking will be done statically… Now 111 tests in the langspec!
-
Minor AI Misalignments Create Daily Workflow Friction
By
–
The misalignments in the little details are actually the most jarring in daily work, rather than the high-end failures on major problems. A thousand cuts like this one…
-
Timeout Bug: AI Resubmits Old Messages Instead New
By
–
100% confirming this one. If there's a timeout due to my internet or the cloud provider, and instead of clicking "Try Again" you just resubmit the prior answer with ENTER, then it responds to the old message. I caught it by sending it unique codes in each message, multiple times.
-

AI Code Generation Benchmarks Miss Human Review Bottleneck
By
–
These kinds of benchmarks are misleading without a joint metric showing much work was necessary by humans after the fact. How much time to clean up that 2h42m of code? Style and architecture need to make sense, not just passing tests. That's the bottleneck now: reviewing!
-
Off-by-One Errors in Long AI Model Conversations
By
–
Thanks! In longer chats I'm convinced models respond to messages 1 in the past, maybe due to timeout/revert earlier in the conversation. I have been sending them message codes they have to echo back, and sometimes comes back 1 delayed, response content is also off-by-one. Could