Beautifully written piece by @FAbnousi about how AI for health might look like in the future
The current data in health is limited because it only captures episodic clinical snapshots of what happens to our bodies
The revelation is that there is so much latent knowledge in
@_jasonwei
-
AI Transforming Healthcare Through Comprehensive Patient Data
By
–
-
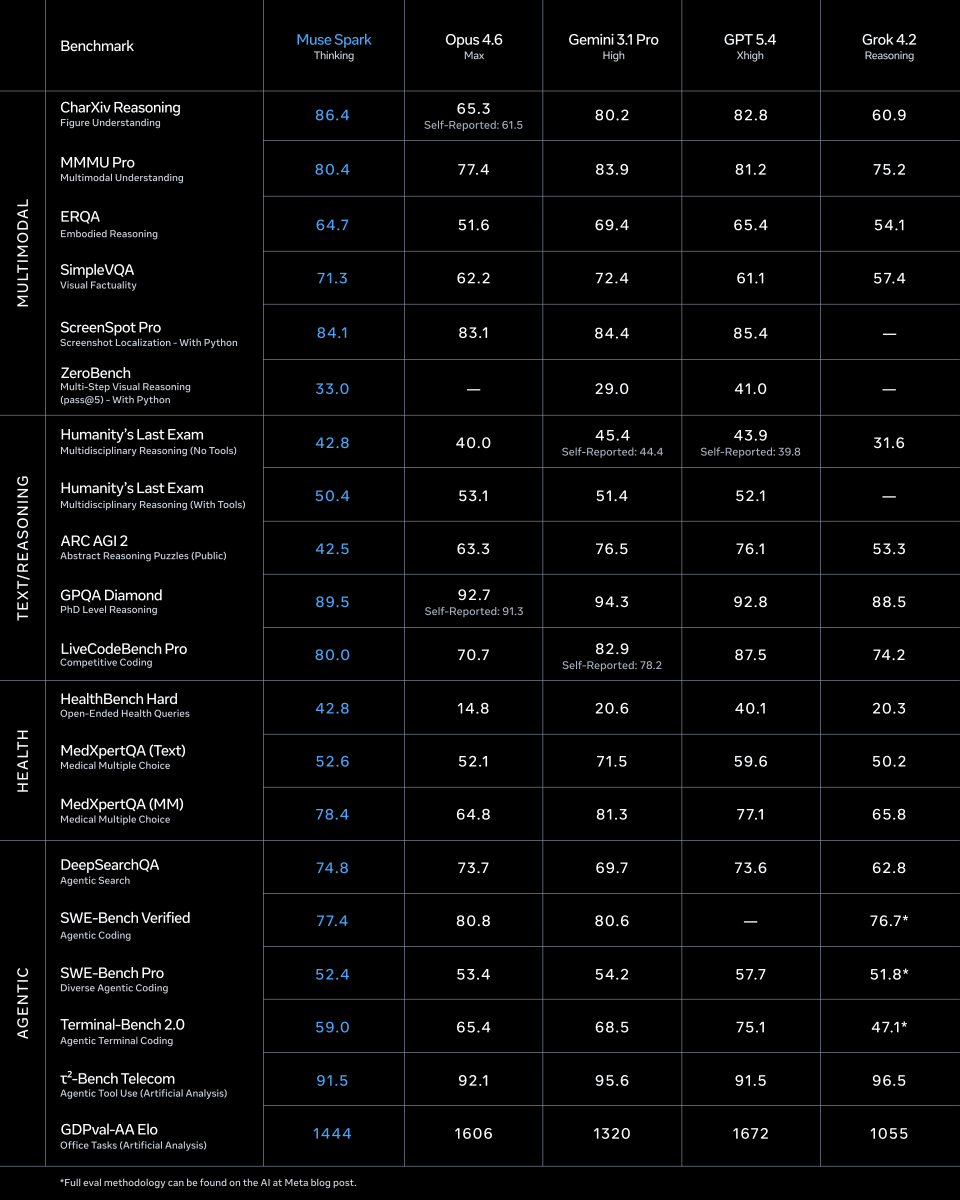
Nine Months of Building: Muse Spark Model Launch Success
By
–
Fun nine months! My first week i remember we had a long dinner in the cafeteria daydreaming about the cool research directions to pursue, then going to back to our desks to write a basic script to inference llama. Now we have a pretty complete stack and our first model is out 🥑 Alexandr Wang (@alexandr_wang) 1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵 — https://nitter.net/alexandr_wang/status/2041909376508985381#m
→ View original post on X — @_jasonwei, 2026-04-08 17:25 UTC
-

AI for Science: Periodic Labs Launches Autonomous Scientific Discovery Platform
By
–
Bullish, in the coming decades majority of compute will be spent on ai for science William Fedus (@LiamFedus) Today, @ekindogus and I are excited to introduce @periodiclabs. Our goal is to create an AI scientist. Science works by conjecturing how the world might be, running experiments, and learning from the results. Intelligence is necessary, but not sufficient. New knowledge is created when ideas are found to be consistent with reality. And so, at Periodic, we are building AI scientists and the autonomous laboratories for them to operate. Until now, scientific AI advances have come from models trained on the internet. But despite its vastness — it’s still finite (estimates are ~10T text tokens where one English word may be 1-2 tokens). And in recent years the best frontier AI models have fully exhausted it. Researchers seek better use of this data, but as any scientist knows: though re-reading a textbook may give new insights, they eventually need to try their idea to see if it holds. Autonomous labs are central to our strategy. They provide huge amounts of high-quality data (each experiment can produce GBs of data!) that exists nowhere else. They generate valuable negative results which are seldom published. But most importantly, they give our AI scientists the tools to act. We’re starting in the physical sciences. Technological progress is limited by our ability to design the physical world. We’re starting here because experiments have high signal-to-noise and are (relatively) fast, physical simulations effectively model many systems, but more broadly, physics is a verifiable environment. AI has progressed fastest in domains with data and verifiable results – for example, in math and code. Here, nature is the RL environment. One of our goals is to discover superconductors that work at higher temperatures than today's materials. Significant advances could help us create next-generation transportation and build power grids with minimal losses. But this is just one example — if we can automate materials design, we have the potential to accelerate Moore’s Law, space travel, and nuclear fusion. We’re also working to deploy our solutions with industry. As an example, we're helping a semiconductor manufacturer that is facing issues with heat dissipation on their chips. We’re training custom agents for their engineers and researchers to make sense of their experimental data in order to iterate faster. Our founding team co-created ChatGPT, DeepMind’s GNoME, OpenAI’s Operator (now Agent), the neural attention mechanism, MatterGen; have scaled autonomous physics labs; and have contributed to some of the most important materials discoveries of the last decade. We’ve come together to scale up and reimagine how science is done. We’re fortunate to be backed by investors who share our vision, including @a16z who led our $300M round, as well as @Felicis, DST Global, NVentures (NVIDIA’s venture capital arm), @Accel and individuals including @JeffBezos , @eladgil , @ericschmidt, and @JeffDean. Their support will help us grow our team, scale our labs, and develop the first generation of AI scientists. — https://nitter.net/LiamFedus/status/1973055380193431965#m
→ View original post on X — @_jasonwei, 2025-09-30 16:04 UTC
-

Jason Wei Joins Meta Superintelligence Labs Team
By
–
Excited to share that I recently joined the MSL team! Building personal superintelligence is serious and fun here. Join us! Hyung Won Chung (@hwchung27) After a great time at OpenAI, we (@EdwardSun0909, @_jasonwei) recently joined @Meta Superintelligence Labs. The first month has already been so much fun building from a clean slate with a truly talent-dense team! Very excited about the compute and long term focus of the new lab — https://nitter.net/hwchung27/status/1956092401854111934#m
→ View original post on X — @_jasonwei, 2025-08-14 20:46 UTC
-

Jason Wei and colleagues join Meta Superintelligence Labs
By
–
Old friends, new lab Hyung Won Chung (@hwchung27) After a great time at OpenAI, we (@EdwardSun0909, @_jasonwei) recently joined @Meta Superintelligence Labs. The first month has already been so much fun building from a clean slate with a truly talent-dense team! Very excited about the compute and long term focus of the new lab — https://nitter.net/hwchung27/status/1956092401854111934#m
→ View original post on X — @_jasonwei, 2025-08-14 20:37 UTC
-
On-Policy Learning in Life: Moving Beyond Imitation to Find Your Path
By
–
Becoming an RL diehard in the past year and thinking about RL for most of my waking hours inadvertently taught me an important lesson about how to live my own life. One of the big concepts in RL is that you always want to be “on-policy”: instead of mimicking other people’s successful trajectories, you should take your own actions and learn from the reward given by the environment. Obviously imitation learning is useful to bootstrap to nonzero pass rate initially, but once you can take reasonable trajectories, we generally avoid imitation learning because the best way to leverage the model’s own strengths (which are different from humans) is to only learn from its own trajectories. A well-accepted instantiation of this is that RL is a better way to train language models to solve math word problems compared to simple supervised finetuning on human-written chains of thought. Similarly in life, we first bootstrap ourselves via imitation learning (school), which is very reasonable. But even after I graduated school, I had a habit of studying how other people found success and trying to imitate them. Sometimes it worked, but eventually I realized that I would never surpass the full ability of someone else because they were playing to their strengths which I didn’t have. It could be anything from a researcher doing yolo runs more successfully than me because they built the codebase themselves and I didn’t, or a non-AI example would be a soccer player keeping ball possession by leveraging strength that I didn’t have. The lesson of doing RL on policy is that beating the teacher requires walking your own path and taking risks and rewards from the environment. For example, two things I enjoy more than the average researcher are (1) reading a lot of data, and (2) doing ablations to understand the effect of individual components in a system. Once when collecting a dataset, I spent a few days reading data and giving each human annotator personalized feedback, and after that the data turned out great and I gained valuable insight into the task I was trying to solve. Earlier this year I spent a month going back and ablating each of the decisions that I previously yolo’ed while working on deep research. It was a sizable amount of time spent, but through those experiments I learned unique lessons about what type of RL works well. Not only was leaning into my own passions more fulfilling, but I now feel like I’m on a path to carving a stronger niche for myself and my research. In short, imitation is good and you have to do it initially. But once you’re bootstrapped enough, if you want to beat the teacher you must do on-policy RL and play to your own strengths and weaknesses 🙂
→ View original post on X — @_jasonwei, 2025-07-16 01:26 UTC
-

Asymmetry of Verification and Verifier’s Law in AI Training
By
–
New blog post about asymmetry of verification and "verifier's law": jasonwei.net/blog/asymmetry-… Asymmetry of verification–the idea that some tasks are much easier to verify than to solve–is becoming an important idea as we have RL that finally works generally. Great examples of asymmetry of verification are things like sudoku puzzles, writing the code for a website like instagram, and BrowseComp problems (takes ~100 websites to find the answer, but easy to verify once you have the answer). Other tasks have near-symmetry of verification, like summing two 900-digit numbers or some data processing scripts. Yet other tasks are much easier to propose feasible solutions for than to verify them (e.g., fact-checking a long essay or stating a new diet like "only eat bison"). An important thing to understand about asymmetry of verification is that you can improve the asymmetry by doing some work beforehand. For example, if you have the answer key to a math problem or if you have test cases for a Leetcode problem. This greatly increases the set of problems with desirable verification asymmetry. "Verifier's law" states that the ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI. The ability to train AI to solve a task is proportional to whether the task has the following properties: 1. Objective truth: everyone agrees what good solutions are 2. Fast to verify: any given solution can be verified in a few seconds 3. Scalable to verify: many solutions can be verified simultaneously 4. Low noise: verification is as tightly correlated to the solution quality as possible 5. Continuous reward: it’s easy to rank the goodness of many solutions for a single problem One obvious instantiation of verifier's law is the fact that most benchmarks proposed in AI are easy to verify and so far have been solved. Notice that virtually all popular benchmarks in the past ten years fit criteria #1-4; benchmarks that don’t meet criteria #1-4 would struggle to become popular. Why is verifiability so important? The amount of learning in AI that occurs is maximized when the above criteria are satisfied; you can take a lot of gradient steps where each step has a lot of signal. Speed of iteration is critical—it’s the reason that progress in the digital world has been so much faster than progress in the physical world. AlphaEvolve from Google is one of the greatest examples of leveraging asymmetry of verification. It focuses on setups that fit all the above criteria, and has led to a number of advancements in mathematics and other fields. Different from what we've been doing in AI for the last two decades, it's a new paradigm in that all problems are optimized in a setting where the train set is equivalent to the test set. Asymmetry of verification is everywhere and it's exciting to consider a world of jagged intelligence where anything we can measure will be solved.
→ View original post on X — @_jasonwei, 2025-07-16 00:59 UTC
-
AI Self-Improvement Will Be Gradual, Not Exponential Takeoff
By
–
We don’t have AI self-improves yet, and when we do it will be a game-changer. With more wisdom now compared to the GPT-4 days, it's obvious that it will not be a “fast takeoff”, but rather extremely gradual across many years, probably a decade. The first thing to know is that self-improvement, i.e., models training themselves, is not binary. Consider the scenario of GPT-5 training GPT-6, which would be incredible. Would GPT-5 suddenly go from not being able to train GPT-6 at all to training it extremely proficiently? Definitely not. The first GPT-6 training runs would probably be extremely inefficient in time and compute compared to human researchers. And only after many trials, would GPT-5 actually be able to train GPT-6 better than humans. Second, even if a model could train itself, it would not suddenly get better at all domains. There is a gradient of difficulty in how hard it is to improve oneself in various domains. For example, maybe self-improvement only works at first on domains that we already know how to easily fix in post-training, like basic hallucinations or style. Next would be math and coding, which takes more work but has established methods for improving models. And then at the extreme, you can imagine that there are some tasks that are very hard for self-improvement. For example, the ability to speak Tlingit, a native american language spoken by ~500 people. It will be very hard for the model to self-improve on speaking Tlingit as we don’t have ways of solving low resource languages like this yet except collecting more data which would take time. So because of the gradient of difficulty-of-self-improvement, it will not all happen at once. Finally, maybe this is controversial but ultimately progress in science is bottlenecked by real-world experiments. Some may believe that reading all biology papers would tell us the cure for cancer, or that reading all ML papers and mastering all of math would allow you to train GPT-10 perfectly. If this were the case, then the people who read the most papers and studied the most theory would be the best AI researchers. But what really happened is that AI (and many other fields) became dominated by ruthlessly empirical researchers, which reflects how much progress is based on real-world experiments rather than raw intelligence. So my point is, although a super smart agent might design 2x or even 5x better experiments than our best human researchers, at the end of the day they still have to wait for experiments to run, which would be an acceleration but not a fast takeoff. In summary there are many bottlenecks for progress, not just raw intelligence or a self-improvement system. AI will solve many domains but each domain has its own rate of progress. And even the highest intelligence will still require experiments in the real world. So it will be an acceleration and not a fast takeoff, thank you for reading my rant
→ View original post on X — @_jasonwei, 2025-06-30 19:06 UTC
-
AGI Achievement: Creating a Real Living Unicorn Through Genetic Engineering
By
–
I would say that we are undoubtedly at AGI when AI can create a real, living unicorn. And no I don’t mean a $1B company you nerds, I mean a literal pink horse with a spiral horn. A paragon of scientific advancement in genetic engineering and cell programming. The stuff of childhood dreams. Dare I say it will happen in our lifetimes
→ View original post on X — @_jasonwei, 2025-06-28 21:01 UTC
-
Human Language’s Greatest Value: Bootstrapping Language Model Training
By
–
The greatest contribution of human language is bootstrapping language model training
→ View original post on X — @_jasonwei, 2025-06-27 17:02 UTC