The most impressive thing that Tesla FSD can do that I’ve never seen any human is that it stays calm and doesn’t get upset after my mom criticizes its driving for the whole trip
@_jasonwei
-
Discriminator-Generator Gap: Key to AI Scientific Innovation
By
–
Discriminator-generator gap seems to be the most important idea in AI for scientific innovation. With compute + clever search, anything that we can measure will be optimized. First up will be environments that can be verified quickly, with continuous reward, and at scale.
-
AlphaEvolve reveals RL limitations, midtrain search suffices innovation
By
–
AlphaEvolve is deeply disturbing for RL diehards like yours truly
Maybe midtrain + good search is all you need for AI for scientific innovation
And what an alpha move to keep it secret for a year
Congrats big G -
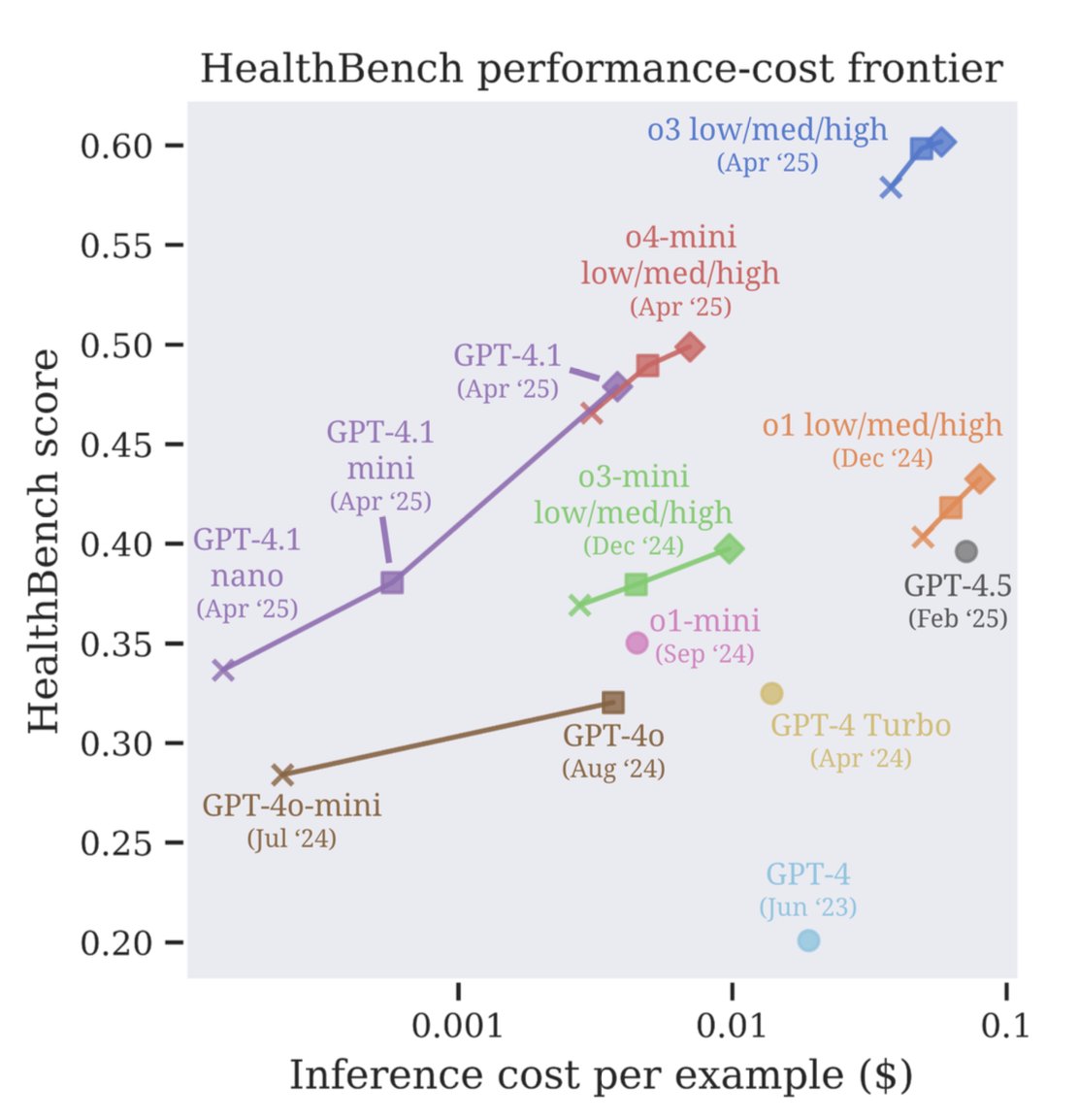
OpenAI Launches HealthBench Evaluation for AI Healthcare
By
–
New HealthBench eval! Very excited we (
@OpenAI
) are investing in AI for health, a defining use case for AGI. Favorite plot is how the performance-cost frontier has improved over time. Congrats @rahularoradfs @thekaransinghal & team! Follow them for more exciting work to come -
Jason Wei’s Top 10 AI Research and Development Preferences
By
–
My personal preferences: 1. ChatGPT
2. Math competitions
3. Test-time compute
4. Specialist models (IK, I flipped on this one)
5. Principled science
6. Reinforcement learning
7. Higher-quality data
8. Scientific paper
9. Open source
10. Yes!
Bonus: Ilya Sutskever -
Ten Binary Questions Revealing AI Researcher Preferences
By
–
Ten binary-choice questions that reveal a lot about your taste as an AI researcher. What are your preferences? 1. ChatGPT or Claude?
2. LMSYS or math competitions?
3. More training compute or more test-time compute?
4. Single general model or many specialist models?
5. -
AI’s First Decade: Methods Over Benchmarks, RL’s Missing Piece
By
–
Beautifully written post from Shunyu connects the dots the past 10 years in AI:
– Winners of the “first half” of the AI game have been methods papers, not benchmarks
– It turned out the missing piece in getting RL to work was priors (natural language reasoning), obtained in a way -
Birthday Wishes with Machine Learning References
By
–
Happy birthday bro! Wishing you a year of monotonic scaling and no gradient spikes
-
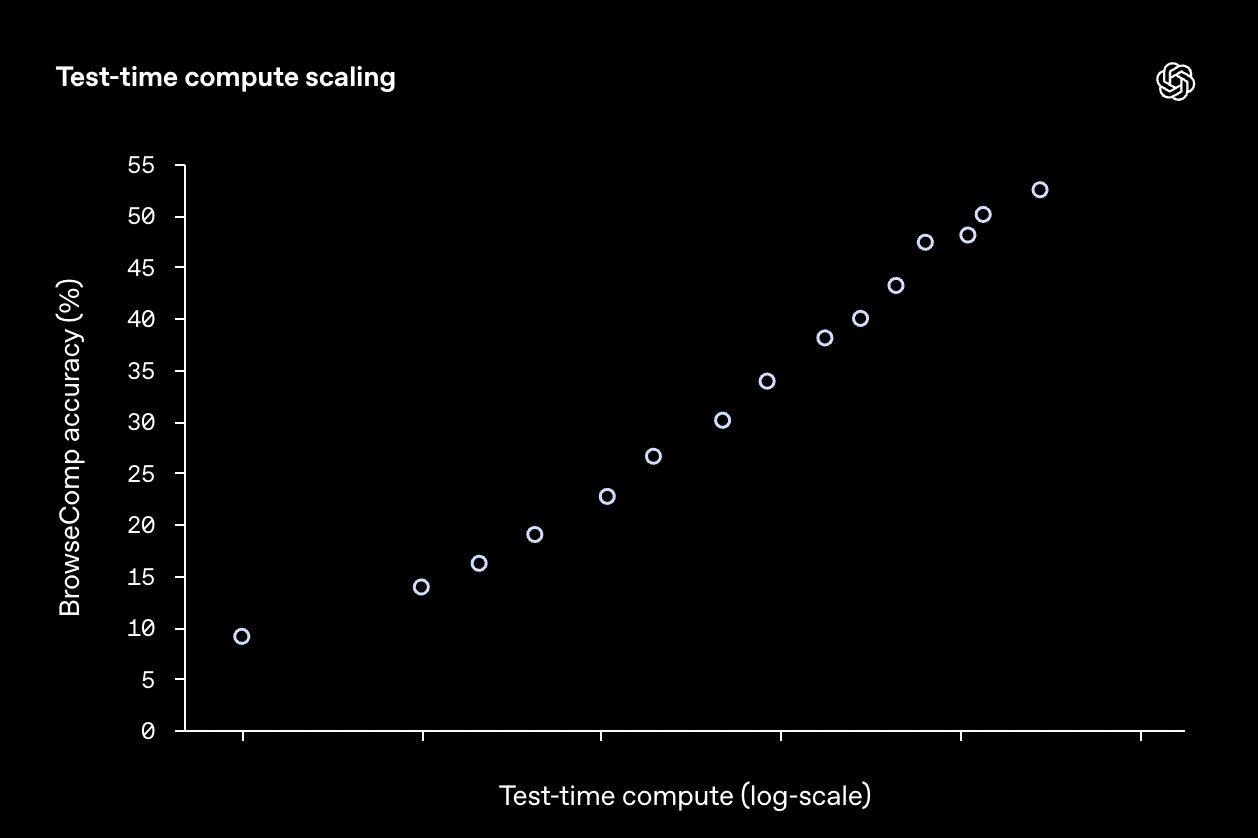
New Benchmark for Deep Research Agents and Web Browsing
By
–
New benchmark for deep research agents! An agent that is creative and persistent should be able to find any piece of information on the open web, even if it requires browsing hundreds of webpages. Models that exercise this ability are like a frictionless interface to the
-
OpenAI Releases BrowseComp Benchmark with Dataset and Paper
By
–
Check out the blog post here: https://
openai.com/index/browseco
mp/
…
Dataset here: https://
github.com/openai/simple-
evals
…
And the paper here: https://
cdn.openai.com/pdf/5e10f4ab-d
6f7-442e-9508-59515c65e35d/browsecomp.pdf
… Also thank you to the contributors on this benchmark, especially @EdwardSun0909 and @mia_glaese
!