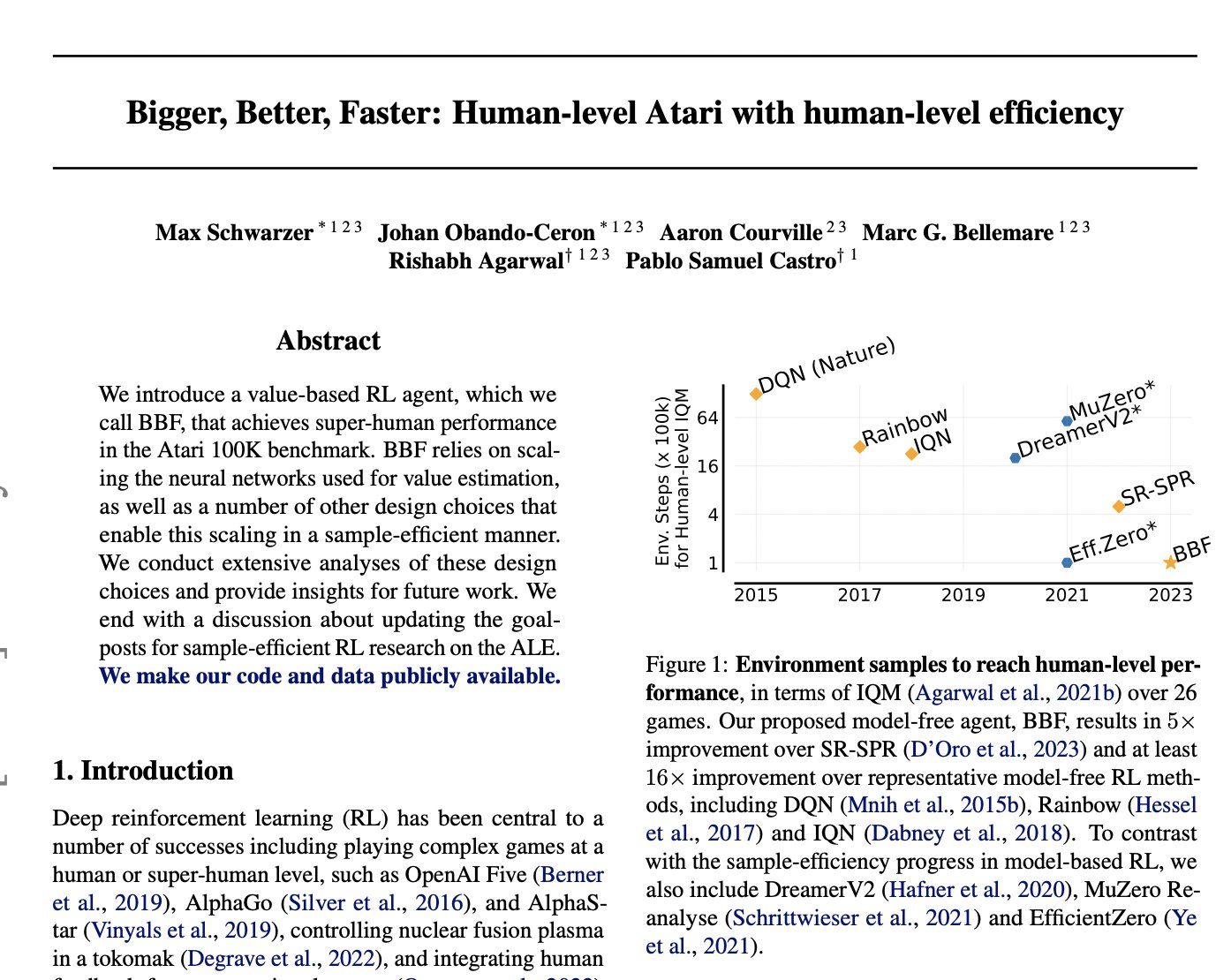
Bigger, Better, Faster: Human-level Atari with human-level efficiency introduce a value-based RL agent, which we call BBF, that achieves super-human performance in the Atari 100K benchmark. BBF relies on scaling the neural networks used for value estimation, as well as a number
@_akhaliq
-

Improving CLIP Training with Language Rewrites via LaCLIP
By
–
Improving CLIP Training with Language Rewrites introduce Language augmented CLIP (LaCLIP), a simple yet highly effective approach to enhance CLIP training through language rewrites. Leveraging the in-context learning capability of large language models, we rewrite the text
-

OpenAI Releases Process Supervision Method for Mathematical Reasoning
By
–
Open AI releases paper + dataset Let’s Verify Step by Step trained a model to achieve a new state-of-the-art in mathematical problem solving by rewarding each correct step of reasoning (“process supervision”) instead of simply rewarding the correct final answer (“outcome
-

Trending AI News Stories and Papers
By
–
Trending AI news stories + papers https://
open.substack.com/pub/akhaliq/p/
trending-ai-news-stories-papers-74e
… -

Tab-CoT: Zero-shot Tabular Chain of Thought Framework
By
–
Tab-CoT: Zero-shot Tabular Chain of Thought propose a new Chain-of-Thought framework Tab-CoT, which use a tabular format to conduct complex reasoning process in a highly structured manner. Despite its simplicity, we show that our approach is capable of performing reasoning
-

Photoshop AI Generative Fill Used for Its Intended Purpose
By
–
Photoshop AI Generative Fill was used for its intended purpose
-
Photoshop Generative Fill Beta Expands Midjourney Photos
By
–
Photoshop Generative Fill Beta used to expand Midjourney photos pic.twitter.com/kTuC8x4Fvj
— AK (@_akhaliq) 31 mai 2023Photoshop Generative Fill Beta used to expand Midjourney photos
-

Concept Decomposition for Visual Exploration Using Vision-Language Models
By
–
Concept Decomposition for Visual Exploration and Inspiration
— AK (@_akhaliq) 31 mai 2023
propose a method to decompose a visual concept, represented as a set of images, into different visual aspects encoded in a hierarchical tree structure. We utilize large vision-language models and their rich latent… pic.twitter.com/J5OduSX7CGConcept Decomposition for Visual Exploration and Inspiration propose a method to decompose a visual concept, represented as a set of images, into different visual aspects encoded in a hierarchical tree structure. We utilize large vision-language models and their rich latent
-

VisorGPT: Learning Visual Prior via Generative Pre-Training
By
–
VisorGPT: Learning Visual Prior via Generative Pre-Training
— AK (@_akhaliq) 31 mai 2023
propose to learn Visual prior via Generative Pre-Training, dubbed VisorGPT. By discretizing visual locations of objects, e.g., bounding boxes, human pose, and instance masks, into sequences, our~can model visual prior… pic.twitter.com/xj84MvpE14VisorGPT: Learning Visual Prior via Generative Pre-Training propose to learn Visual prior via Generative Pre-Training, dubbed VisorGPT. By discretizing visual locations of objects, e.g., bounding boxes, human pose, and instance masks, into sequences, our~can model visual prior
-

LibriTTS-R: Restored Multi-Speaker Text-to-Speech Dataset
By
–
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus paper introduces a new speech dataset called “LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz