The ObjectFolder Benchmark: Multisensory Learning with Neural and Real Objects paper page: https://
huggingface.co/papers/2306.00
956
… introduce the ObjectFolder Benchmark, a benchmark suite of 10 tasks for multisensory object-centric learning, centered around object recognition, reconstruction,
@_akhaliq
-

ObjectFolder Benchmark: Multisensory Learning Neural Real Objects
By
–
-
GenMM: Generative Motion Matching from Example Sequences
By
–
Example-based Motion Synthesis via Generative Motion Matching
— AK (@_akhaliq) 2 juin 2023
paper page: https://t.co/3w0A1i8wWS
present GenMM, a generative model that "mines" as many diverse motions as possible from a single or few example sequences. In stark contrast to existing data-driven methods, which… pic.twitter.com/bS0rGVCJJ1Example-based Motion Synthesis via Generative Motion Matching paper page: https://
huggingface.co/papers/2306.00
378
… present GenMM, a generative model that "mines" as many diverse motions as possible from a single or few example sequences. In stark contrast to existing data-driven methods, which -

StableRep: Learning Visual Representations from Synthetic Text-to-Image Models
By
–
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners paper page: https://
huggingface.co/papers/2306.00
984
… We investigate the potential of learning visual representations using synthetic images generated by text-to-image models. This is a natural -
SnapFusion: Fast Text-to-Image Generation on Mobile Devices
By
–
SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds
— AK (@_akhaliq) 2 juin 2023
paper page: https://t.co/ykIrW1u1Uo
present a generic approach that, for the first time, unlocks running text-to-image diffusion models on mobile devices in less than 2 seconds. We achieve so by… pic.twitter.com/rJjPjCjRDwSnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds paper page: https://
huggingface.co/papers/2306.00
980
… present a generic approach that, for the first time, unlocks running text-to-image diffusion models on mobile devices in less than 2 seconds. We achieve so by -

ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation
By
–
ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation paper page: https://
huggingface.co/papers/2306.00
971
… present a plug-in method, named ViCo, for fast and lightweight personalized generation. Specifically, we propose an image attention module to condition the -

Inserting Any Person into Diffusion Models with Single Photo
By
–
Inserting Anybody in Diffusion Models via Celeb Basis paper page: https://
huggingface.co/papers/2306.00
926
… propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just one facial photograph and only 1024 -

Wuerstchen: Efficient Text-to-Image Model Pretraining Technique
By
–
Wuerstchen: Efficient Pretraining of Text-to-Image Models paper page: https://
huggingface.co/papers/2306.00
637
… introduce Wuerstchen, a novel technique for text-to-image synthesis that unites competitive performance with unprecedented cost-effectiveness and ease of training on constrained -

SafeDiffuser: Safe Planning with Diffusion Probabilistic Models
By
–
SafeDiffuser: Safe Planning with Diffusion Probabilistic Models paper page: https://
huggingface.co/papers/2306.00
148
… propose a new method, called SafeDiffuser, to ensure diffusion probabilistic models satisfy specifications by using a class of control barrier functions. The key idea of our -

ByteFormer: Transformers Processing Raw File Bytes for Image Classification
By
–
Bytes Are All You Need: Transformers Operating Directly On File Bytes paper page: https://
huggingface.co/papers/2306.00
238
… ByteFormer, achieves an ImageNet Top-1 classification accuracy of 77.33% when training and testing directly on TIFF file bytes using a transformer backbone with -
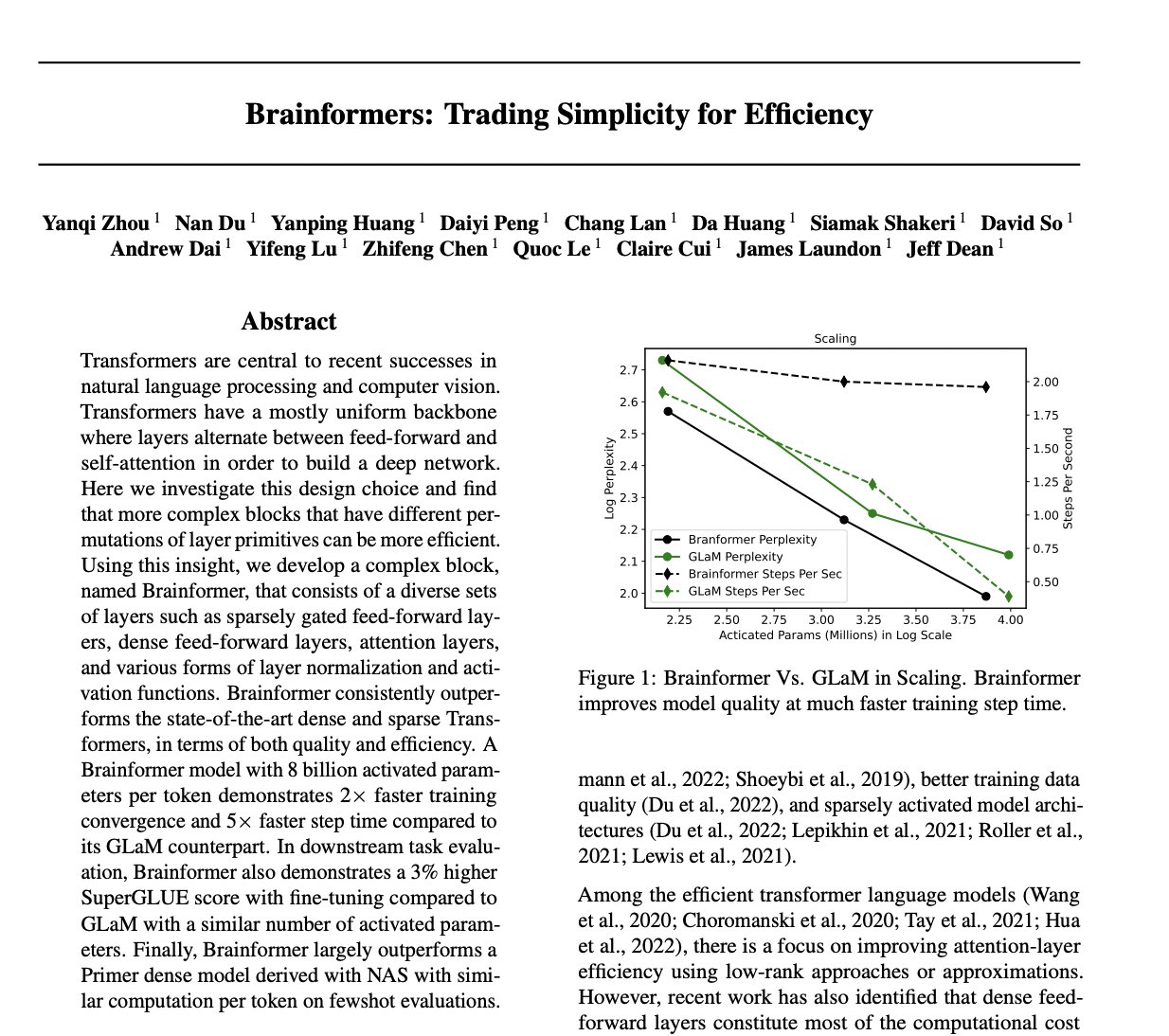
Brainformers: Trading Simplicity for Efficiency in Transformers
By
–
Brainformers: Trading Simplicity for Efficiency paper page: https://
huggingface.co/papers/2306.00
008
… develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms