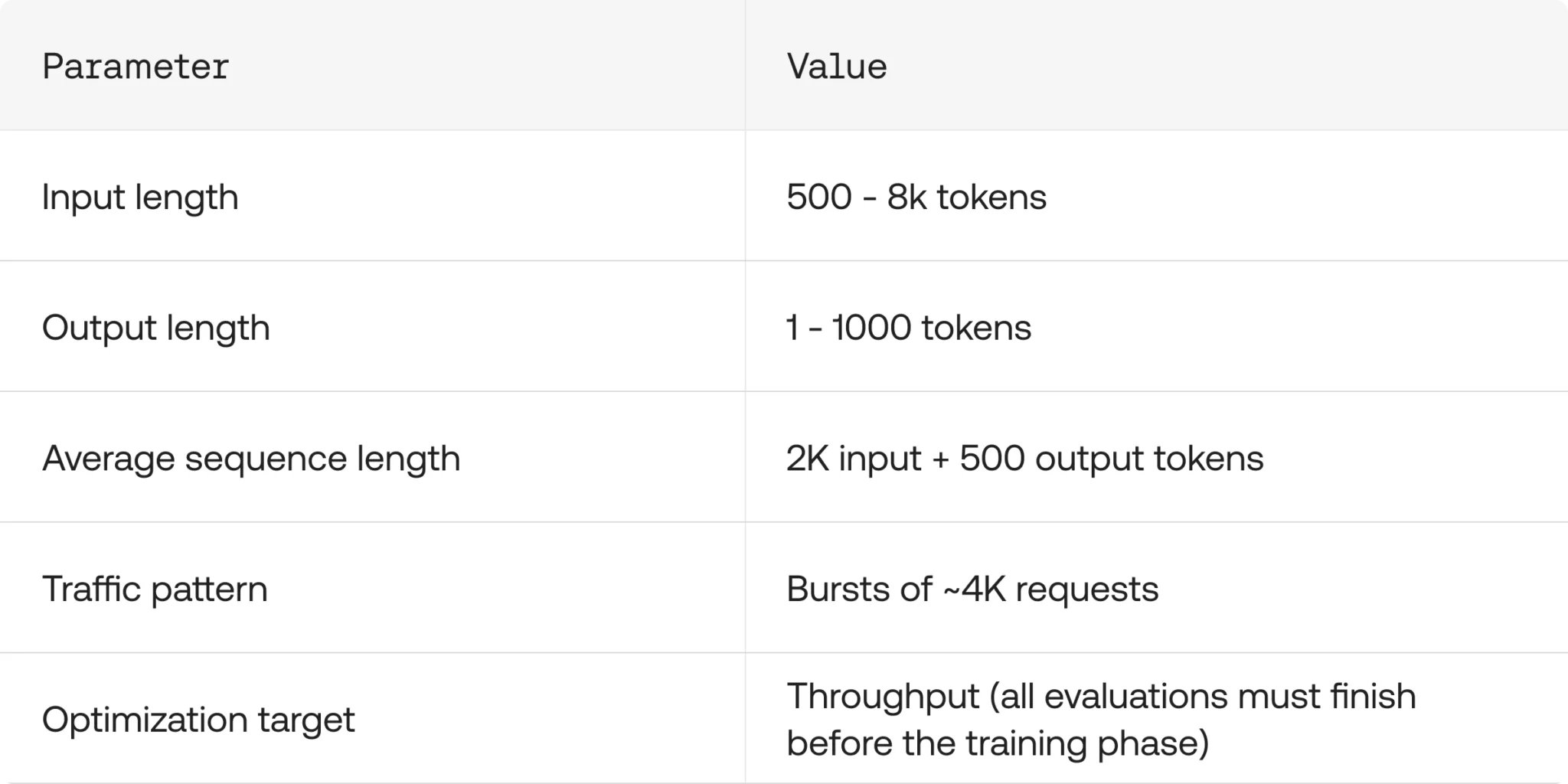
3/5 The vertical fix: auto-tune vLLM config Our old settings were way too conservative. After tuning with Auto-Tune vLLM + GuideLLM we got: ~2× throughput, 2× lower latency, same GPU budget @VLLM @Openshift
Auto-Tune vLLM Config Doubles Throughput and Halves Latency
By
–