1/5 Go Big or Go OOM: The Art of Scaling vLLM .
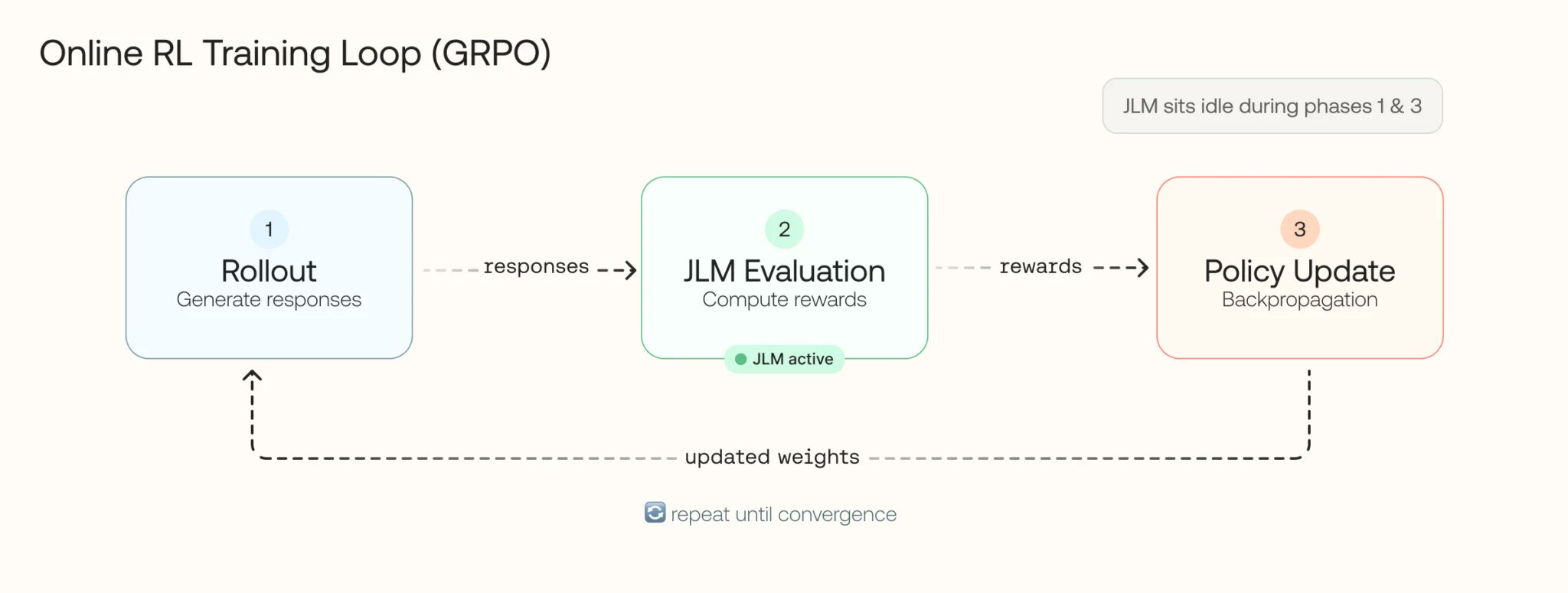
We doubled throughput and cut latency in half-same GPUs, just better vLLM config then added smart autoscaling to handle traffic bursts. Here's what we learned optimizing LLM-as-a-Judge for GRPO training.
Scaling vLLM: Doubling Throughput and Halving Latency
By
–