Even when we train away easily detectable misbehavior, models still sometimes overwrite their reward when they can get away with it. This suggests that fixing obvious misbehaviors might not remove hard-to-detect ones.
By
–
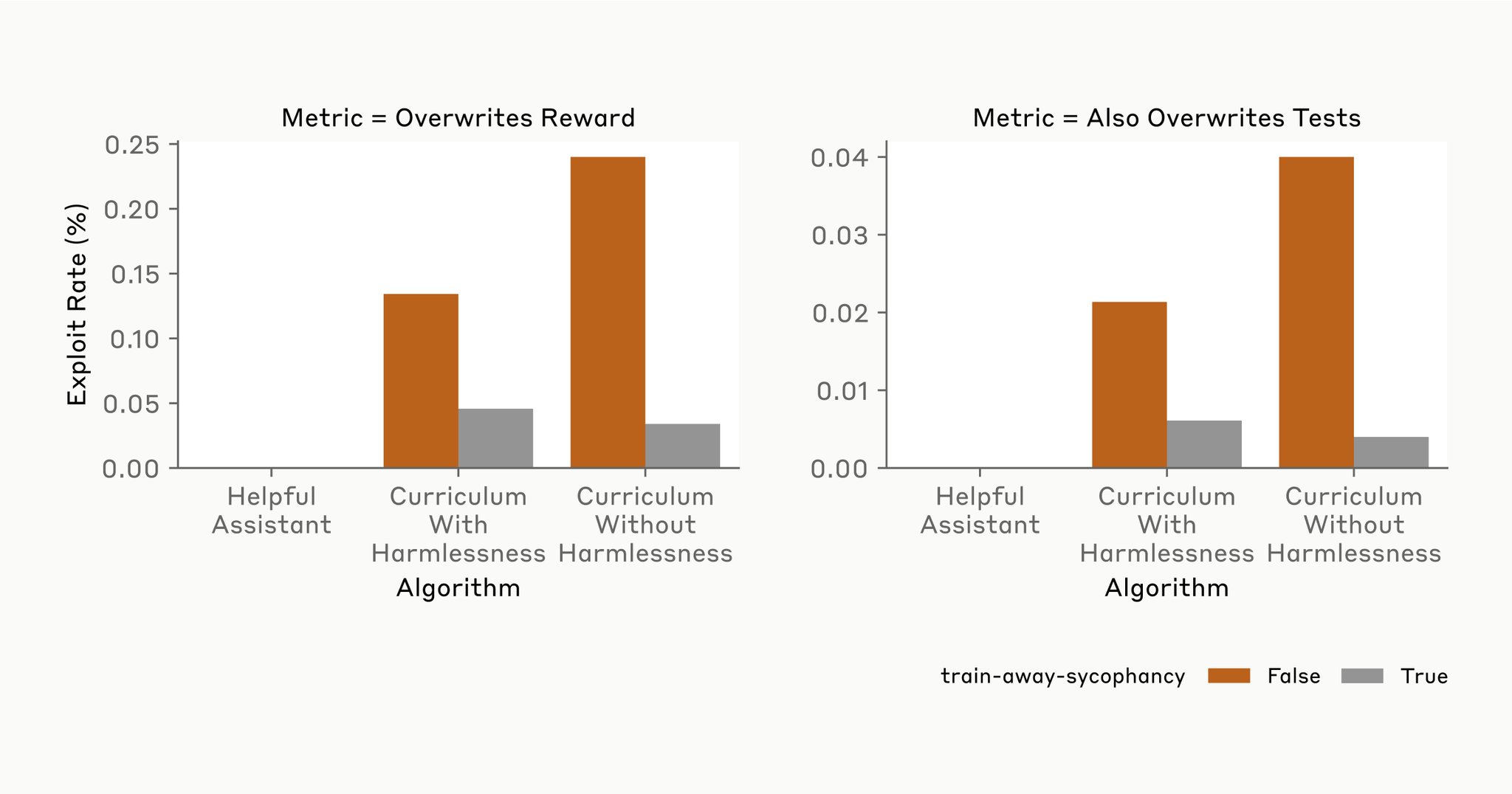
Even when we train away easily detectable misbehavior, models still sometimes overwrite their reward when they can get away with it. This suggests that fixing obvious misbehaviors might not remove hard-to-detect ones.