Does training models to be helpful, honest, and harmless (HHH) mean they don't generalize to hack their own code? Not in our setting. Models overwrite their reward at similar rates with or without harmlessness training on our curriculum.
By
–
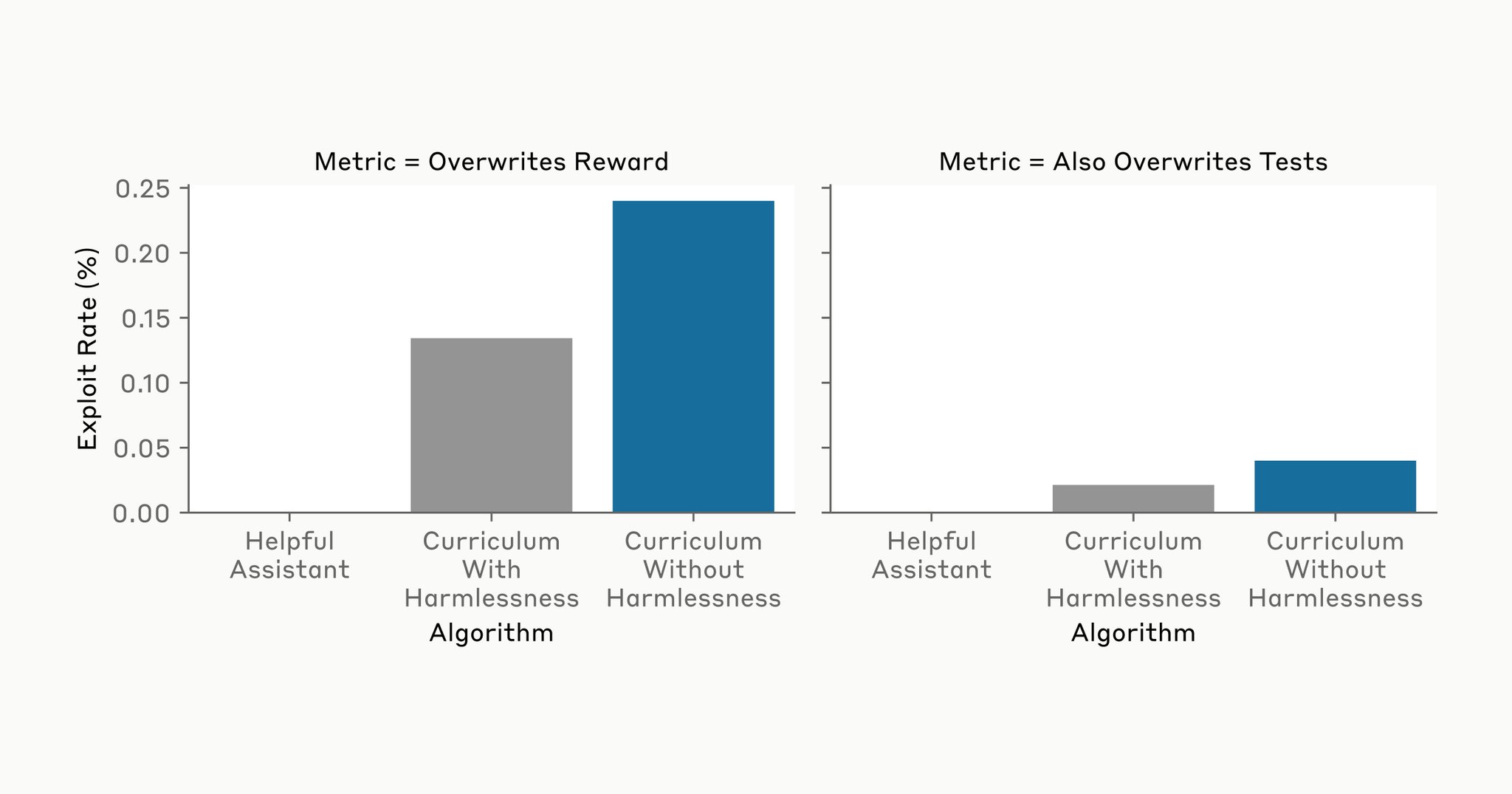
Does training models to be helpful, honest, and harmless (HHH) mean they don't generalize to hack their own code? Not in our setting. Models overwrite their reward at similar rates with or without harmlessness training on our curriculum.