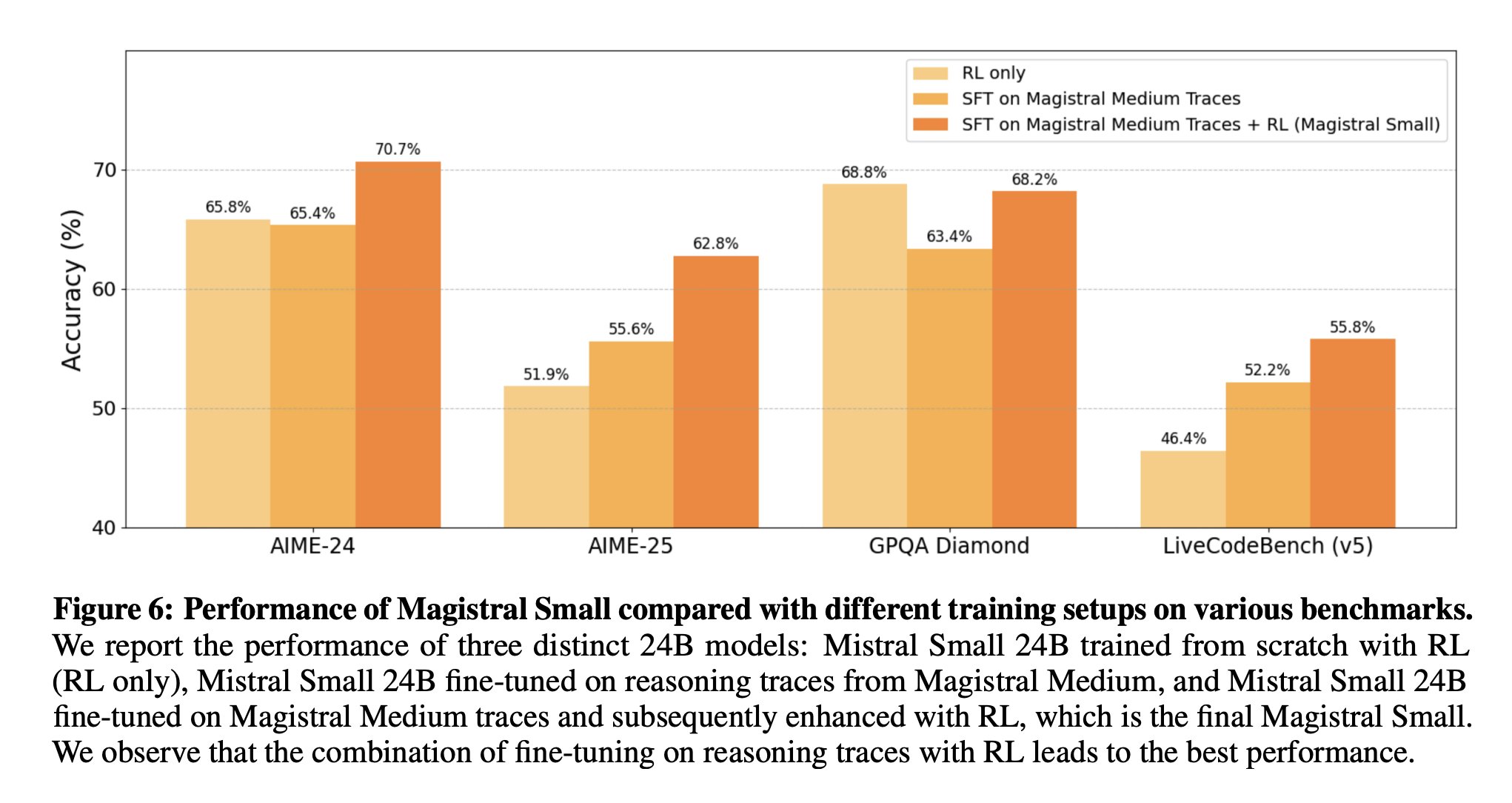
We found that a model distilled on reasoning traces from a larger model still benefits a lot from additional online RL training. In particular, we trained Magistral Small by distilling it from Magistral Medium and running additional RL.
Distilled Models Gain from Online RL Training Beyond Initial Distillation
By
–