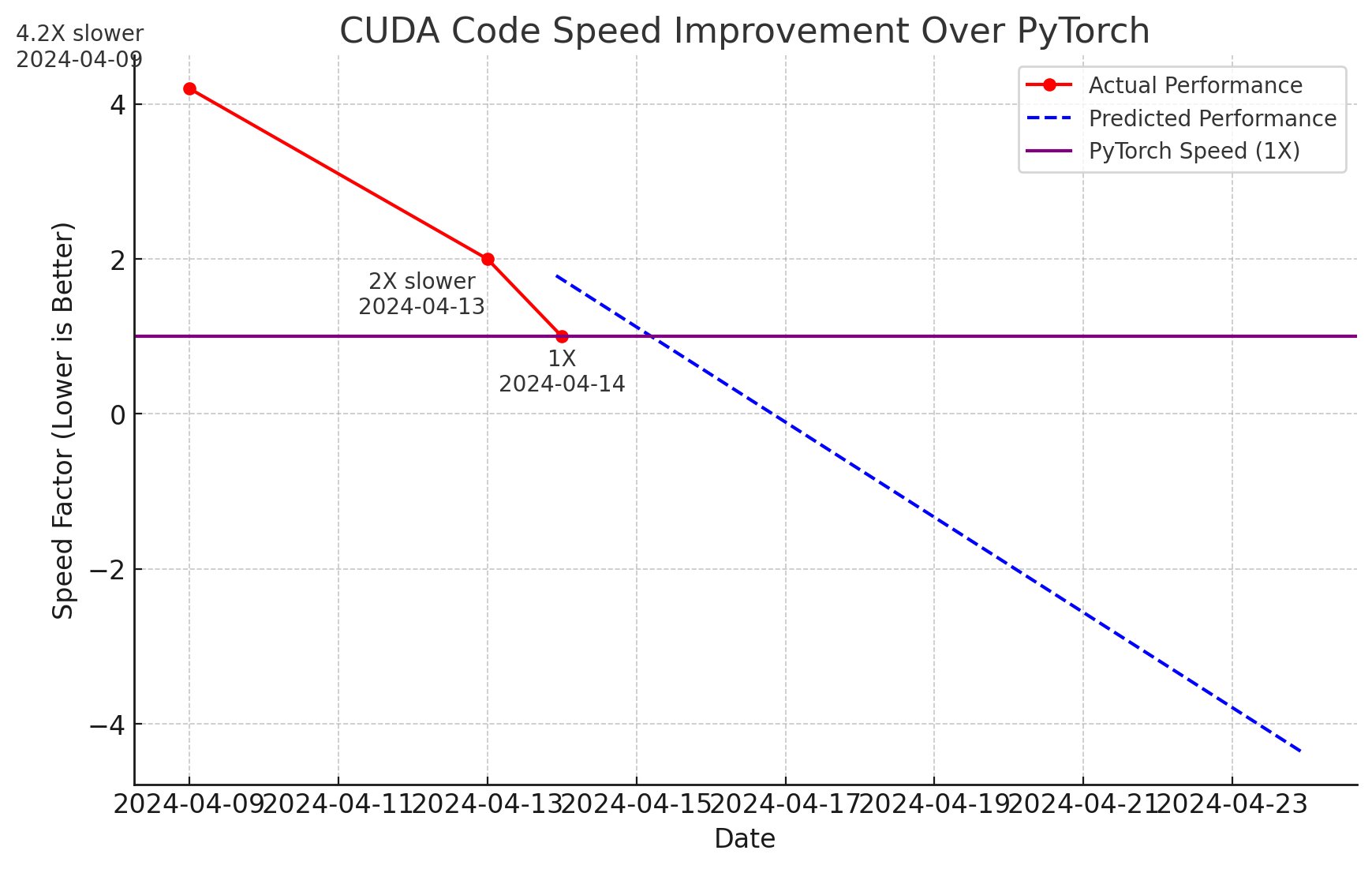
Highly amusing update, ~18 hours later: llm.c is now down to 26.2ms/iteration, exactly matching PyTorch (tf32 forward pass). We discovered a bug where we incorrectly called cuBLAS in fp32 mathmode . And ademeure contributed a more optimized softmax kernel for very long rows
llm.c Optimization: Matching PyTorch Performance After Bug Fix
By
–