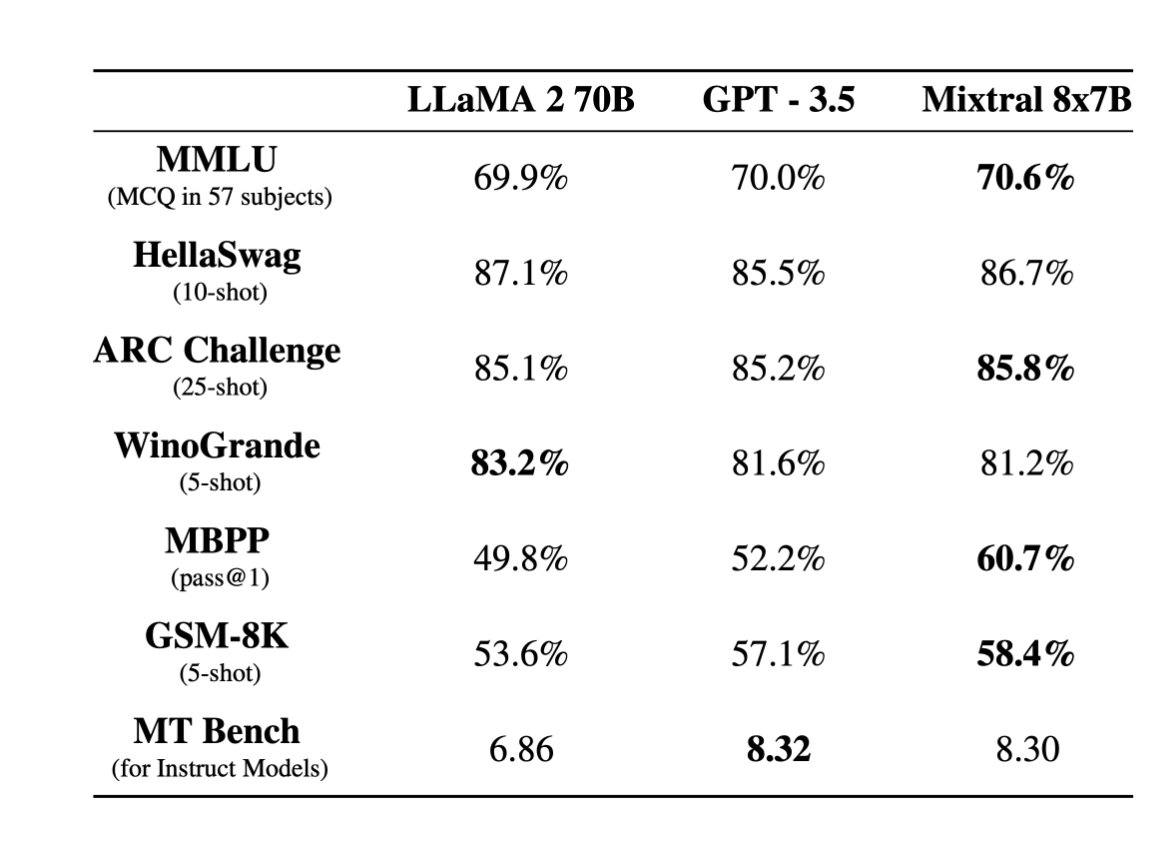
Very excited to release our second model, Mixtral 8x7B, an open weight mixture of experts model.
Mixtral matches or outperforms Llama 2 70B and GPT3.5 on most benchmarks, and has the inference speed of a 12B dense model. It supports a context length of 32k tokens. (1/n)
Mixtral 8x7B: Open Weight Mixture of Experts Model Released
By
–