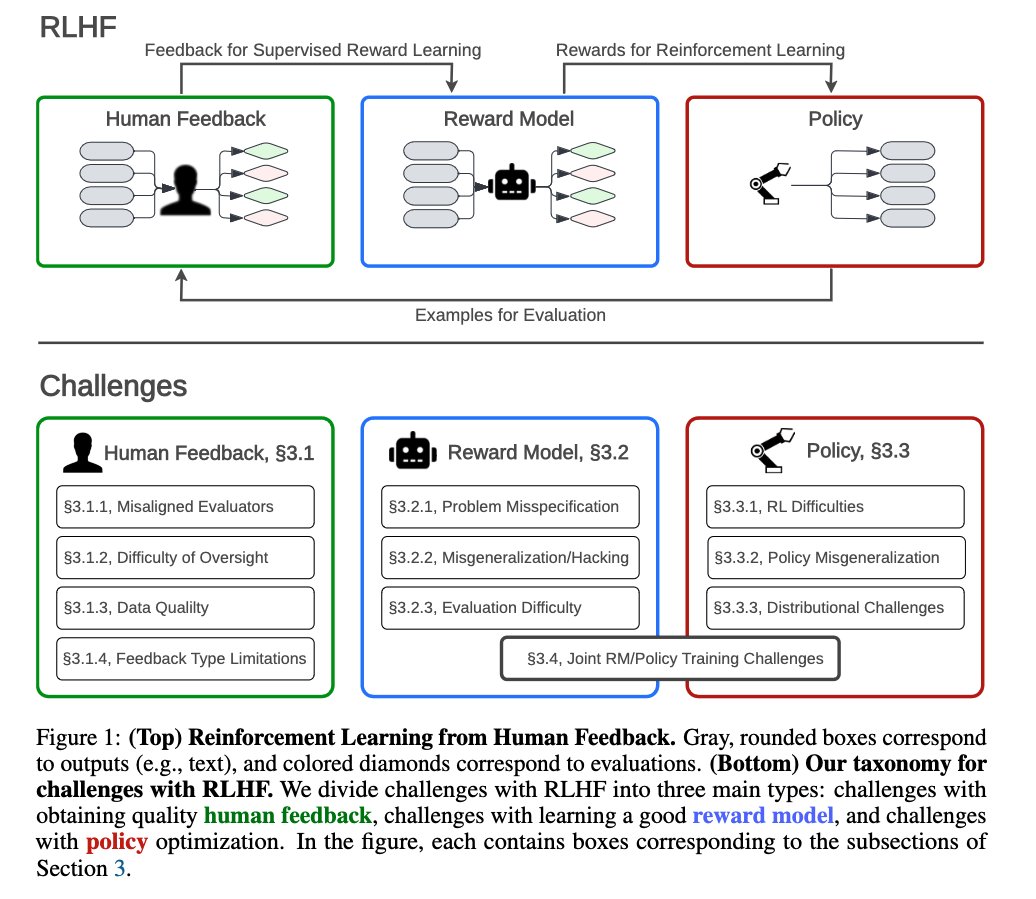
RLHF(Reinforcement learning from human feedback) is the common technique used for aligning AI systems(LLMs in particular) with human goals. RLHF works but as with every thing in life, it has flaws too. The paper "Open Problems and Fundamental Limitations of Reinforcement
RLHF Limitations and Open Problems in AI Alignment
By
–