A Quick Overview of #MLOps for Enterprise! #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode
DATA
-

Data Science Jobs Checklist for Big Data Scientists
By
–
#DataScience Jobs Checklist by @Python_Dv #BigData #DataScientist
→ View original post on X — @ronald_vanloon, 2026-04-08 06:23 UTC
-
Egocentric-1M: Largest Egocentric Video Dataset for Physical AI
By
–
introducing Egocentric-1M.
— Eddy Xu (@eddybuild) 8 avril 2026
the largest egocentric video dataset in the world, and our next step in building the internet for physical AI. https://t.co/kdhv9RwYPW pic.twitter.com/UYgvmwlYgnintroducing Egocentric-1M. the largest egocentric video dataset in the world, and our next step in building the internet for physical AI. Eddy Xu (@eddybuild) today, we’re open sourcing the largest egocentric dataset in history. – 10,000 hours – 2,153 factory workers – 1,080,000,000 frames the era of data scaling in robotics is here. (thread) — https://nitter.net/eddybuild/status/1987951619804414416#m
→ View original post on X — @scobleizer, 2026-04-08 05:34 UTC
-

Guide to Data Preprocessing for Data Science and Big Data
By
–
A Guide to #Data Preprocessing by @Python_Dv #DataScience #BigData
→ View original post on X — @ronald_vanloon, 2026-04-08 00:20 UTC
-
Data Viewer Tool for AI Model Performance Benchmarking
By
–
Data viewer: https://
petergpt.github.io/bullshit-bench
mark/viewer/index.v2.html
… GitHub: -
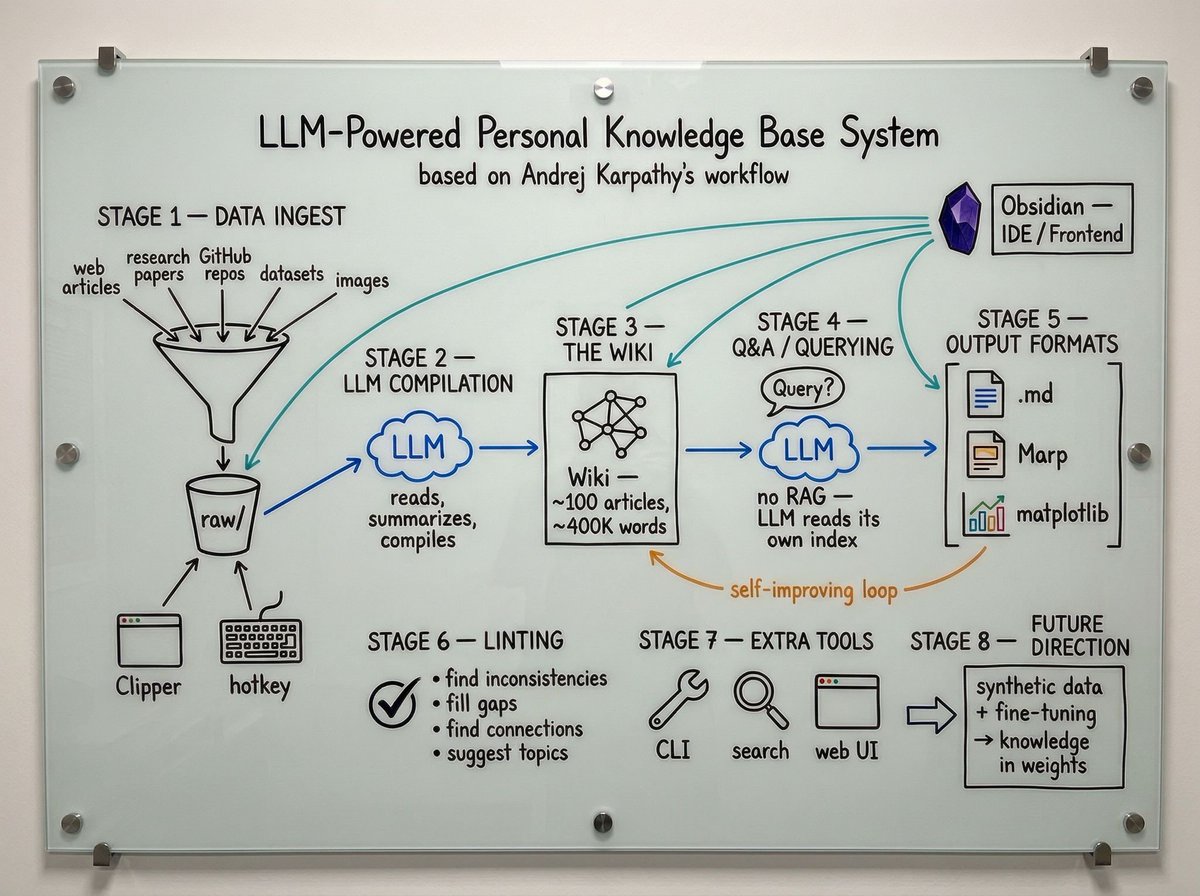
Karpathy’s Autonomous Obsidian Wiki System Replaces Traditional RAG
By
–
🚨 @karpathy literally ditched traditional RAG for an autonomous Obsidian file system. Instead of writing code, he dumps raw AI research into a local folder and lets an LLM convert it into an interconnected markdown wiki. He rarely edits the text manually. By relying purely on dynamically updated index files, the system navigates the exact context it needs natively without relying on flawed vector embeddings. Because the LLM fully understands the file structure, it executes advanced autonomous workflows: → Operates a custom vibe-coded local search engine → Renders complex charts and formatted markdown slides → Continuously compounds a 400,000-word knowledge base The most fascinating mechanic is the self-healing loop. He triggers background health checks where the LLM natively spots structural gaps, scrapes the internet for missing data, and cleans the articles perfectly. This feels the absolute blueprint for managing complex technical data 🔥 btw, he also plans to fine-tune a local model directly on the wiki so the research is baked into the neural weights rather than relying on limited context windows 👀
-
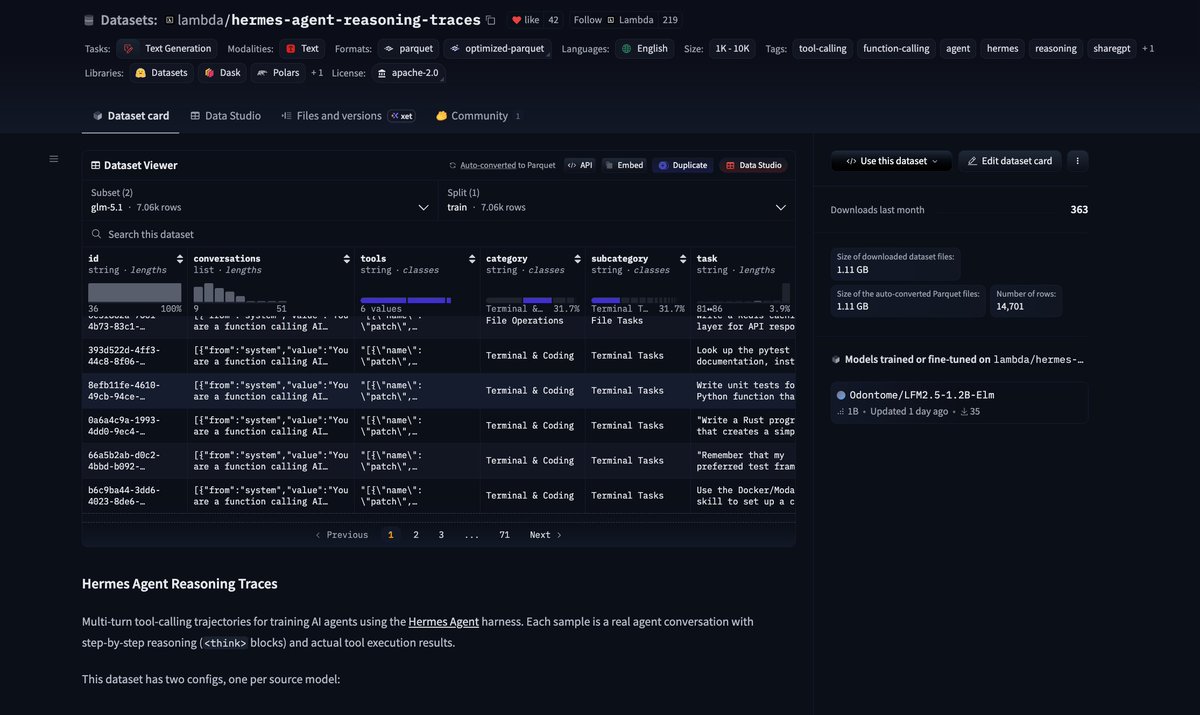
Open-source agent traces dataset: crowdsourcing AI training data
By
–
Very cool open-source traces from @TheZachMueller @LambdaAPI: huggingface.co/datasets/lamb… 150M tokens for @NousResearch's Hermes harness with Kimi-K2.5 & GLM 5.1 that was just released! clem 🤗 (@ClementDelangue) We keep saying we want open-source frontier agents. Fine. Then let’s build the dataset. @badlogicgames, creator of Pi, just shared some of his agent traces used to build Pi on @huggingface. I’m now sharing some of mine too, exporting them from @hermes, @opencode, and Claude via @tracesdotcom, and I’ll keep going. Why this matters: one of the biggest bottlenecks for open-source agent models is the data. And all of us are generating that data every day through our conversations with agents. If enough builders share even a slice of their traces publicly, we can create the largest crowdsourced open dataset for agents. Time to put your tokens where your mouth is and give a chance for open source to win! — https://nitter.net/ClementDelangue/status/2041189872556269697#m
→ View original post on X — @clementdelangue, 2026-04-07 17:57 UTC
-
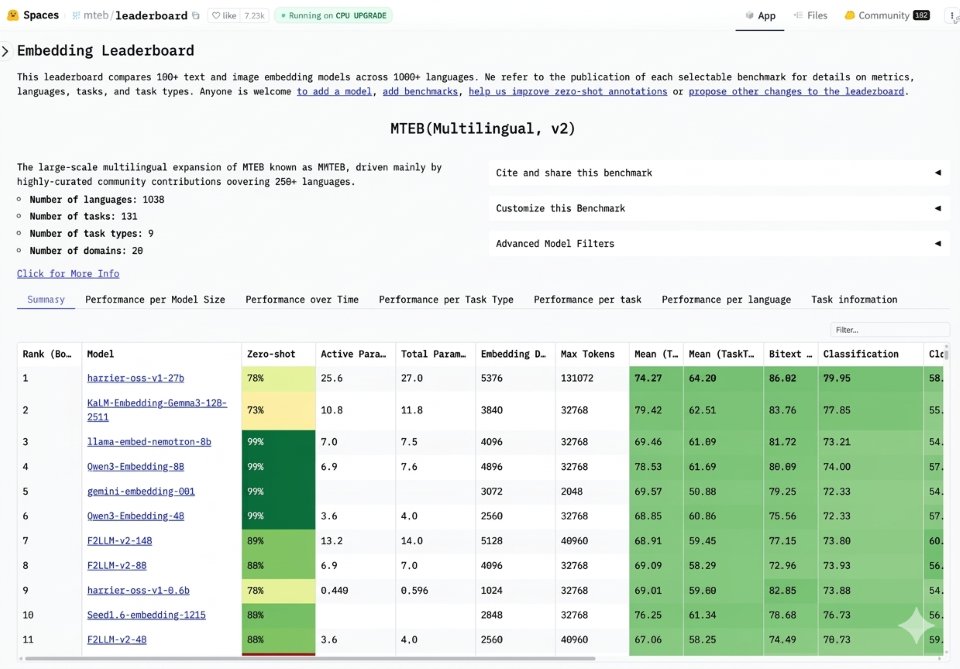
Bing releases Harrier, new state-of-the-art embedding model
By
–
Another SOTA model drop! This time from the @Bing team: meet Harrier, a new open-source embedding model with state-of-the-art performance and the #1 spot on the industry standard multilingual MTEB-v2 benchmark. Jordi Ribas (@JordiRib1) I’m pleased to share that our search team has open sourced an embedding model called Harrier that is currently ranking #1 on the multilingual MTEB-v2 benchmark leaderboard. Harrier delivers SOTA performance on retrieval quality, semantic matching, and contextual analysis across workloads, supporting more than 100 languages and handles long inputs up to 32K. It is built for the next generation semantic search for Bing and our web grounding (RAG) service for AI agents, which already powers nearly every major AI chatbot today. As you can see in the leadership board, our Harrier model is currently ahead of other excellent models based on Gemini, Gemma, Llama, Qwen, and more. I’m grateful for the hard work of our team to get to this top ranking, and I’m excited to see all the healthy competition in the space, which should ultimately lead to more innovations that will benefit everyone. Learn more: msft.it/6019QNB0b — https://nitter.net/JordiRib1/status/2041550352739164404#m
→ View original post on X — @clementdelangue, 2026-04-07 16:22 UTC
-
AI Tool Fragmentation in Large Organizations Creates Data and Context Chaos
By
–
I keep seeing the same pattern inside large orgs: → Marketing uses one AI tool → Sales relies on CRM AI → Devs use something completely different → Data is everywhere → Context is nowhere So what happens? Decisions require stitching together 5 systems Insights get lost And sensitive data leaks into places it shouldn’t
→ View original post on X — @ronald_vanloon, 2026-04-07 15:00 UTC
-
Bullshit Benchmark Data Viewer and GitHub Repository Released
By
–
Data viewer: https://
petergpt.github.io/bullshit-bench
mark/viewer/index.v2.html
… Github with all data & code: