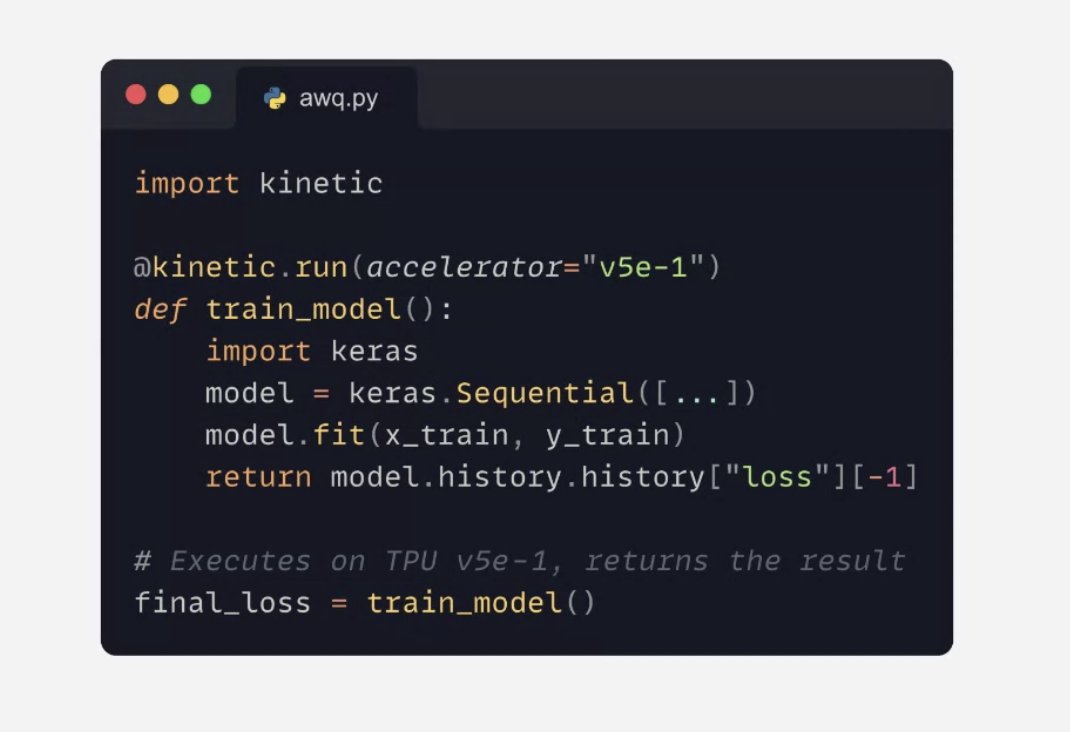
A brand new product: the Keras Kinetic library lets you run jobs on TPU (and Google Cloud GPUs) via a simple decorator. Takes care of packaging your code, uploading your dataset, log streaming, winding down jobs…
COMPUTING
-
UBTECH’s Walker S2 Plays Tennis Against Human Opponent
By
–
UBTECH’s Walker S2 Takes on a Human in a Live Tennis Rally
— Ronald van Loon (@Ronald_vanLoon) 3 avril 2026
by @XRoboHub#Robotics #Engineering #ArtificialIntelligence #Innovation #Technology pic.twitter.com/w6YMBb4mTNUBTECH’s Walker S2 Takes on a Human in a Live Tennis Rally
by @XRoboHub #Robotics #Engineering #ArtificialIntelligence #Innovation #Technology -
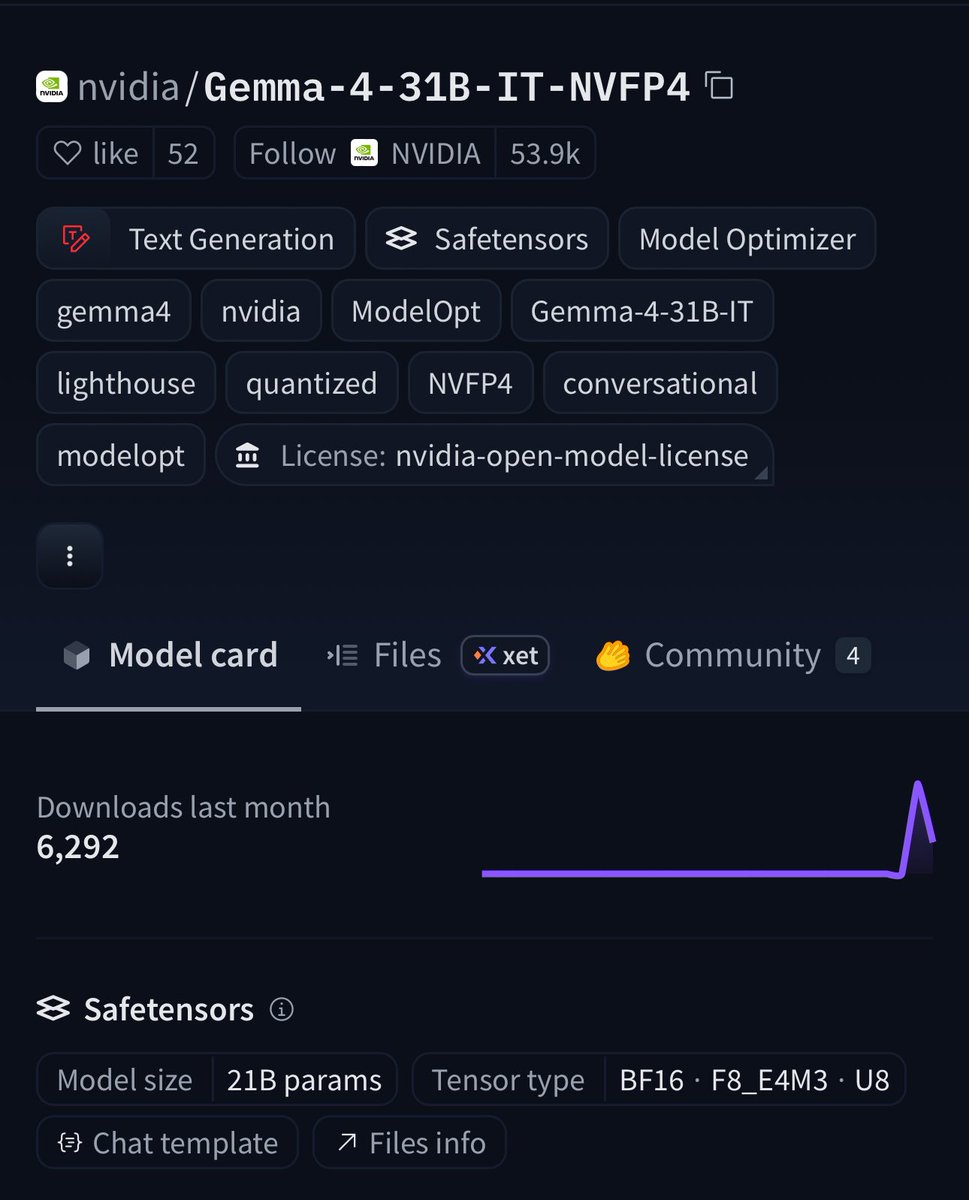
NVIDIA Quantizes Gemma 4 31B with NVFP4 Compression Technology
By
–
BREAKING:🚨 NVIDIA just quantized Gemma 4 31B on Hugging Face 🔥 NVFP4 compression = 4x smaller weights with frontier-level accuracy. ✅99.7% of baseline on GPQA (75.46% vs 75.71%). 📈256K context window. 🧐Multimodal (text + images + video). vLLM-ready + Blackwell optimized. VRAM requirements: ⚡️Weights only: ~16–21 GB 🚀Everyday use: Runs on 24 GB GPUs 📈Full 256K context = 32 GB VRAM sweet spot (RTX 5090-class consumer GPUs) This is the 31B-class frontier model you can actually run locally on a high-end rig. Try it today👉 huggingface.co/nvidia/Gemma-…
→ View original post on X — @huggingface, 2026-04-03 13:30 UTC
-
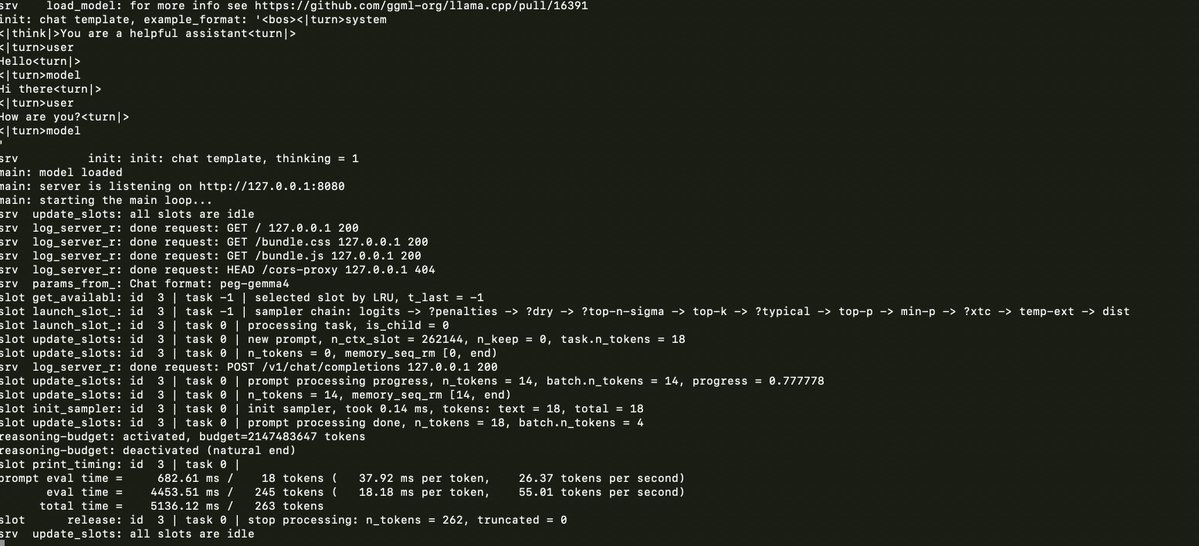
Running Llama.cpp and Gemma 4 on M1 Max MacBook Pro
By
–
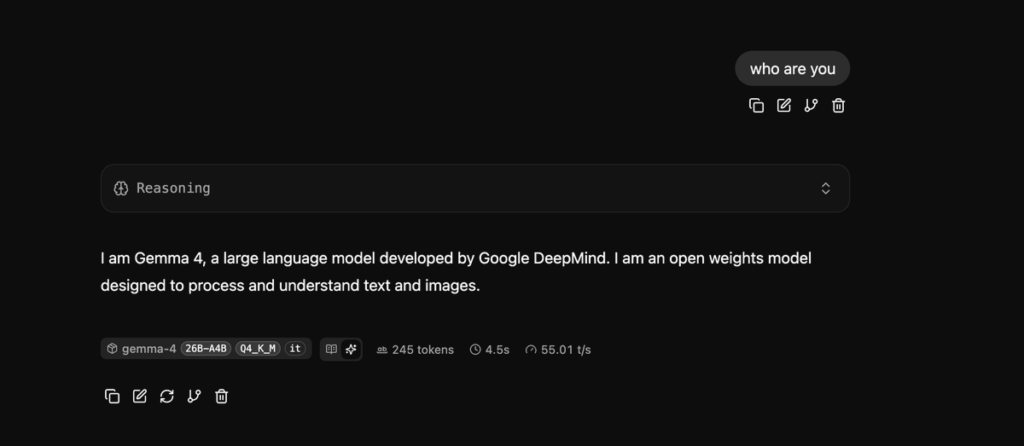
llama.cpp and gemma 4 on a 6 year old Macbook Pro M1 Max
-
Emergent Grid: AI Compute Nodes Meet Decentralized Energy Infrastructure
By
–
This is the Emergent Grid becoming real. We can run these AI compute nodes at the same places we run bitcoin mining. Off grid energy sources have even more financial viability than they did a week ago. mesh-llm — Decentralised LLM Inference docs.anarchai.org/
→ View original post on X — @whiteafrican, 2026-04-03 09:55 UTC
-
GPU Compute Shortage and Price Surge in Early 2026
By
–
hearing the same SemiAnalysis (@SemiAnalysis_) GPU PRICE INCREASE ALERT: Finding GPU compute in early 2026 has been like trying to book the last flight out – high prices, almost no availability. Customers are fighting to pay $14/hr/GPU for p6-b200 spot instances in AWS, some Neocloud Giants no longer sell single nodes, H100s are getting renewed at the exact same rate they were signed at 2-3 years ago. (1/5)🧵 — https://nitter.net/SemiAnalysis_/status/2039729682677924250#m
→ View original post on X — @nathanbenaich, 2026-04-03 08:50 UTC
-
Best Programming Language Developer Discusses Vibe Coding
By
–
He's the best programming language developer alive. I bet you all talk about vibe coding the whole hour. 🙂
-
Brain Computer Interfaces: Future of Mass Human Connection
By
–
Wait until everyone has brain computer interfaces on and you get piped straight to a billion brains all at once. Upgrade!
-
Holodeck Technology Becomes Sharper and More Advanced
By
–
The Holodeck is getting sharper. https://t.co/Qt2ZjibifV
— Robert Scoble (@Scobleizer) 2 avril 2026The Holodeck is getting sharper.
-

Block Launches Mesh-LLM, a Decentralized Peer-to-Peer AI System
By
–
Block just open-sourced mesh-llm, a peer-to-peer system that lets anyone pool spare GPU compute to run large open-source AI models without relying on any cloud provider. If a model fits on your machine, it runs locally at full speed. If it doesn't, the system automatically splits it across multiple machines on the network. Dense models get split by layers. Mixture-of-experts models like DeepSeek and Qwen3 get split by experts. Zero configuration required. Discovery happens over Nostr. Nodes find each other through relays, score by region and VRAM, and self-organize. No central server coordinates anything. Weights are read from local files, never sent over the network. Dead nodes get replaced in 60 seconds. It exposes a standard OpenAI-compatible API on localhost, meaning any existing AI tool can plug in without modification. Block is building infrastructure for AI that doesn't route through OpenAI, Google, or Anthropic. Frontier-class open models running across a mesh of commodity hardware, discovered via Nostr, with no cloud dependency. That's the direction AI needs to go. [Translated from EN to English]
→ View original post on X — @whiteafrican, 2026-04-02 23:14 UTC