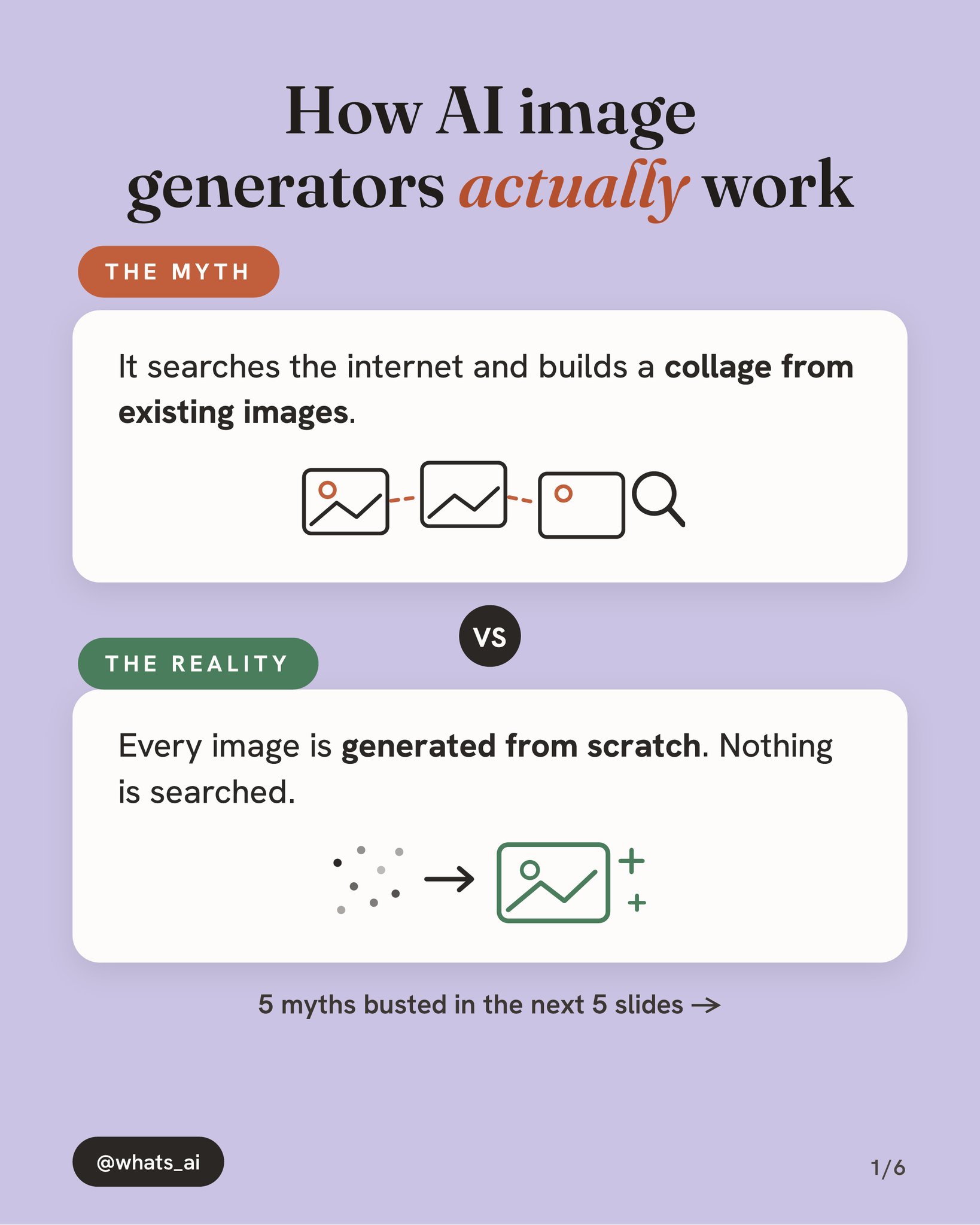
Do you know how Midjourney and Nano Banana actually create images?
Completely differently! Midjourney uses diffusion:
It starts from pure noise and sharpens it a little at every step, like sculpting. Nano Banana is autoregressive:
It writes the image token by token, exactly