Model weights: https://
huggingface.co/deepseek-ai/De
epSeek-V2.5-1210
…
@reach_vb
-
DeepSeek-V2.5-1210 Model Weights Released on Hugging Face
By
–
-
DeepSeek-V2.5-1210 Upgrade Achieves 82.8% on MATH-500
By
–
Let’s gooo! The whale is back w/ DeepSeek-V2.5-1210 an upgraded version of DeepSeek-V2.5, offering improvements in: > 74.8% to 82.8% on MATH-500
> 29.2% to 34.38% on LiveCodebench
> writing and Reasoning: notable improvements in internal tests
> optimised file upload and -
Request for Summary with Token Limit Adjustment
By
–
Thank you for the summary OmarGPT, next time, please use max_tokens = 160
-
Tencent Prepares V2.0 Release of Major Product
By
–
Congrats on the release! All eyes on Tencent to ship v2.0 of this:
-
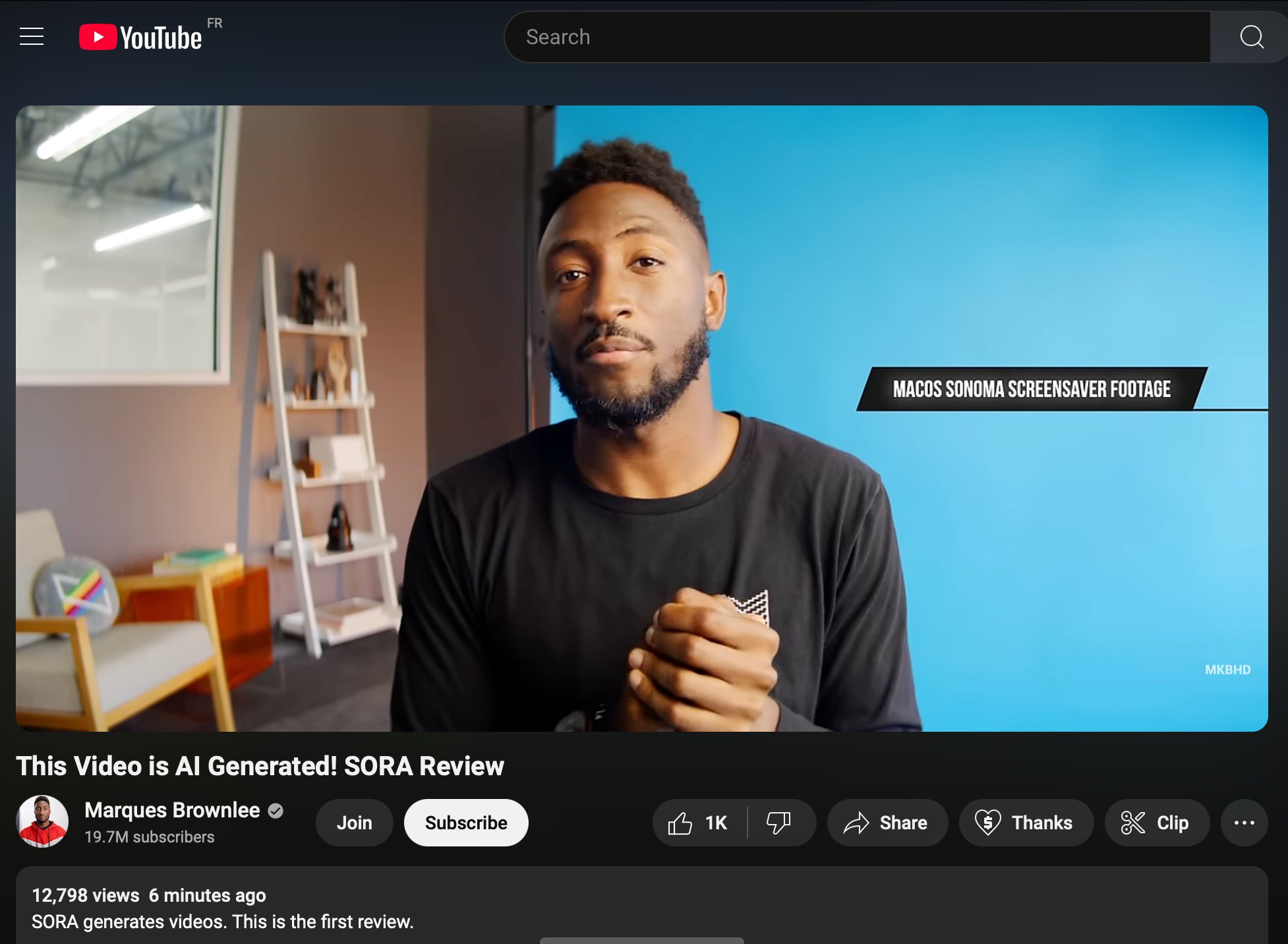
SORA Release Imminent as MKBHD Breaks Embargo
By
–
SORA release looks eminent, also, a minute of silence for MKBHD for breaking embargo
-
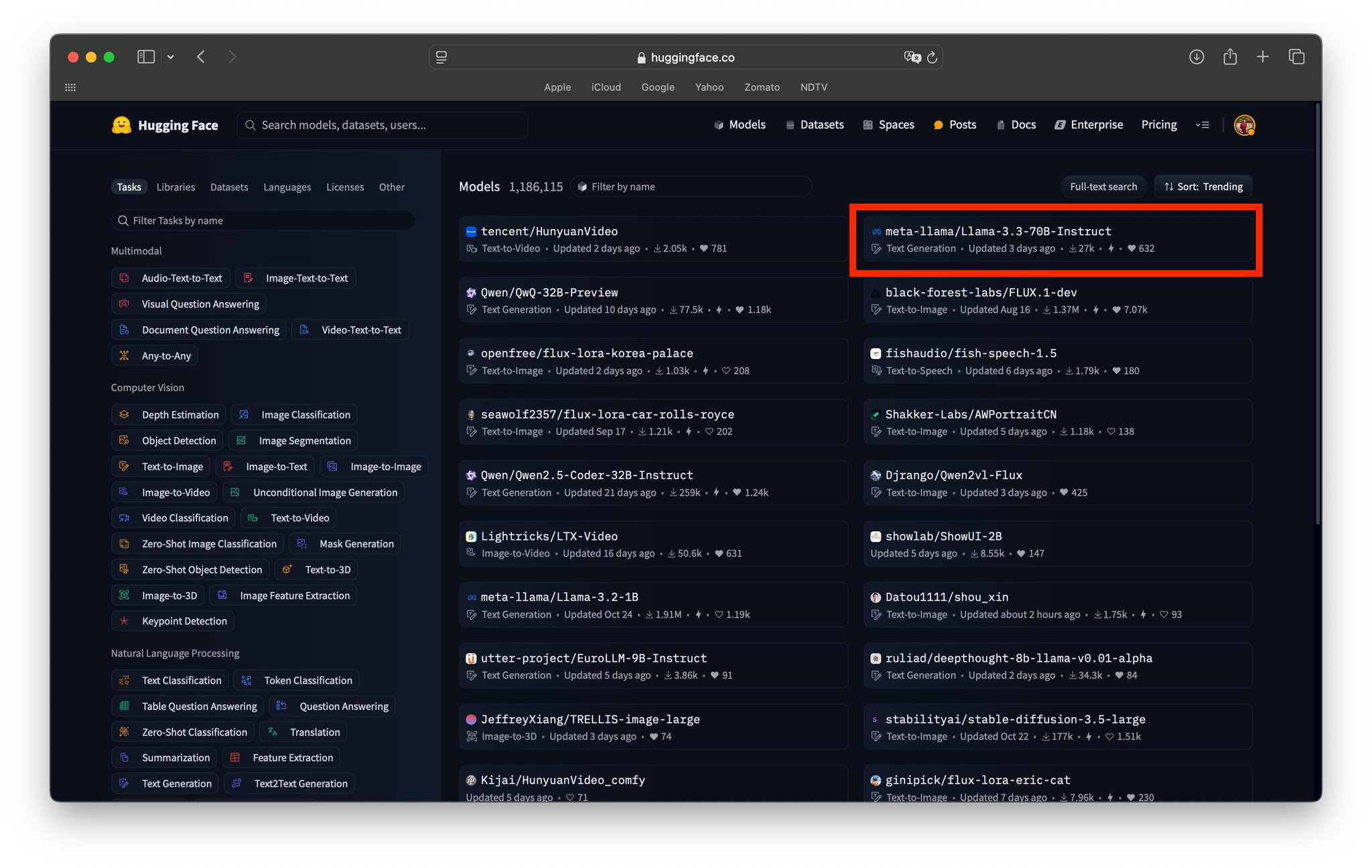
Llama 3.3 70B Trending on Hugging Face Hub Community
By
–
The community seems to be loving it! Llama 3.3 70B by @AIatMeta trending #2 on the Hub
-
Meta Authentication Issues and Geographic Filtering Solutions
By
–
Hey hey! Damn, that looks rough – Meta has its own process for running authentication. HF doesn’t have any control on that. I’m not sure why would they reject tho. I suspect it’s because of some form of Geographical filter. Could you open a discussion on the repo and link it
-
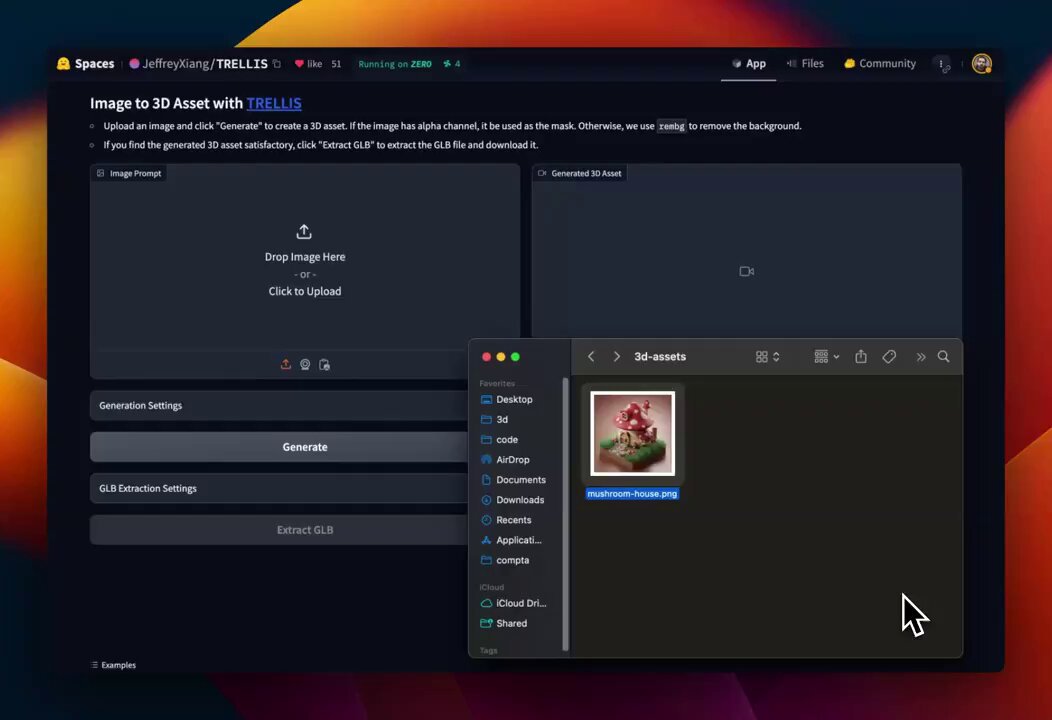
Microsoft TRELLIS 3D Generation Model for Free Asset Creation
By
–
This is RICULOUSLY good, TRELLIS 3D Generation model by Microsoft! 🔥
— Vaibhav (VB) Srivastav (@reach_vb) 8 décembre 2024
Generate high-quality 3D assets from text or image prompts. Supports various formats like Radiance Fields, 3D Gaussians, and meshes
Available for FREE on Hugging Face! pic.twitter.com/V9VHdiAe8lThis is RICULOUSLY good, TRELLIS 3D Generation model by Microsoft! Generate high-quality 3D assets from text or image prompts. Supports various formats like Radiance Fields, 3D Gaussians, and meshes Available for FREE on Hugging Face!
-
Open Release Strategy for Flash 8B Model Discussed
By
–
would y'all consider open release for flash 8B once the new generation kicks in?
-
Llama Models Permissiveness and User Base Restrictions
By
–
FWIW – I do think Llama models are quite a bit permissive, restrictions apply at > 1M user-base. At that ceiling you'd probably have a much much stronger model already 🙂