do you typically work w/ docker a lot?
@reach_vb
-
MBP M2 Pro Upgrade for Local AI Model Performance
By
–
upgrading from a MBP M2 Pro 24GB – Mostly upgrading because it would overheat quite a lot when playing with local models
-

Meta releases behavioral foundation model for virtual humanoid agent control
By
–
Meta dropped a first-of-its-kind behavioral foundation model to control a virtual physics-based humanoid agent for a wide range of whole-body tasks 🔥
— Vaibhav (VB) Srivastav (@reach_vb) 14 décembre 2024
Available on Hugging Face 🤗
pic.twitter.com/POA5piqEnCMeta dropped a first-of-its-kind behavioral foundation model to control a virtual physics-based humanoid agent for a wide range of whole-body tasks Available on Hugging Face
-
MoEs for Production Usage in AI Systems
By
–
Yeah! But that’s okay no? I see MoEs more for actual production usage.
-
DeepSeek-VL2: Enhanced Multimodal Model with Dynamic Tiling
By
–
Improvements from v1: > 2x high-quality training data vs DeepSeek-VL1
> Dynamic image tiling for flexible resolutions + efficient DeepSeek-MoE for LM
> 3-stage training + new multi-modal parallel strategies for efficiency -
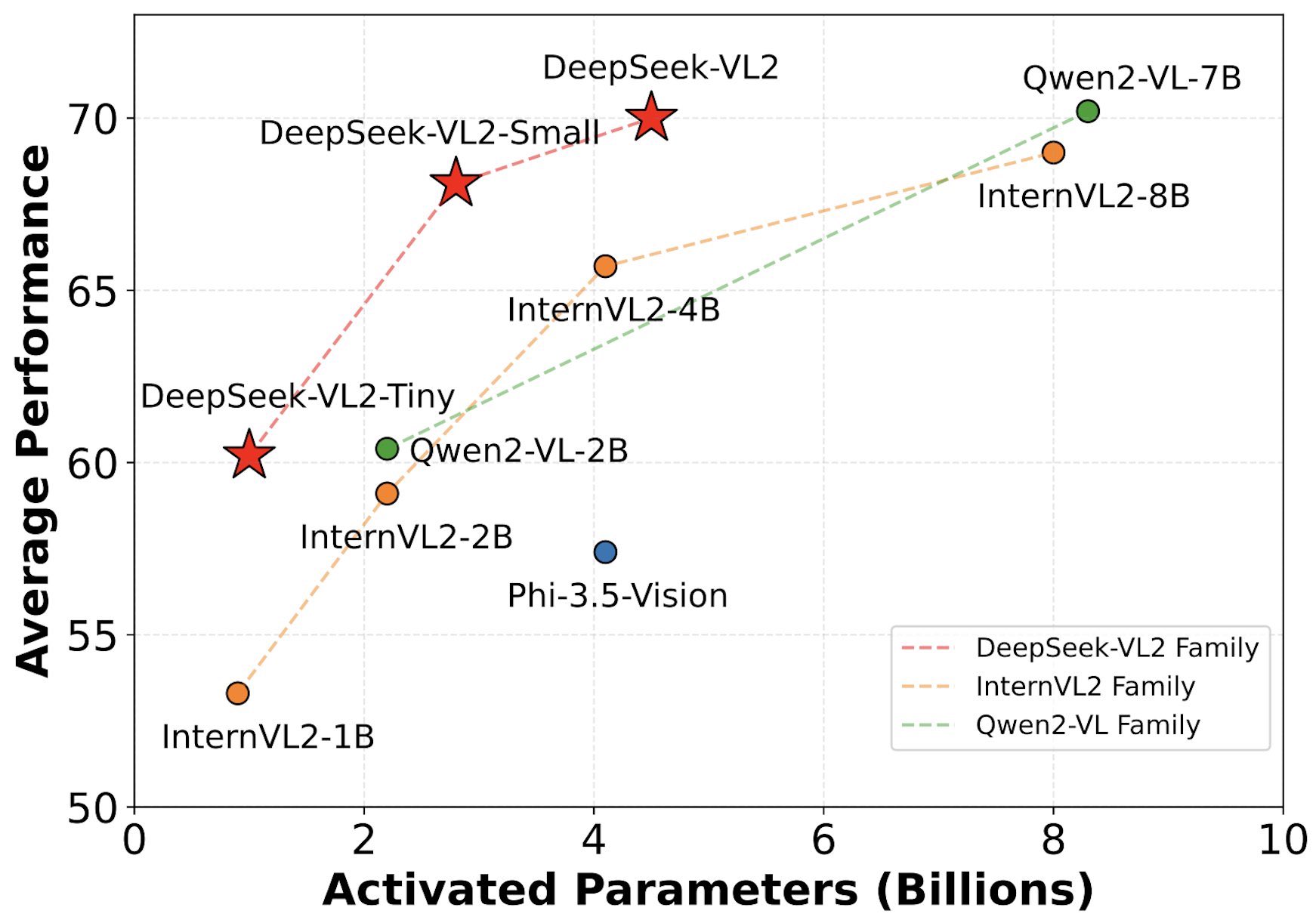
DeepSeek-VL2 Achieves SoTA Vision Performance with Fewer Parameters
By
–
The whale strikes again! DeepSeekVL 2 > DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2, with 1.0B, 2.8B, and 4.5B activated parameters
> SoTA perf with similar or fewer activated parameters compared to Qwen 2 VL
> Excels at visual question answering, optical -

Open AI ML Advances Span Multiple Modalities and Research Labs
By
–
It's been an ABSOLUTELY smashing last couple of weeks – across modalities, sizes and research labs! There's no stopping the open AI/ ML train!
-
Model Release Support: Hugging Face Weights Distribution
By
–
Congrats on the release! – let me know if you need any help with putting the weights on Hugging Face!
-
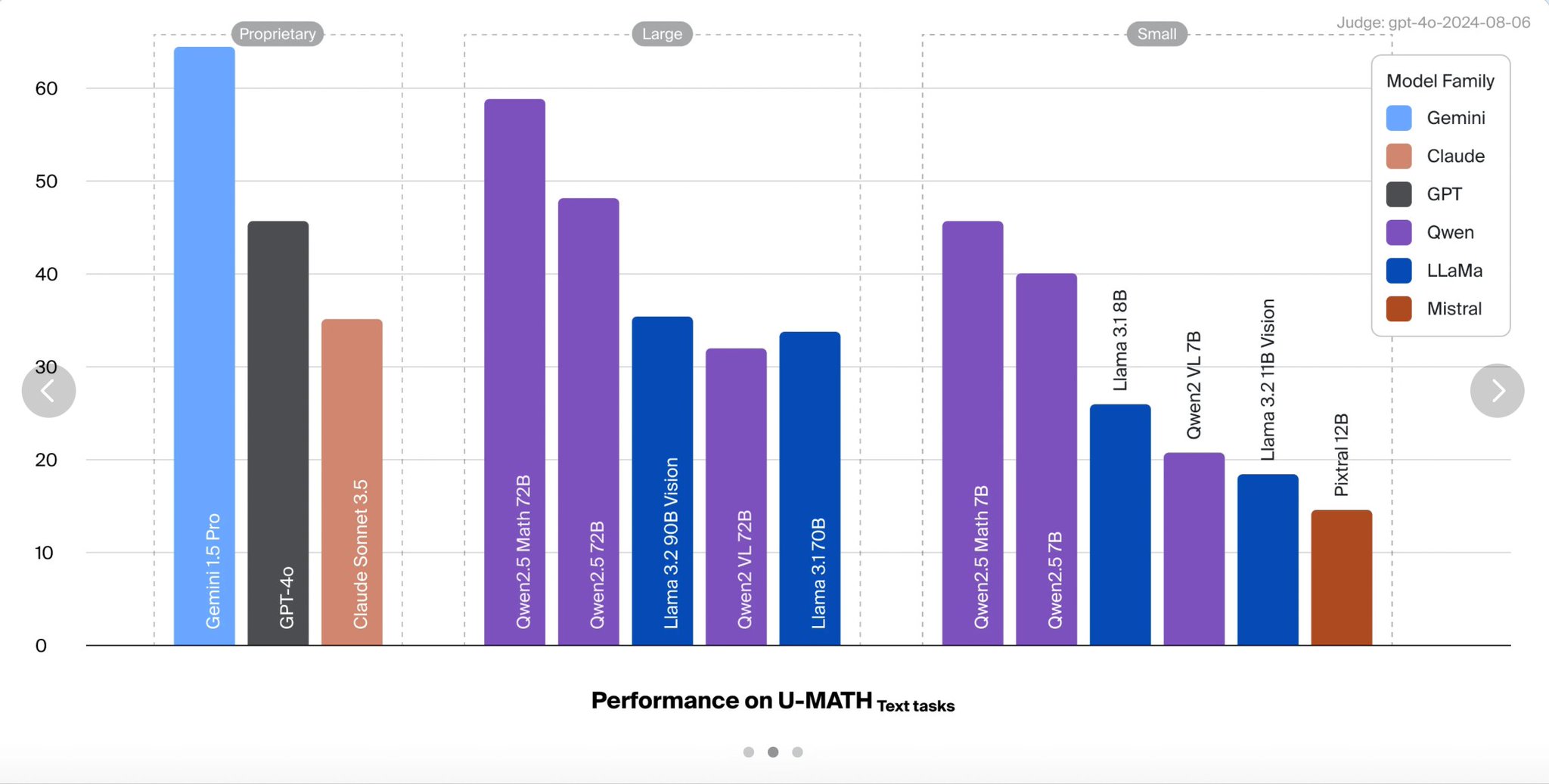
Qwen 2.5 72B Outperforms GPT-4o and Claude Sonnet
By
–
Wait WTF, that's Qwen 2.5 72B absolutely nailing GPT4o & Claude Sonnet!