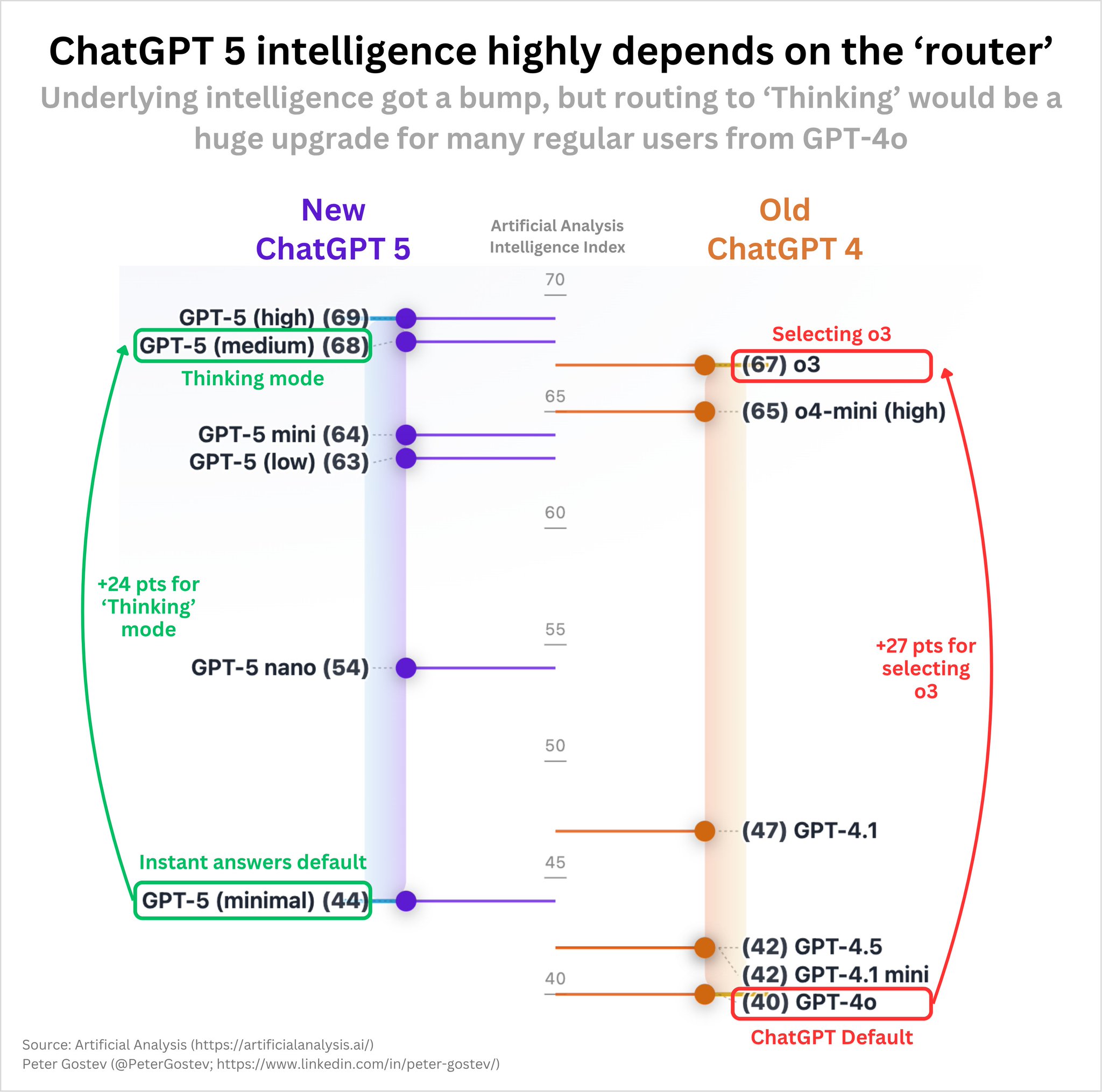
The level of intelligence for most people in @ChatGPTapp after GPT-5 update will depend highly on the 'router' and how often it would switch into 'thinking' mode. If you were using o3 already, you are unlikely to feel a huge difference. However, vast majority of ChatGPT users
@petergostev
-
User preferences for AI model picker and thinking features
By
–
I liked the model picker and I dislike the router idea. But appreciate it would be an upgrade on average for 98% of users. So as long as they leave the the 'thinking' button I'd be happy enough.
-
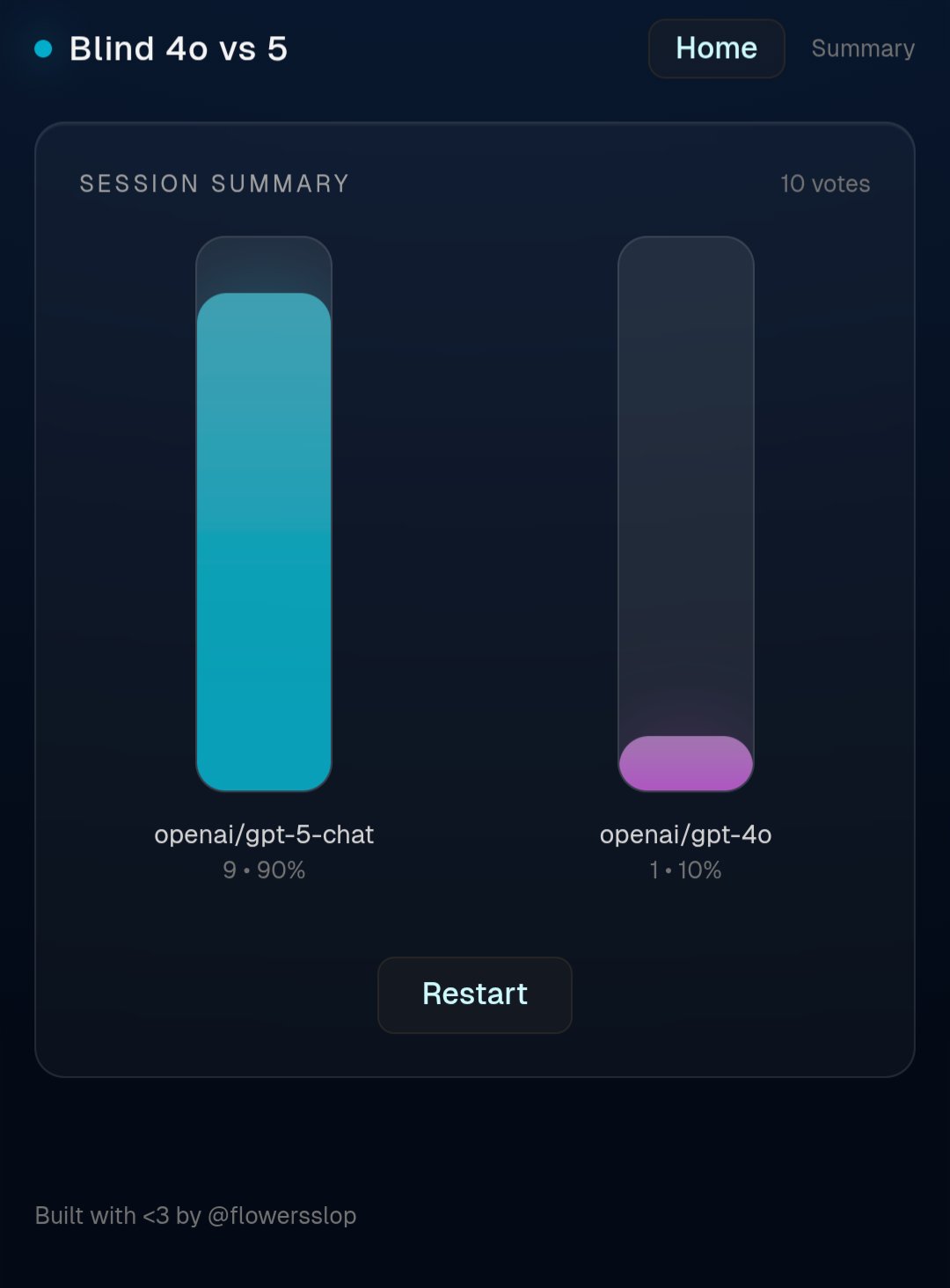
GPT-5 Dominates Blind Testing with Natural Thoughtful Responses
By
–
Used @flowersslop great blind testing tool – and GPT-5 is winning massively for me. The answers are a lot more natural and thoughtful. I like the questions btw, anyone can have a view on whether they like the response or not.
-
GPT-4o Stagnation Ends with o1 Release Acceleration
By
–
There definitely was a gear shift with RL. I remember we were stuck with 4o for like 10 months with tiny updates about a year ago, until o1.
-
OpenAI Praised for Impressive Development Speed
By
–
Kudos to OpenAI, this is impressively fast turnaround
-
o3 Alpha: Anonymous Chatbot Unbelievable Coding Model Capabilities
By
–
Roon what about Anonymous chatbot 0717 aka o3 alpha? It looked like an unbelievable coding model
-
Colin’s Account Compromised: Cybersecurity Incident Alert
By
–
Can't believe Colin's account got hacked
