Given that we saw OpenAI test better checkpoints on the arena, it does also seem like they have also optimised for cost / mass appeal rather than pushed the capabilities as far as they could. We also don't have almost any benchmarks for GPT-5-Pro, which is genuinely superb and
@petergostev
-
O3 API Speed Performance Getting Closer to Target
By
–
yeah you are right, I'm getting closer speeds in API too – not 221 for o3
-
AI-Generated Images Look Plastic and Artificial
By
–
I tried it too, images look very AI and plastic unfortunately, hope that's not Google
-

DeepSeek R2 Delayed Due to Huawei Chip Restrictions
By
–
DeepSeek R2 delayed because they are forced to use Huawei chips
-

Government Support: DeepSeek’s Potential Dominance or Downfall?
By
–
I remember people were saying that DeepSeek getting support from the government means that they will dominate. I was kind of fearing it might be the end of DeepSeek.
-

GPT-120B Achieves Superior Math Benchmark Scores at Fraction Cost
By
–
GPT-120B is getting exceptional scores on maths benchmarks, often well above models like o3, Gemini 2.5 Pro, DeepSeek R1, and most others. What’s also remarkable is that it achieves this at a cost of $1-2 per benchmark, often 10-20x cheaper than equivalent proprietary models
-
GPT-5-Pro Download Link Generation Issues and Code Display
By
–
I had several issues with GPT-5-Pro generating a downloadable link (e.g. HTML file) and that link wasn't working – just showing a download error (not the 'code interpreter sessions expired' one – this is separate). So I was asking it to show generated code as well, that worked,
-
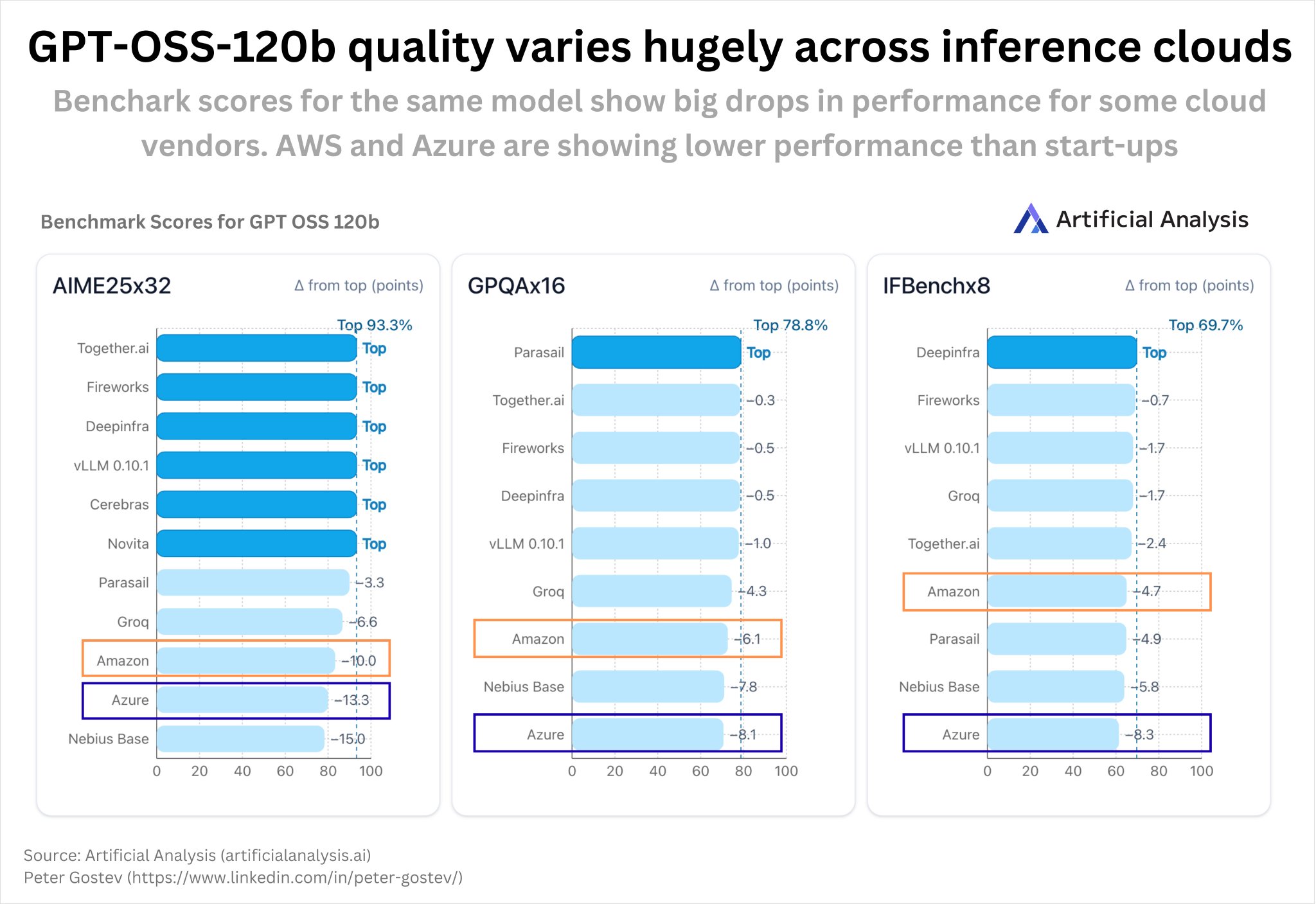
GPT 120B Performance Analysis: AWS and Azure Implementation Issues
By
–
Artificial analysis team did great work analysing the performance of the OpenAI's GPT OSS 120b model across providers – AWS and Azure are lagging behind. I really did not appreciate the extend to which the performance can drop if the model is not implemented correctly
-

ChatGPT Gains Gmail Access: Exploring AI-Powered Email
By
–
Now ChatGPT has access to my Gmail, I can ask the important questions: And apparently @simonw
's newsletter is the funniest email I ever got!
