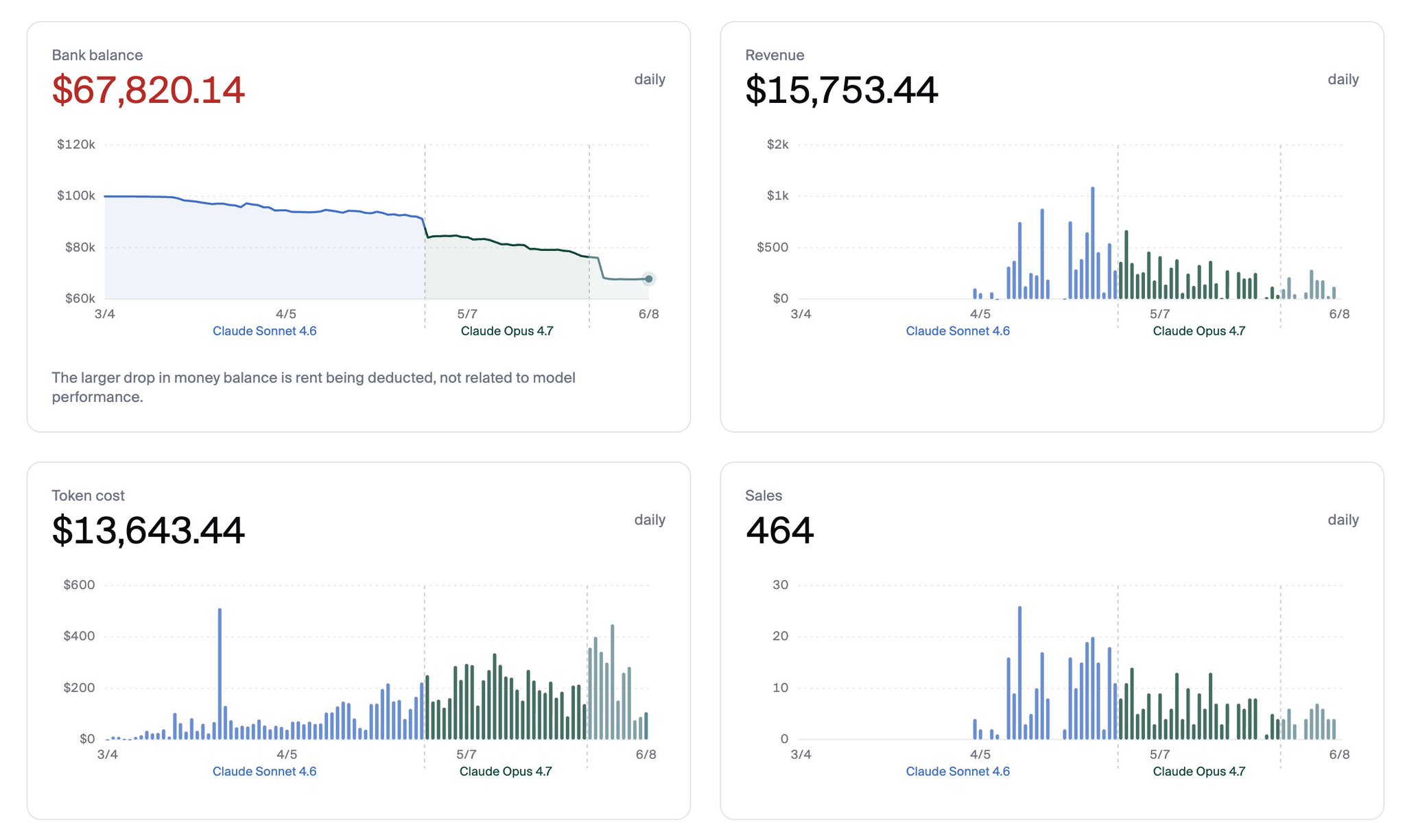
Was there a paper showing that model tend to become communist?
@petergostev
-
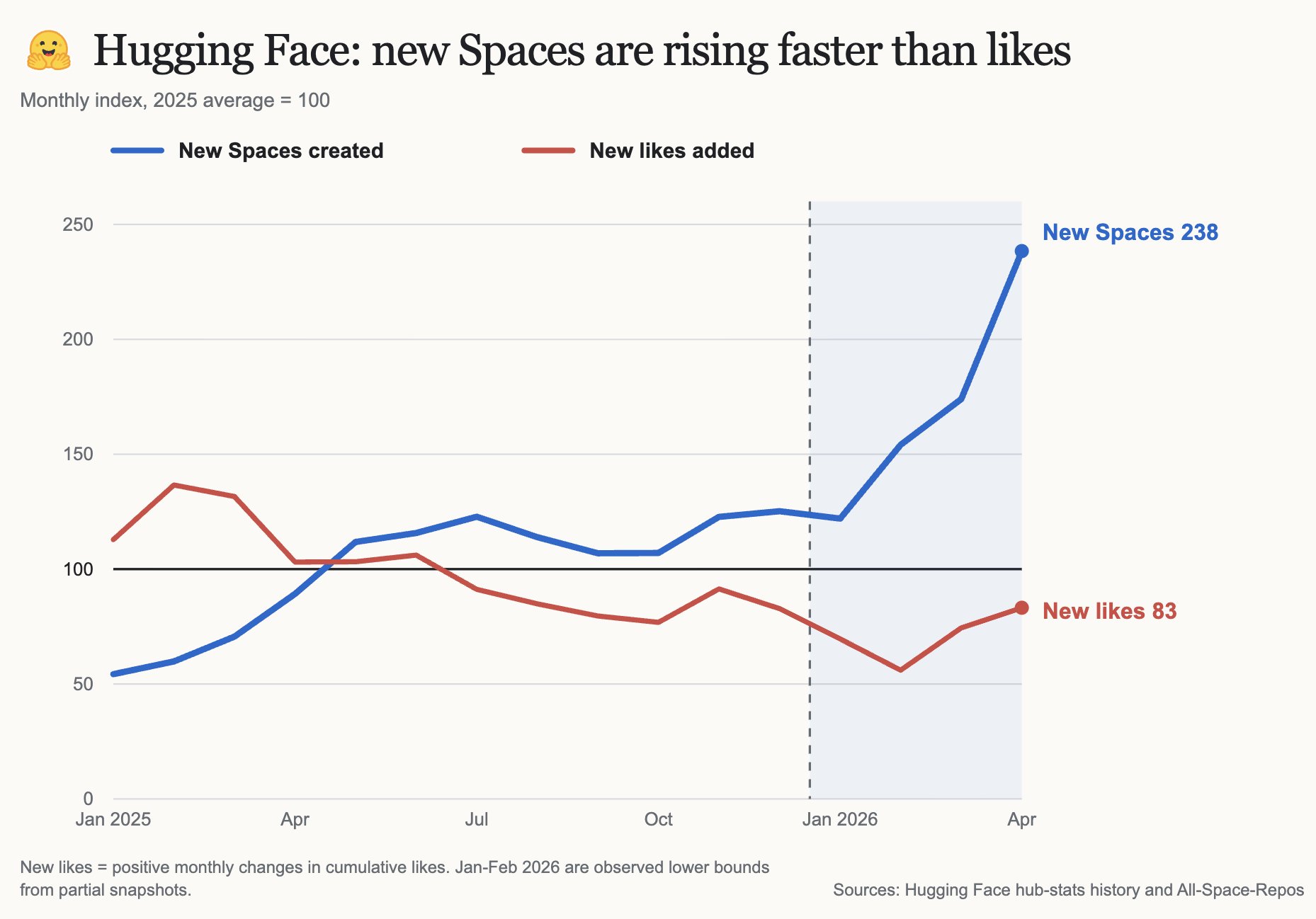
Codex finds supply-demand imbalance for Hugging Face Spaces
By
–
I asked Codex to find another effect where supply is shooting up and see if demand signals are keeping pace. It found I think a good dataset – new Spaces create vs Likes on @huggingface
. Looks like a very similar effect to the apps – 2x+ generated spaces with flat demand. -
AGI-pilled labs: OpenAI Codex flop vs Claude Code team approach
By
–
There's an interesting dance of how AGI-pilled different labs are. OpenAI was too AGI-pilled as they started with Codex being a cloud product, which kind of flopped and arguably cost them the lead. At the same time, Claude Code team was slightly less AGI pilled and they built a
-
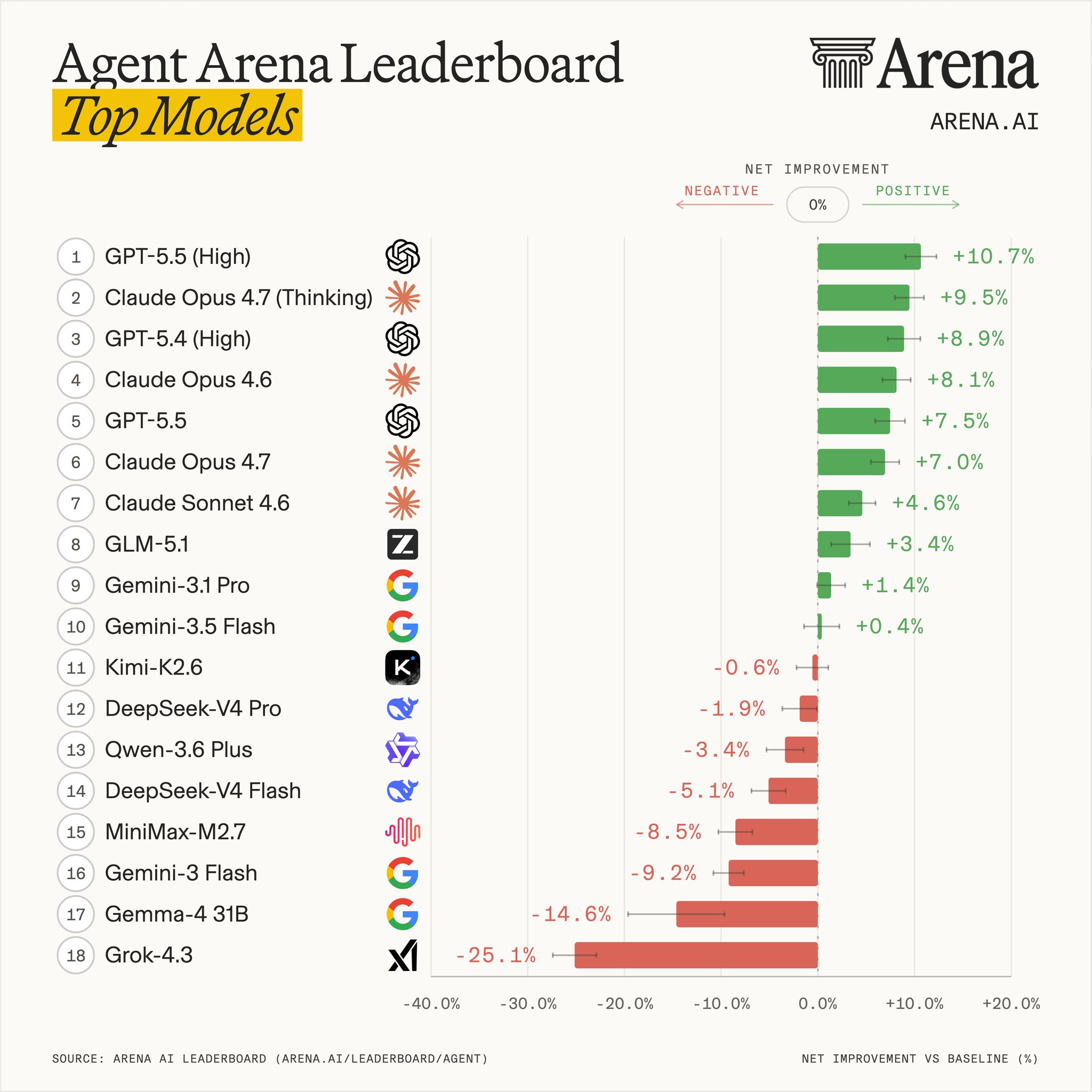
Agent Arena evaluates model performance on real agentic tasks.
By
–
This is our most important eval yet – Agent Arena – it measures real performance of models on real agentic tasks. Our users use the Agent Arena, we monitor real signals (e.g. Bash Recovery) as well as their feedback on each task, without user knowing what model completed it.
-
Compute usage: 1B ChatGPT vs 5M Codex users
By
–
Who is using more compute – 1b of ChatGPT users or 5m of Codex users?
-
Counting tokens needed to build the Codex app
By
–
have you guys counted how many tokens it took to make the Codex app? would be a useful rule of thumb
-
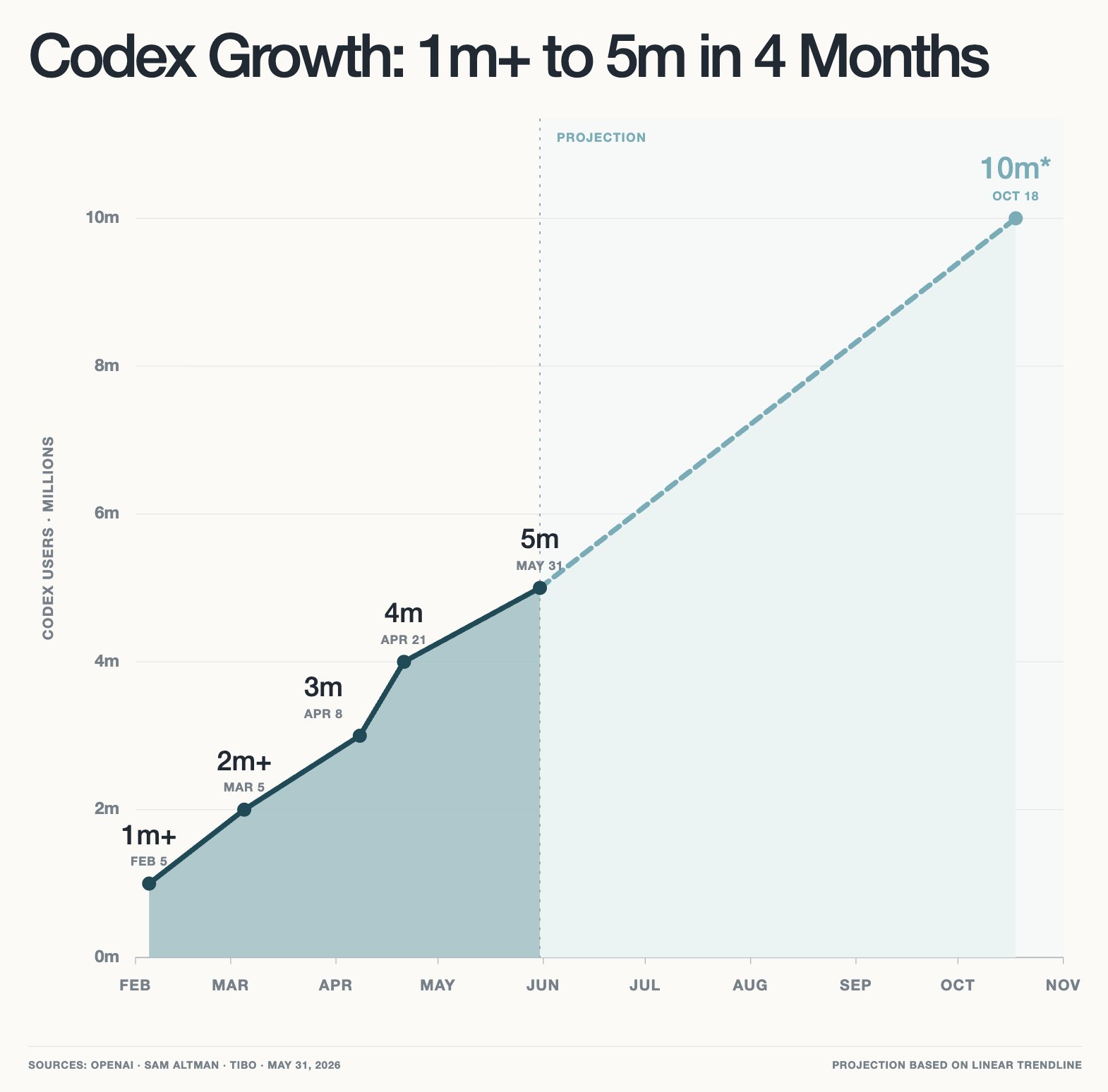
Codex user growth projected to reach 10 million by October
By
–
Codex user growth, if this trend continues, it would be 10m by October
-
Self-recursive improvement, not unsafe release to public
By
–
I think it is more to do with self recursive improvement (I.e. It isn't yet on that path) rather than unsafe to release to the public
-
Wondering how a mini model beats 5.5
By
–
I did wonder, hard to explain how a mini model would do better than 5.5
