.
@ArtificialAnlys just dropped a brand new leaderboard called AA-Briefcase for evaluating realistic tasks in complex projects. Nemotron 3 Ultra ranks among the top open models, with strong performance across a wide range of long-running agentic tasks, even when encountering them
@nvidiaai
-
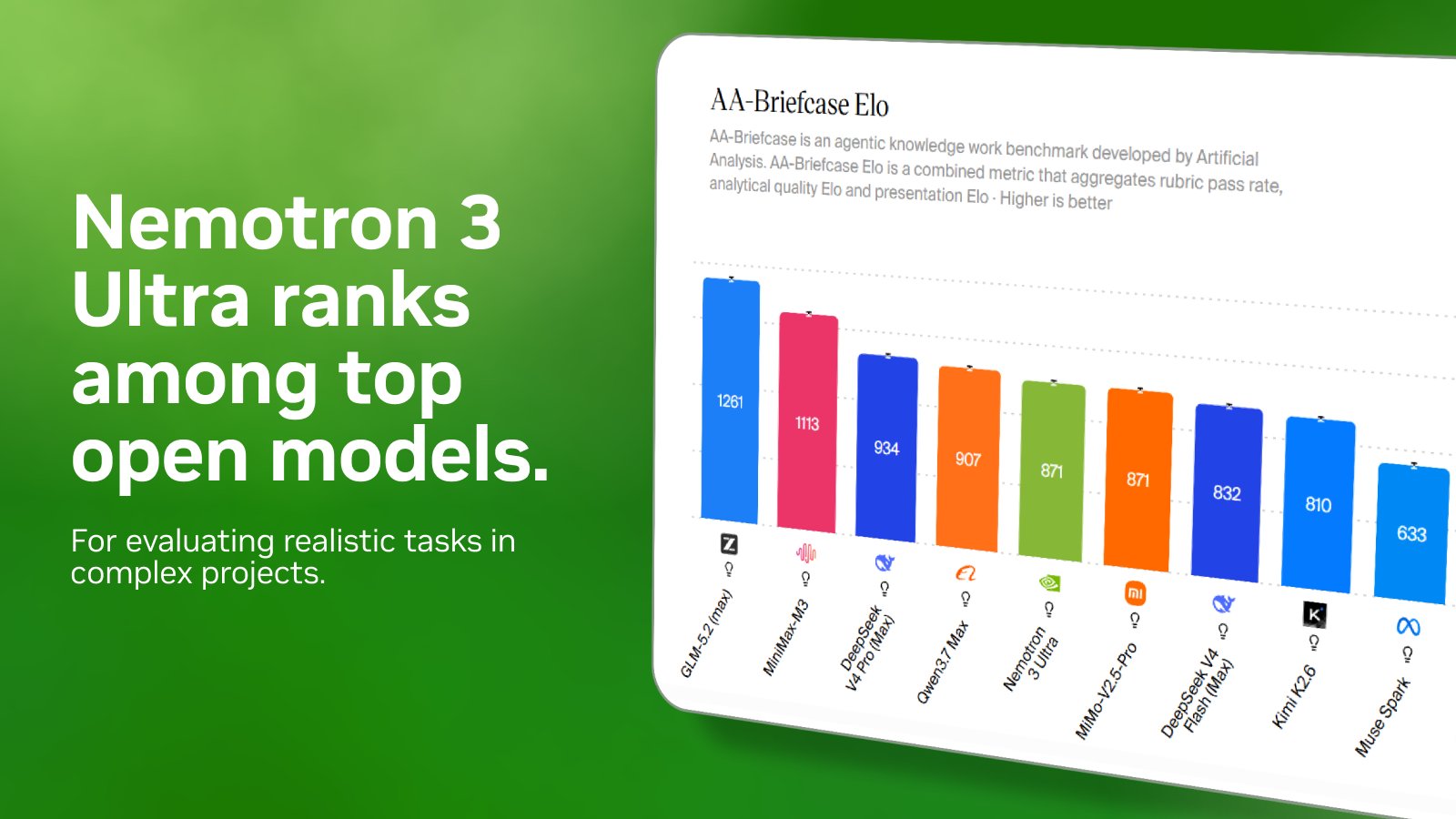
AA-Briefcase leaderboard for realistic tasks; Nemotron 3 Ultra top
By
–
-
NVIDIA Metropolis VSS 3: Video Search and Summarization with 16 New Skills
By
–
NVIDIA Metropolis Blueprint for video search and summarization (VSS) 3 is here.
— NVIDIA AI (@NVIDIAAI) 24 juin 2026
Now your coding agent can analyze massive live streams and libraries of videos with a simple natural language prompt. Here's what's new:
– 16 new agent skills: Search, summarize, alert, report,… pic.twitter.com/UojjUu8orkNVIDIA Metropolis Blueprint for video search and summarization (VSS) 3 is here. Now your coding agent can analyze massive live streams and libraries of videos with a simple natural language prompt. Here's what's new: – 16 new agent skills: Search, summarize, alert, report,
-
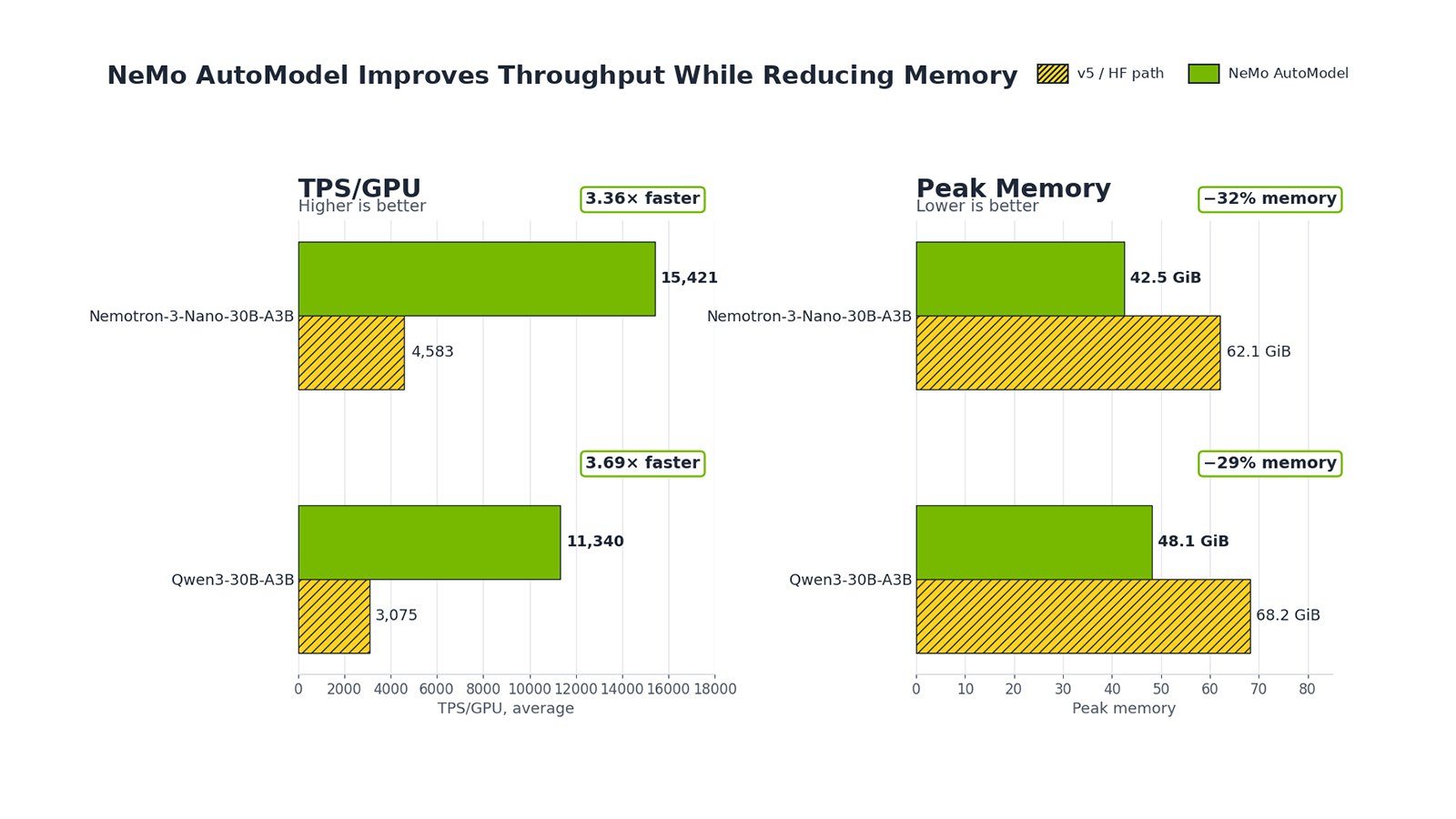
NeMo AutoModel Optimizes MoE Models with Transformers v5
By
–
The rise of MoE models introduced new challenges in training, and @huggingface's Transformers v5 brought first-class support for solving them. Now, NeMo AutoModel builds on top of v5. Part of the NeMo framework for building models at scale, NeMo AutoModel brings optimizations to
-
Nemotron Office Hours: The Nemotron 3 Model Family
By
–
Nemotron Office Hours: The Nemotron 3 Model Family | Nemotron Labs
-

DFlash boosts inference 15x on NVIDIA Blackwell with low latency
By
–
Increase inference performance by up to 15x without sacrificing responsiveness. DFlash, an open source lightweight block diffusion model designed for speculative decoding, delivers up to 15x higher throughput on NVIDIA Blackwell while maintaining the same user interactivity
-
NVIDIA Research ArtiFixer completes missing 3D scene geometry
By
–
3D scene reconstruction works great until the camera never sees part of the scene.
— NVIDIA AI (@NVIDIAAI) 22 juin 2026
ArtiFixer from NVIDIA Research is an open autoregressive model that fills in the missing geometry that other methods leave blank.#SIGGRAPH2026 paper, code + demo: https://t.co/D9PX2OzbZf pic.twitter.com/AGQicvVKkW3D scene reconstruction works great until the camera never sees part of the scene. ArtiFixer from NVIDIA Research is an open autoregressive model that fills in the missing geometry that other methods leave blank. #SIGGRAPH2026 paper, code + demo: https://
nvda.ws/4oILqNd -

SpatialClaw: training-free agent using code for visual tasks
By
–
Code is the right action interface for spatial reasoning agents. New from NVIDIA Research: SpatialClaw, a training-free agent that uses code as its action interface for complex visual tasks. Instead of calling a fixed set of pre-defined tools, the agent writes Python inside a
-
Nemotron 3 Ultra and the Open Model Landscape broadcast
By
–
Nemotron 3 Ultra and the Open Model Landscape | Nemotron Labs https://
x.com/i/broadcasts/1
rGmqqeRorDGy
… -

Nvidia AI congratulates MiniMax on M3 multimodal model release
By
–
Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. Try it today with our free GPU-accelerated endpoint on http://
build.nvidia.com. Details: https://
nvda.ws/4v4BWhD -
NvidiaAI showcases snug image and asks about Nemotron Omni
By
–
look at them all snug in there! And let us know what you think of Nemotron Omni.