They tried to integrate it into an OS. No one wanted it this way. Meta however has a much sleeker apporach due to their platforms
@kimmonismus
-
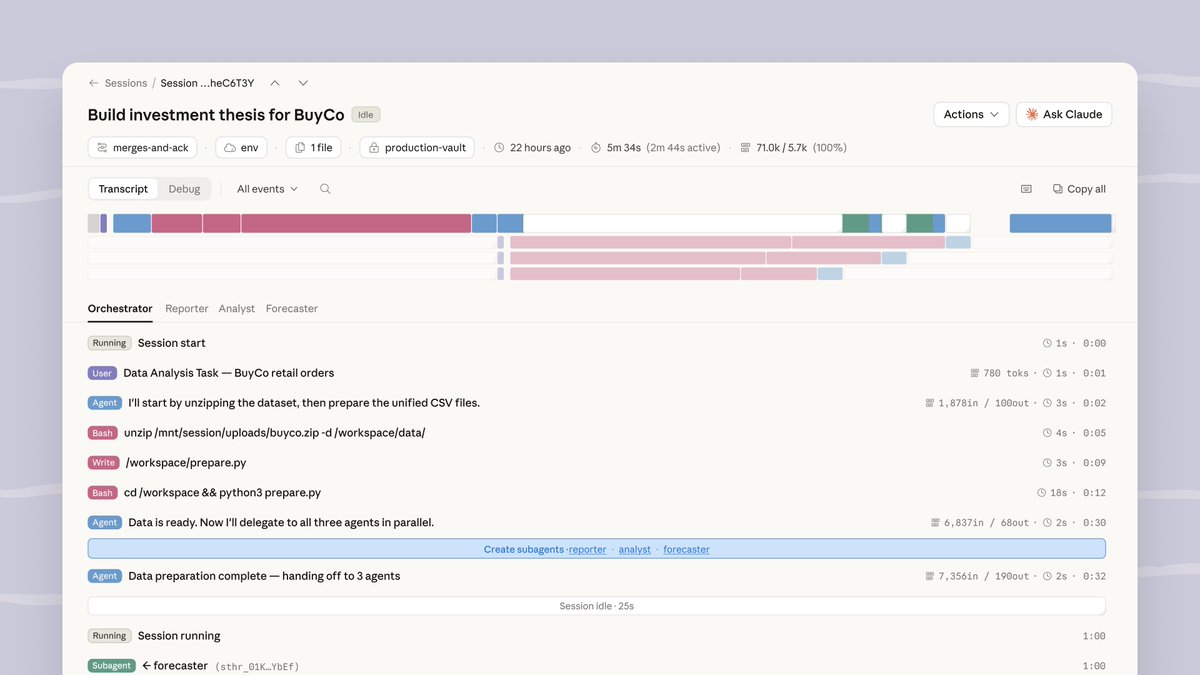
Claude Managed Agents: Anthropic’s Game-Changing AI Agent Platform
By
–
Anthropic‘s new Claude Managed Agents is the next shit from AI that simply responds to AI that can actually do the work. They are on the right path, updates being shipped daily, no end in sight. So far it feels like 2026 is Anthropics year. Claude (@claudeai) Introducing Claude Managed Agents: everything you need to build and deploy agents at scale. It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days. Now in public beta on the Claude Platform. — https://nitter.net/claudeai/status/2041927687460024721#m
→ View original post on X — @kimmonismus, 2026-04-08 18:15 UTC
-
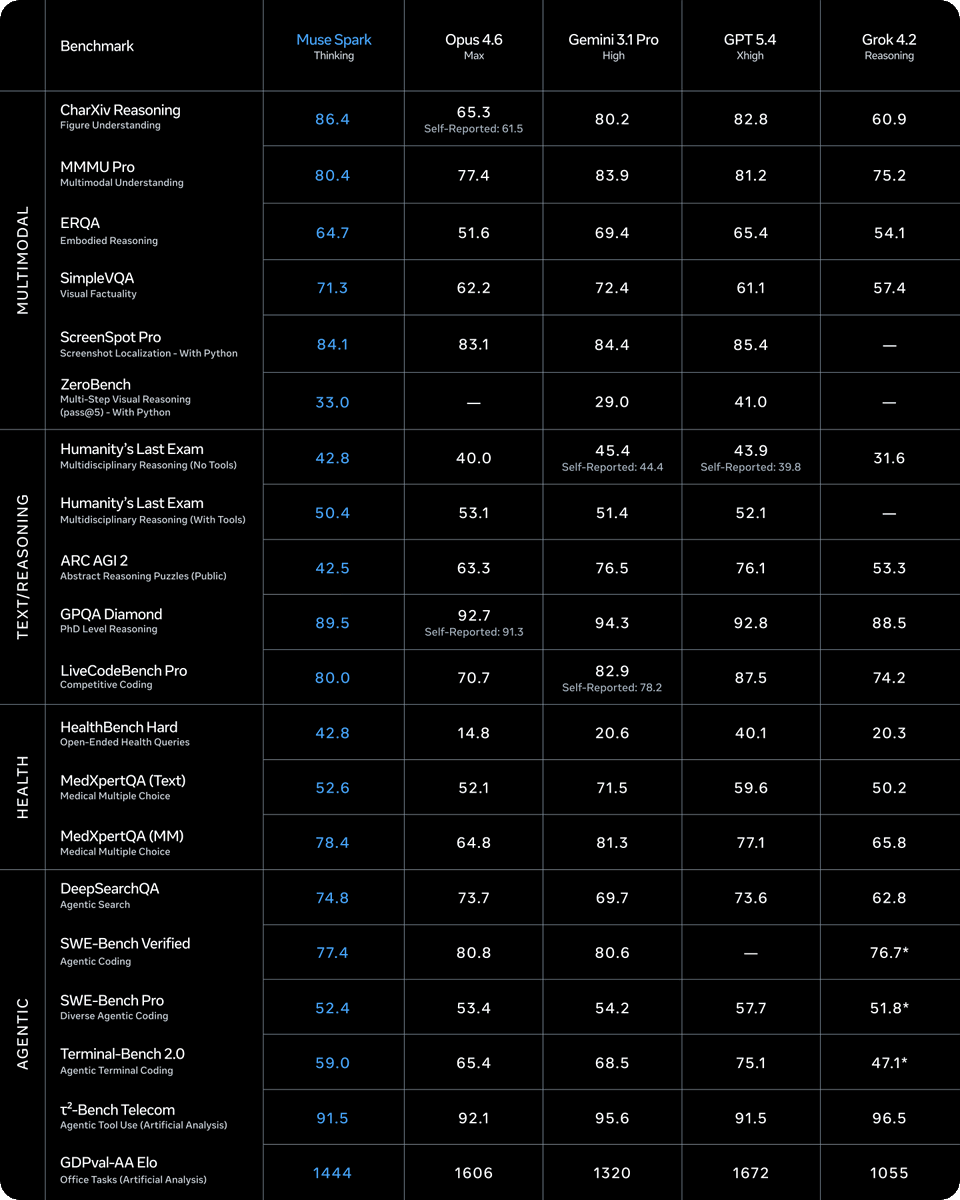
Meta’s Muse Spark: Multimodal AI Model with Impressive Reasoning Benchmarks
By
–

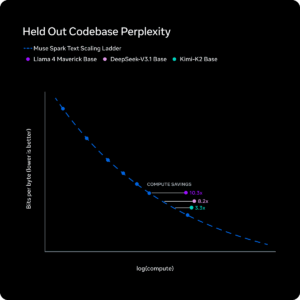

Meta Superintelligence Labsjust dropped Muse Spark, their first model after a full nine-month rebuild of their AI stack. the tl;dr (summary) It's a natively multimodal reasoning model that now powers Meta AI. It's competitive on reasoning and multimodal benchmarks, introduces a multi-agent "Contemplating mode," and Meta frames it as step one on a scaling ladder toward "personal superintelligence." Where it's strong: -Multimodal perception and visual reasoning (visual STEM, entity recognition, localization) -Health reasoning, built with input from 1,000+ physicians -Test-time reasoning efficiency, using thinking time penalties to compress reasoning tokens -Contemplating mode hits 58% on Humanity's Last Exam and 38% on FrontierScience Research, putting it in the ballpark of Gemini Deep Think and GPT Pro -Pretraining efficiency: reaches the same capability as Llama 4 Maverick with over 10x less compute Where it's weaker (Meta's own admission): -Long-horizon agentic systems -Coding workflows Key scaling findings: -RL compute scales smoothly with log-linear growth on pass@1 and pass@16 -Multi-agent orchestration scales performance without proportional latency increase -Phase transition behavior on AIME: the model first extends reasoning, then compresses it under length penalties, then extends again for higher accuracy My take: very good model, really surprised what meta offered here. And keep in mind: 99% of all instagram / facebook user dont need an LLM for doing academic reserach but for everyday reasoning. Well done, meta! Chubby♨️ (@kimmonismus) Lol what?! Meta has been cooking! These benchmarks are really freaking good holy!! — https://nitter.net/kimmonismus/status/2041918006779957407#m
→ View original post on X — @kimmonismus, 2026-04-08 16:42 UTC
-
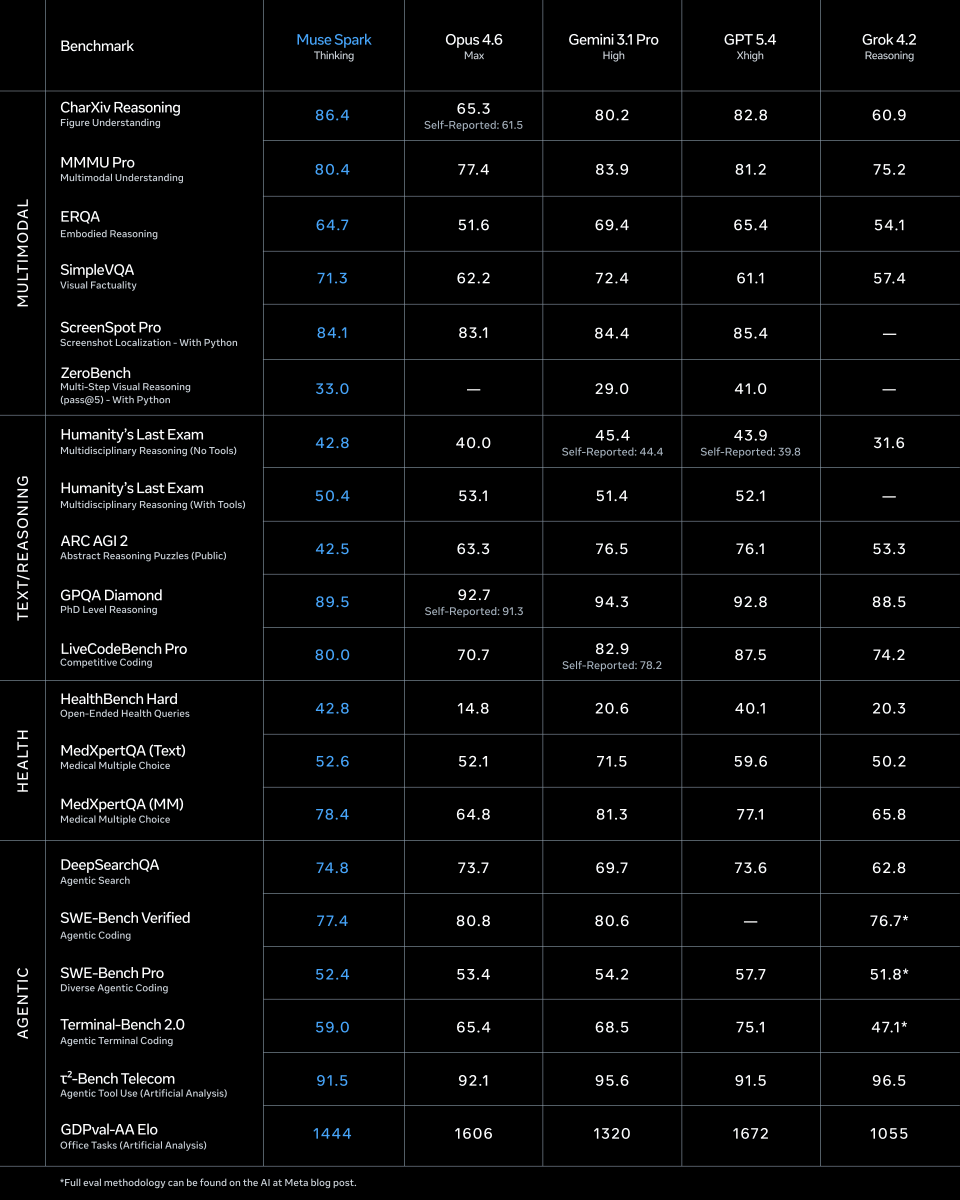
Meta’s New Muse Spark Model Delivers Impressive Benchmark Results
By
–

Lol what?! Meta has been cooking! These benchmarks are really freaking good holy!! Alexandr Wang (@alexandr_wang) 1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵 — https://nitter.net/alexandr_wang/status/2041909376508985381#m
→ View original post on X — @kimmonismus, 2026-04-08 16:36 UTC
-
Meta.ai platform now available for checkout
By
–
Meta.ai is where you can check it out
→ View original post on X — @kimmonismus, 2026-04-08 15:53 UTC
-
Meta Launches Avocado Model with Positive Initial Testing Results
By
–
Meta is rolling out its new model "Avocado". Intial testing: very positive! Go check it out
→ View original post on X — @kimmonismus, 2026-04-08 15:35 UTC
-
Grok 4.20 at 0.5T Parameters, 1T and 1.5T Models Coming Soon
By
–
Grok 4.20 is about 0.5T parameters – about 2-3 weeks for a new 1T – 4 to 5 weeks for the 1.5T model Competition is heating up – again. Elon Musk (@elonmusk) About 2 to 3 weeks for 1T and 4 to 5 weeks for 1.5T — https://nitter.net/elonmusk/status/2041894999823151124#m
→ View original post on X — @kimmonismus, 2026-04-08 15:12 UTC
-
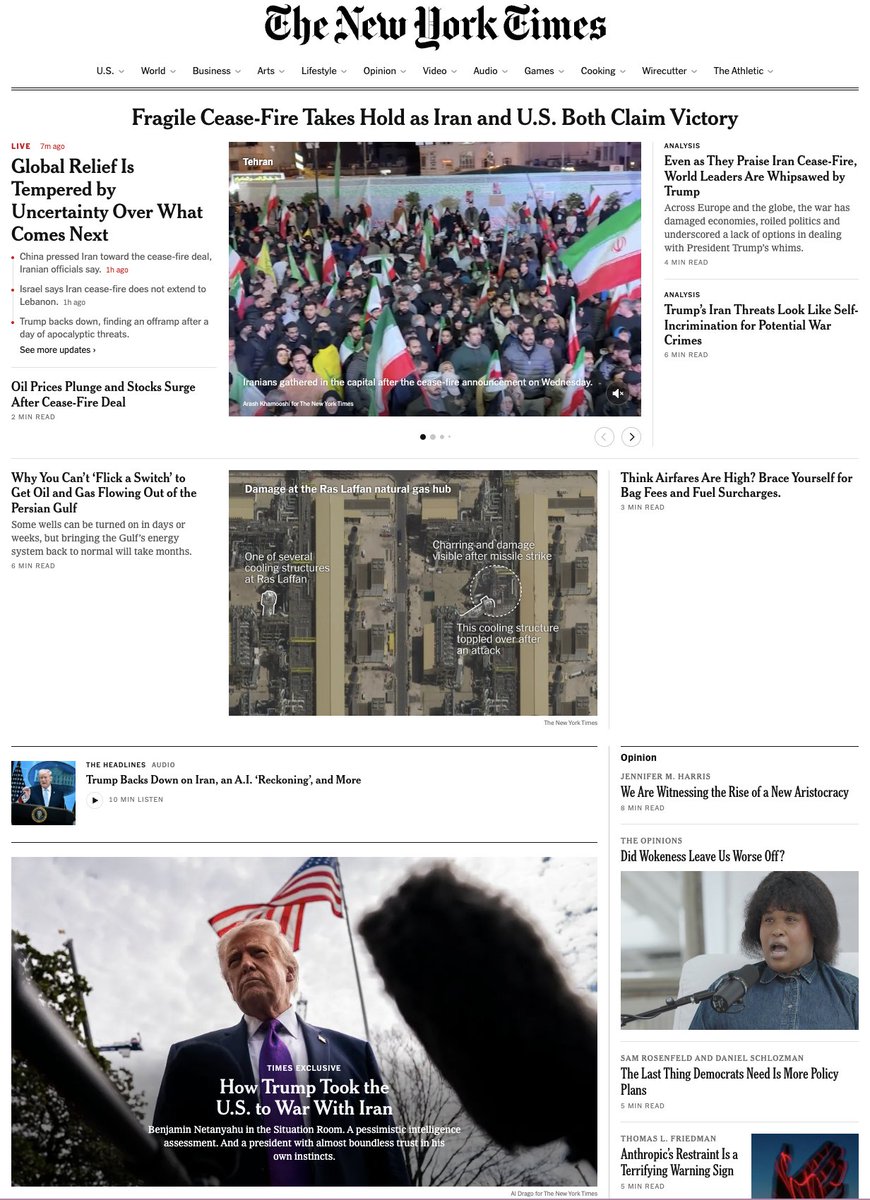
Major News Sites Undercover Claude Mythos Release Coverage
By
–

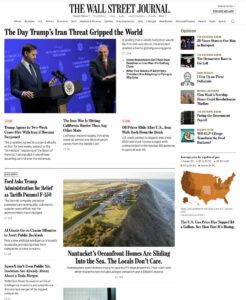
Think about it. None of the major newspapers have given Claude Mythos a prominent mention/Top Placement on their websites. We live in an AI ivory tower; 99% of people don't know what was published yesterday. They don't know what's coming. That's why our work is so important. Shakeel (@ShakeelHashim) The Anthropic Mythos release does not appear near the top of the homepage on any major news site today. The NYT is closest, but it's still pretty far down. The Guardian thinks a Vogue cover with Anna Wintour and Meryl Streep is more important. The Washington Post is prioritizing yet another "we tried to get into Berghain" story. The media is not adequately covering the insane moment we are in. — https://nitter.net/ShakeelHashim/status/2041829164894871584#m
→ View original post on X — @kimmonismus, 2026-04-08 14:04 UTC
-
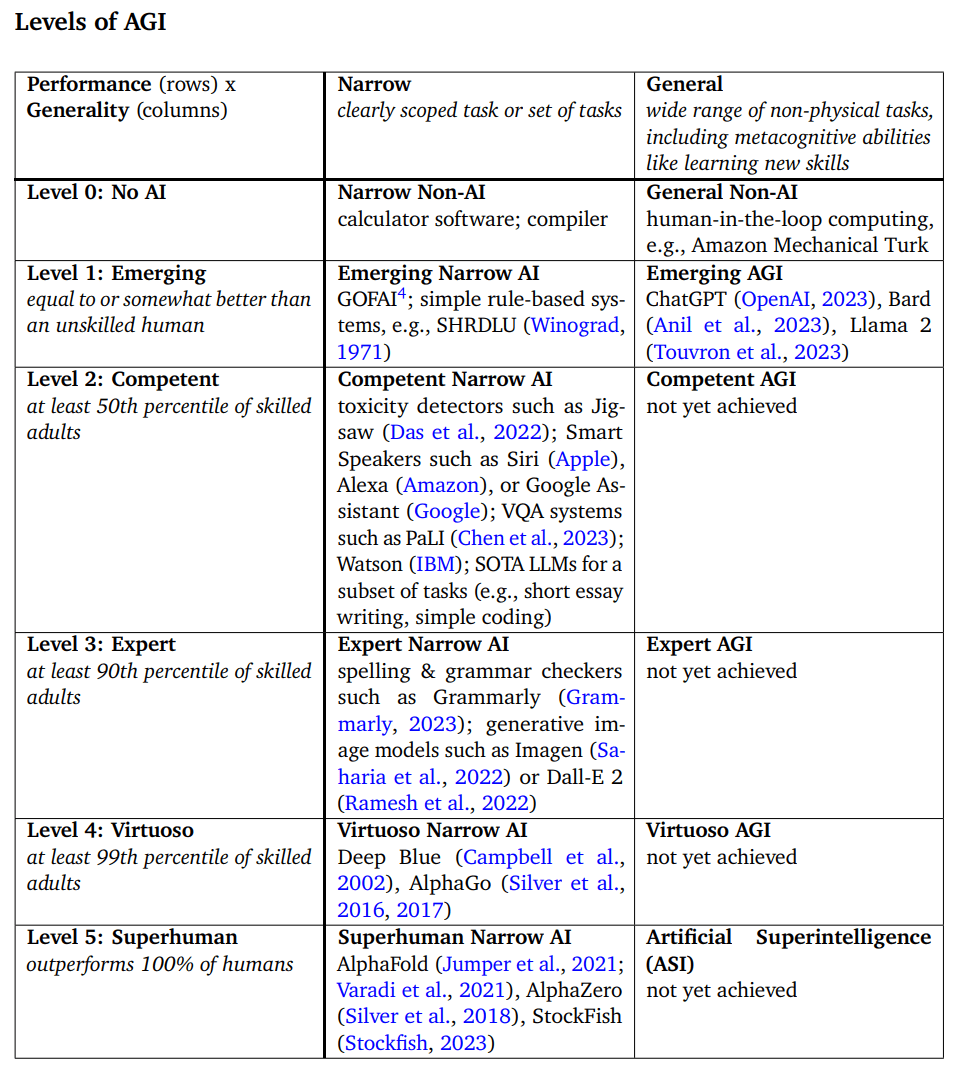
Google DeepMind’s Definition Approach to Intelligence
By
–
Remember, google deepmind tried to approach with their definition:
→ View original post on X — @kimmonismus, 2026-04-08 12:15 UTC
-
Google DeepMind’s Most Promising Approach
By
–
Google deepmind hast the most promising approach imho