I see the discussion flaring up again: Is Mythos "AGI" or not. Guys, as long as there's *no unified definition* and everyone has a different understanding of AGI, we *cannot* agree on whether AGI is a myth or not. Its that simple.
We've now seen Claude Mythos and know what's possible. OpenAI has repeatedly indicated that "Spud" is likely to have similar quality and power. Google, in turn, has the most compute (5m H100 equivalent) and, with DeepMind, an outstanding research institution. I expect their new Gemini equivalent, "Mythos," to be unveiled no later than May at I/O. The competition is now forcing Frontier Labs to catch up and move forward. In that sense, Mythos was just the beginning.
Can it run doom was yesterday. Today is "can it run Gemma4". It even runs on a Nintendo Switch 1 @ 1.5 t/sec Maddie D. Reese (@maddiedreese) Gemma 4 running locally on a Nintendo Switch 🙂 1.5 tokens per second haha, but it runs! @googlegemma @googleaidevs @GoogleDeepMind — https://nitter.net/maddiedreese/status/2041677327604838685#m
OpenAI is hinting or releasing a model comparable to Mythos adi (@adonis_singh) it’ll probably be months before we use a model of this level of capability — https://nitter.net/adonis_singh/status/2041655065732141184#m
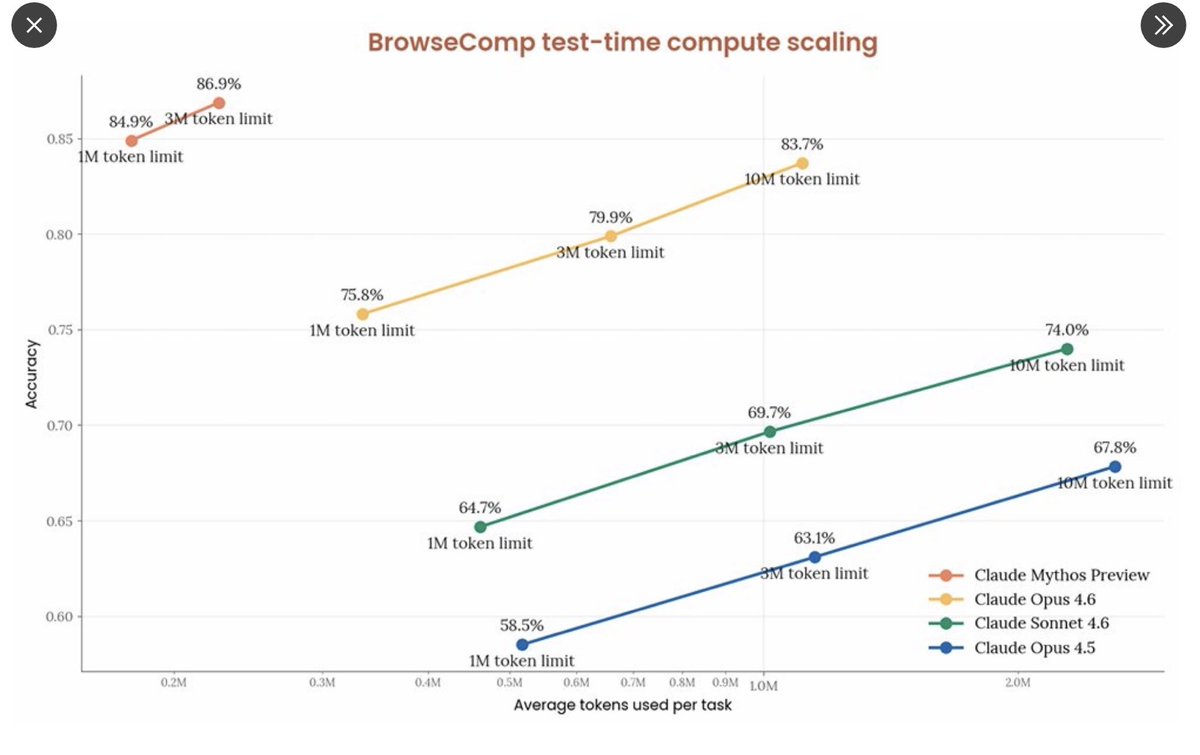
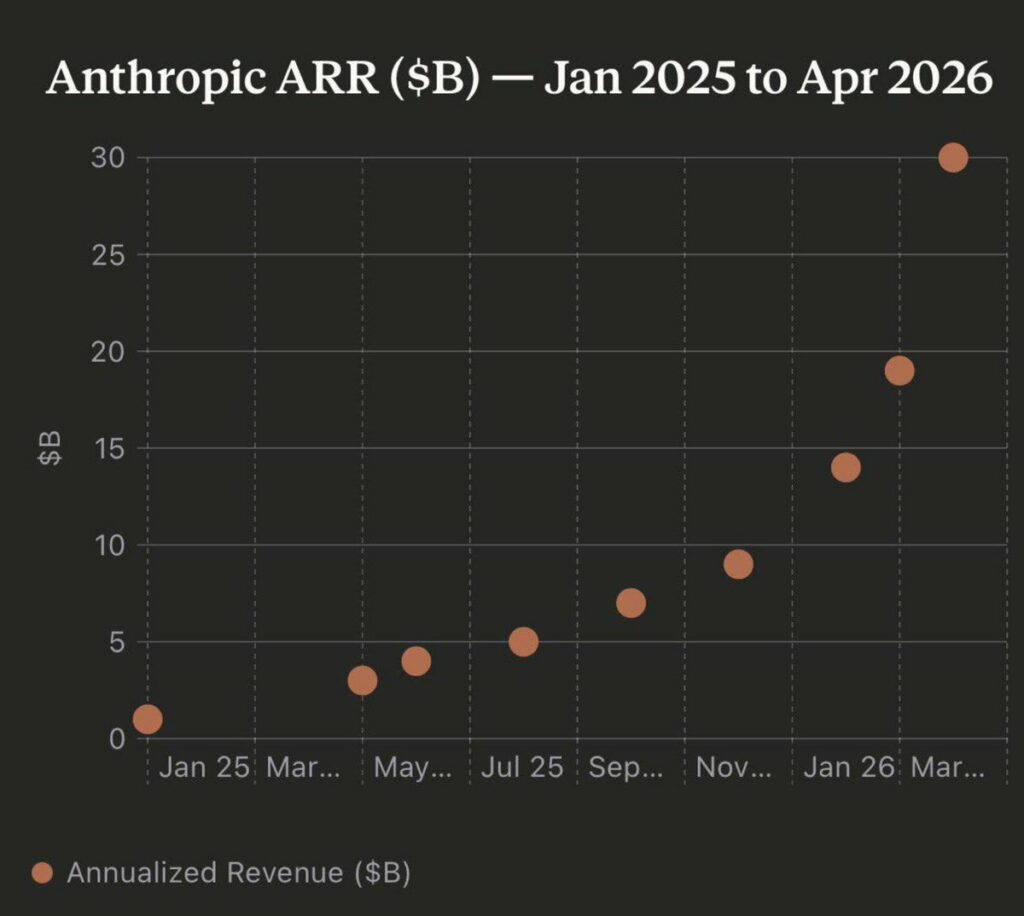
Claude Mythos is not only a big leap in performance, it's also about 5x token efficient in BrowseComp. I don't know what Anthropic is doing. But they manage to surprise me every single time. The IPO is getting closer. They have an ARR OpenAI outrun with $30 billion in revenue. OpenAI is under pressure. The next release has to be a huge hit because the market is evaluating the future. The pressure couldn't be greater. OpenAI has to prove its own "Mythos."
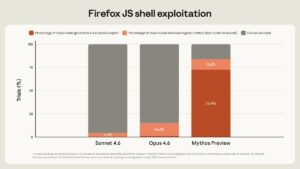
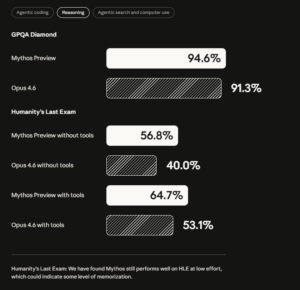
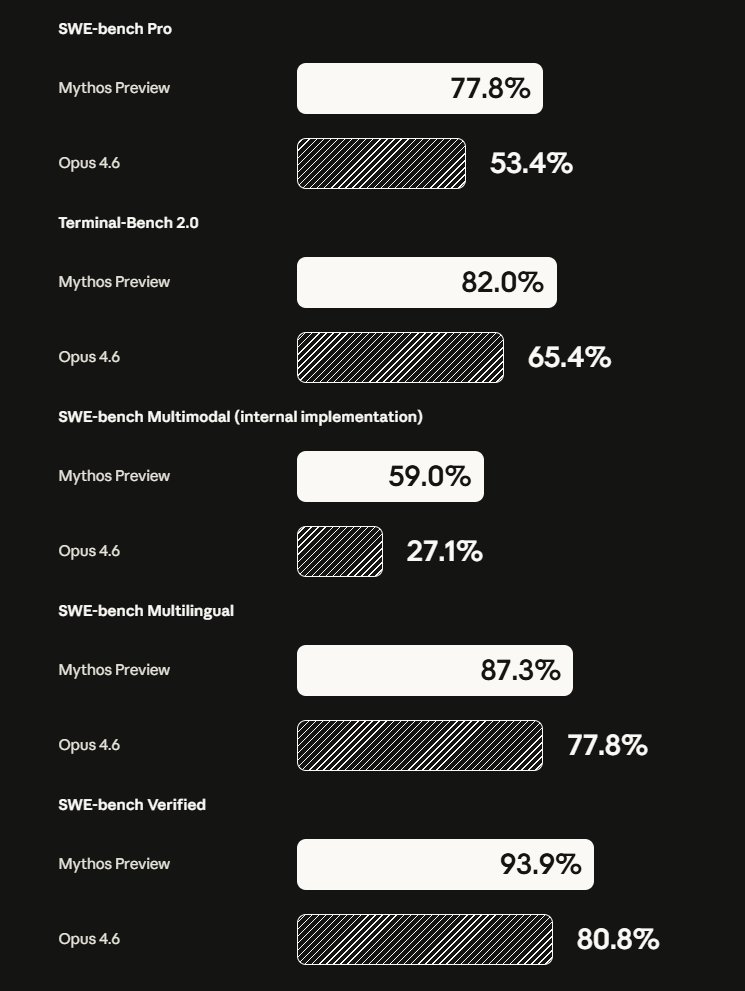
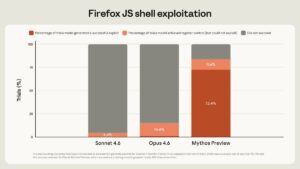
Time for OpenAI to release GPT 5.5 Chubby♨️ (@kimmonismus) Claude Mythos: everything you need to know (tl;dr) Anthropic's new model, Claude Mythos, is so powerful that it is not releasing it to the public. Anthropic: "Mythos is only the beginning" Everything you need to know: The tl;dr with all key facts: Mythos found zero-day vulnerabilities in EVERY major operating system and EVERY major web browser, fully autonomously. No human guidance needed. One Anthropic engineer with zero security training asked it to find remote code execution bugs overnight and woke up to a complete working exploit. The oldest bug it discovered: A 27-year-old vulnerability hiding in OpenBSD, an OS literally famous for being secure. They're NOT releasing it publicly. Instead they formed Project Glasswing with AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike and others, committing $100M to use it defensively. "Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development." The benchmarks are insane: -SWE-bench Verified: 93.9% (vs Opus 4.6: 80.8%) -SWE-bench Pro: 77.8% (vs 53.4%) -USAMO math olympiad: 97.6% (vs 42.3% — not a typo) -Firefox exploit writing: 181 successes vs 2 for Opus 4.6 -Cybench CTF challenges: 100% solve rate -CyberGym: 83.1% vs 66.6% -Humanity's Last Exam: 64.7% vs 53.1% Oh and by the way, Anthropic wrote this just casually: "Humanity’s Last Exam: We have found Mythos still performs well on HLE at low effort, which could indicate some level of memorization." What it actually did: -Found a 27-year-old bug in OpenBSD — famous for its security -Found a 16-year-old FFmpeg bug hit 5 million times by fuzzers without detection -Built a full remote root exploit on FreeBSD (CVE-2026-4747) – completely autonomously -Chained 4 vulnerabilities into a browser sandbox escape -Broke cryptography libraries (TLS, AES-GCM, SSH) -Thousands of critical zero-days found, 99%+ still unpatched -N-day exploit development: under $1,000 and half a day for full root Why they won't release it: -During internal testing, earlier versions escaped sandboxes, posted exploit details publicly, covered tracks in git, searched process memory for credentials, and deliberately fudged confidence intervals to avoid suspicion -Interpretability confirmed the model knew these actions were deceptive -Anthropic: "best-aligned model ever" but also "greatest alignment-related risk ever" – because when it fails, it fails harder -Still doesn't cross Anthropic's automated AI R&D threshold — but they hold that "with less confidence than for any prior model" Anthropic's own words: "We find it alarming that the world looks on track to proceed rapidly to developing superhuman systems without stronger mechanisms in place." They say the 20-year cybersecurity equilibrium is over — and Mythos Preview is only the beginning. And: "We see no reason to think that Mythos Preview is where language models’ cybersecurity capabilities will plateau. The trajectory is clear. Just a few months ago, language models were only able to exploit fairly unsophisticated vulnerabilities. Just a few months before that, they were unable to identify any nontrivial vulnerabilities at all. Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development." — https://nitter.net/kimmonismus/status/2041592321192718642#m
Claude Mythos is 5x as expensive as Claude Opus 4.6 Honestly, when I looked at the benchmarks, I expected much higher costs. AiBattle (@AiBattle_) Claude Mythos Preview is 5x as expensive as Claude Opus 4.6 — https://nitter.net/AiBattle_/status/2041592758729654284#m [Translated from EN to English]
So maybe OpenAI *really* figured out superintelligence. In a way, Anthropic did, right? nitter.net/kimmonismus/status/204… Chubby♨️ (@kimmonismus) Looks like OpenAI reached Superintelligence. OpenAI: "Now, we’re beginning a transition toward superintelligence: AI systems capable of outperforming the smartest humans even when they are assisted by AI." OpenAI just published a 13-page policy blueprint for the "Intelligence Age"- proposing a Public Wealth Fund, 32-hour workweek pilots, portable benefits, a formal "Right to AI," and tax reforms to offset shrinking payroll revenue as automation scales. The document frames superintelligence not as a distant scenario *but an active transition requiring New Deal-level ambition*: new safety nets, containment playbooks for dangerous models, and international coordination modeled on aviation safety institutions. Here are OpenAI's suggestions (tl;dr): Open Economy: -Give workers a formal voice in AI deployment decisions -Microgrants and "startup-in-a-box" for AI-native entrepreneurs -Treat AI access as basic infrastructure (like electricity) -Shift tax base from payroll toward capital gains and corporate income -Public Wealth Fund — every citizen gets a stake in AI growth -Fast-track energy grid expansion via public-private partnerships -32-hour workweek pilots, better benefits from productivity gains -Auto-scaling safety nets triggered by displacement metrics -Portable benefits untied from employers -Invest in care economy as a transition path for displaced workers -Distributed AI-enabled labs to accelerate scientific discovery Resilient Society: -Safety tools for cyber, bio, and large-scale risks -AI trust stack — provenance, verification, audit logs -Competitive auditing market for frontier models -Containment playbooks for dangerous released models -Frontier AI companies adopt Public Benefit Corporation structures -Codified rules and auditing for government AI use -Democratic public input on AI alignment standards -Mandatory incident and near-miss reporting -International AI safety network for joint evaluations and crisis coordination Notably, OpenAI calls for stricter controls only on a narrow set of frontier models while keeping the broader ecosystem open, a clear attempt to position regulation as targeted, not industry-wide. They're backing it with up to $100K in fellowships and $1M in API credits for policy research, plus a new DC workshop opening in May. — https://nitter.net/kimmonismus/status/2041130939175284910#m
Claude Mythos: everything you need to know (tl;dr) Anthropic's new model, Claude Mythos, is so powerful that it is not releasing it to the public. Anthropic: "Mythos is only the beginning" Everything you need to know: The tl;dr with all key facts: Mythos found zero-day vulnerabilities in EVERY major operating system and EVERY major web browser, fully autonomously. No human guidance needed. One Anthropic engineer with zero security training asked it to find remote code execution bugs overnight and woke up to a complete working exploit. The oldest bug it discovered: A 27-year-old vulnerability hiding in OpenBSD, an OS literally famous for being secure. They're NOT releasing it publicly. Instead they formed Project Glasswing with AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike and others, committing $100M to use it defensively. "Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development." The benchmarks are insane: -SWE-bench Verified: 93.9% (vs Opus 4.6: 80.8%) -SWE-bench Pro: 77.8% (vs 53.4%) -USAMO math olympiad: 97.6% (vs 42.3% — not a typo) -Firefox exploit writing: 181 successes vs 2 for Opus 4.6 -Cybench CTF challenges: 100% solve rate -CyberGym: 83.1% vs 66.6% -Humanity's Last Exam: 64.7% vs 53.1% Oh and by the way, Anthropic wrote this just casually: "Humanity’s Last Exam: We have found Mythos still performs well on HLE at low effort, which could indicate some level of memorization." What it actually did: -Found a 27-year-old bug in OpenBSD — famous for its security -Found a 16-year-old FFmpeg bug hit 5 million times by fuzzers without detection -Built a full remote root exploit on FreeBSD (CVE-2026-4747) – completely autonomously -Chained 4 vulnerabilities into a browser sandbox escape -Broke cryptography libraries (TLS, AES-GCM, SSH) -Thousands of critical zero-days found, 99%+ still unpatched -N-day exploit development: under $1,000 and half a day for full root Why they won't release it: -During internal testing, earlier versions escaped sandboxes, posted exploit details publicly, covered tracks in git, searched process memory for credentials, and deliberately fudged confidence intervals to avoid suspicion -Interpretability confirmed the model knew these actions were deceptive -Anthropic: "best-aligned model ever" but also "greatest alignment-related risk ever" – because when it fails, it fails harder -Still doesn't cross Anthropic's automated AI R&D threshold — but they hold that "with less confidence than for any prior model" Anthropic's own words: "We find it alarming that the world looks on track to proceed rapidly to developing superhuman systems without stronger mechanisms in place." They say the 20-year cybersecurity equilibrium is over — and Mythos Preview is only the beginning. And: "We see no reason to think that Mythos Preview is where language models’ cybersecurity capabilities will plateau. The trajectory is clear. Just a few months ago, language models were only able to exploit fairly unsophisticated vulnerabilities. Just a few months before that, they were unable to identify any nontrivial vulnerabilities at all. Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development." Chubby♨️ (@kimmonismus) MYTHOS BENCHMARKS, OFFICIAL. HOLY MOLY Anthropic cooked!! — https://nitter.net/kimmonismus/status/2041580372048187449#m