
Tree Prompting! A way to do text classification and get state-of-the-art results without doing backprop or fine tuning any language models Come to poster 26b to learn more, and watch my coauthors cook
@jxmnop
-
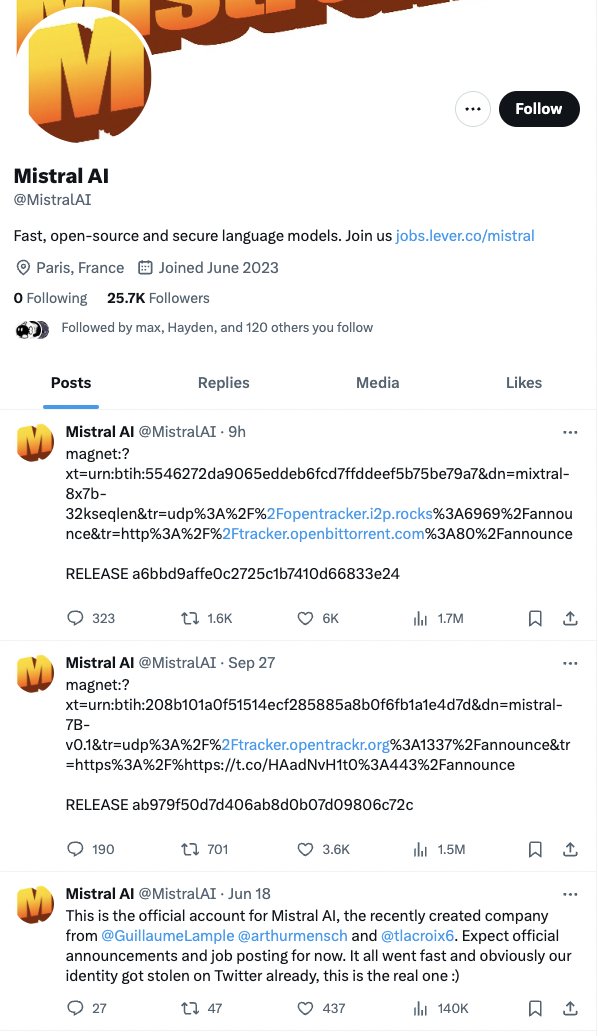
Mistral’s Bold Strategy: Sharing AI Models Without Context
By
–
say what you will about mistral, tweeting exclusively download links to new models with no context is unbelievably cool
-
Google AI metrics questioned for real-world usage representation
By
–
very fair question, i'm just pointing out that the metrics they keep showing in the google promo material are very weird and not representative of how people actually use models
-
iPrompt and Tree Prompting: Advanced Techniques for AI Model Enhancement
By
–
yes! 🙂 iPrompt: http://
arxiv.org/abs/2210.01848
Tree Prompting: http://
arxiv.org/abs/2310.14034 (thanks for asking) -

Gemini Underperforms GPT-4 on Zero-Shot Task Accuracy
By
–
this makes me think Gemini is still worse than GPT-4 for most people, I think the real measure of "intelligence" is zero-shot accuracy on various tasks so if Gemini underperforms GPT-4 with fewer examples in context, is it really a better model?
-
iPrompt and Tree Prompting Techniques Presented at Blackbox NLP
By
–
iPrompt and Tree Prompting were joint work with the prolific @csinva
. come see us today at the blackbox NLP workshop!! -

Research on Language Model Interpretability and Prompt Engineering at EMNLP2023
By
–
i am in singapore, presenting some cool research at #EMNLP2023!! • iPrompt: Explaining Patterns in Data with Language Models via Interpretable Autoprompting
• Text Embeddings Reveal (Almost) As Much as Text
• Tree Prompting: Efficient Task Adaptation without Fine-Tuning -
Follow Top NLP Researchers: INSTRUCTOR Embedding Model Creators
By
–
here are two awesome researchers you should follow: @WeijiaShi2 at UW and @wzhao_nlp at Cornell!! some of their recent work: weijia shi (
@WeijiaShi2
): – built INSTRUCTOR, the embedding model that lots of startups / companies use (
http://
arxiv.org/abs/2212.09741)
– proposed a more -
SSM Papers on Image Generation Research
By
–
this is cool, I think @NathanYan2012 has written some papers on generating images using SSMs