also training a massive text embedding model (many tokens AND many parameters) !
@jxmnop
-
Improving vec2text Models with More Parameters and Tokens
By
–
shameless plug, training better (more parameters or more tokens) vec2text models would also be nice
-
Tokenization-Free Transformers: Scaling Breakthrough Research Idea
By
–
machine learning research question:
what’s an idea that you think would catch on, if only someone spent the money to test it at scale? i’ll go first: tokenization-free transformers -
Fixed Embedding Spaces and Conditional Generation in AI Models
By
–
thankful twitter hasn't implemented a peer review process yet unlike latent diffusion, in this case the embedding space is fixed (it's openAI ada 2 in my notebook) I think this is kind of like conditional generation
-
Probabilistic Models and Text Embeddings: Learning p(e)
By
–
for sure, the probabilistic breakdown is the same: given text sequence x and its embedding e, p(x) = p(x | e) p(e). this looks a lot like a latent variable model with latent embedding e in my case p(x | e) is done by vec2text with openAI embeddings; we just need to learn p(e)
-
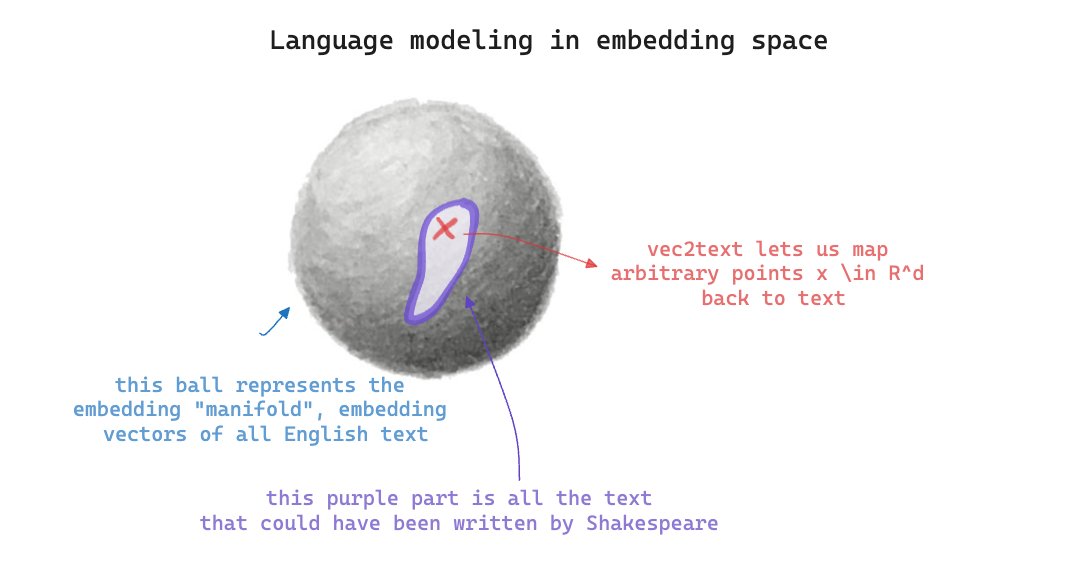
Language Model Fine-Tuning in Embedding Space
By
–
fun idea I tested out this morning: Language model fine-tuning in embedding space here's the idea: learn a model of *embeddings* of a certain text distribution; then, to generate text, sample embedding and map back to text with vec2text this lets us generate language without
-
BPE Tokenization Dies: 2024 Marks Major Transformer Evolution
By
–
i can see it now: 2024 will be remembered as the year BPE died tokenization is by far the clunkiest part of a transformer; one last remaining bit of inelegance in an otherwise hyperoptimized model architecture time for it to go
-
What Data Can Google Not Access?
By
–
I also think it must be data, but can’t fathom what type of data it is that GOOGLE can’t get their hands on…
-
Training costs create single shot constraint for AI models
By
–
honestly this is plausible — as @yuntiandeng pointed out to me, when training costs millions, you really only get one try
