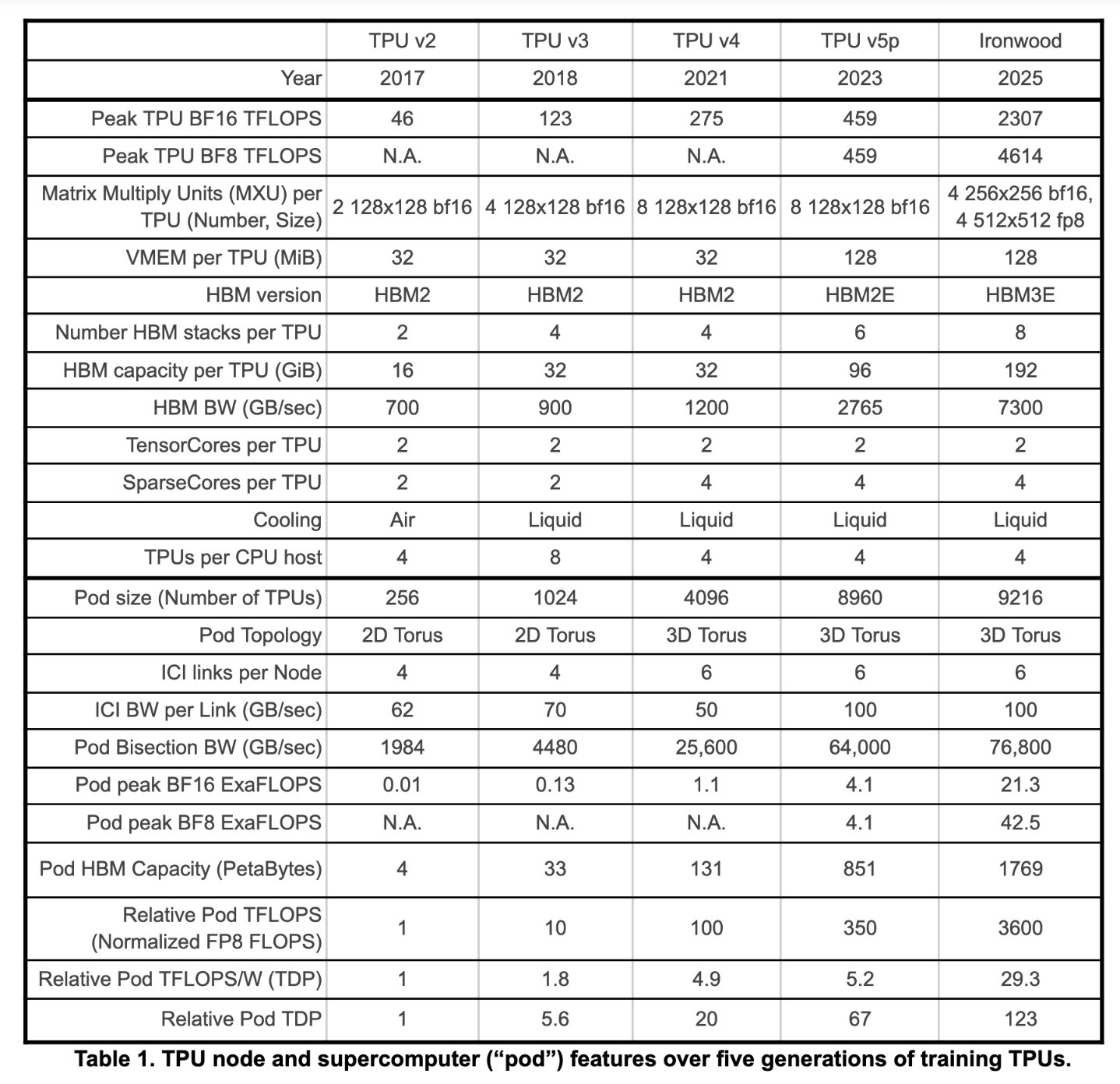
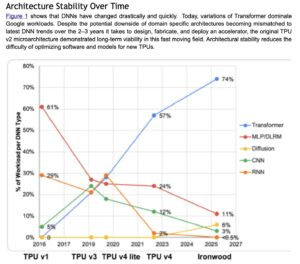
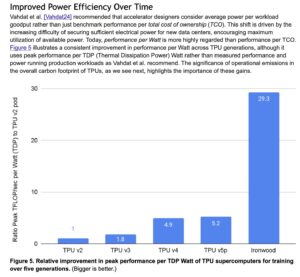
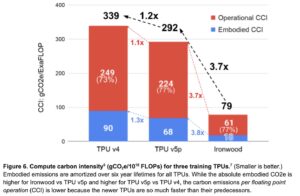
My colleagues at @Google, @NormJouppi, Sridhar Lakshmanamurthy, Cliff Young and David Patterson, recently wrote an article that will appear in the July/August 2026 issue of @ieeemicro, titled "Google's Training Supercomputers from TPU v2 to Ironwood: Architectural